
【NLP】一种好用的树结构:Trie树
Trie树简介
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
Trie这个术语来自于retrieval。根据词源学,trie的发明者Edward Fredkin把它读作/ˈtriː/ "tree"。但是,其他作者把它读作/ˈtraɪ/ "try"。
在图示中,键标注在节点中,值标注在节点之下。每一个完整的英文单词对应一个特定的整数。Trie可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含在分支的顺序中的。Eg.一个保存了8个单词的字典树的结构如下图所示,8个单词分别是:“A”,“to”,“tea”,“ted”,“ten”,“i” ,“in”,“inn”。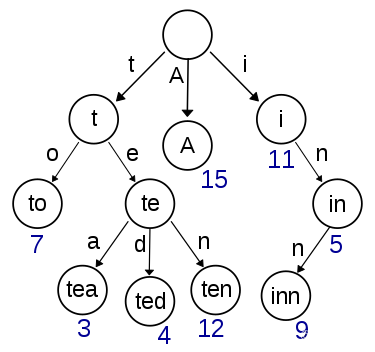
另外,单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
Trie树性质
它有3个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
基本操作
其基本操作有:查找、插入和删除,当然删除操作比较少见。
实现方法
搜索字典项目的方法为:
(1)从根结点开始一次搜索; (2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索; (3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。 (4) 迭代过程…… (5) 在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。其他操作类似处理
实现 Trie (前缀树)
关于Trie树实现,可以移步看下LeetCode208. 实现 Trie (前缀树)
输入
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/implement-trie-prefix-tree具体实现如下:
class TrieNode(object):
def __init__(self):
"""
Initialize your data structure here.
"""
self.data = {}
self.is_word = False
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = TrieNode()
def insert(self, word):
"""
Inserts a word into the trie.
:type word: str
:rtype: void
"""
node = self.root
for chars in word:
child = node.data.get(chars)
if not child:
node.data[chars] = TrieNode()
node = node.data[chars]
node.is_word = True
def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
:rtype: bool
"""
node = self.root
for chars in word:
node = node.data.get(chars)
if not node:
return False
return node.is_word # 判断单词是否是完整的存在在trie树中
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
:type prefix: str
:rtype: bool
"""
node = self.root
for chars in prefix:
node = node.data.get(chars)
if not node:
return False
return True
def get_start(self, prefix):
"""
Returns words started with prefix
返回以prefix开头的所有words
如果prefix是一个word,那么直接返回该prefix
:param prefix:
:return: words (list)
"""
def get_key(pre, pre_node):
word_list = []
if pre_node.is_word:
word_list.append(pre)
for x in pre_node.data.keys():
word_list.extend(get_key(pre + str(x), pre_node.data.get(x)))
return word_list
words = []
if not self.startsWith(prefix):
return words
if self.search(prefix):
words.append(prefix)
return words
node = self.root
for chars in prefix:
node = node.data.get(chars)
return get_key(prefix, node)
if __name__ == '__main__':
trie = Trie()
print('trie.insert("apple"):', trie.insert("apple"))
print('trie.insert("appal"):', trie.insert("appal"))
print('trie.insert("appear"):', trie.insert("appear"))
print('trie.insert("apply"):', trie.insert("apply"))
print('trie.insert("appulse"):', trie.insert("appulse"))
print('trie.search("apple"):', trie.search("apple")) # 返回 True
print('trie.search("app"):', trie.search("app")) # 返回 False
print('trie.startsWith("app"):', trie.startsWith("app")) # 返回 True
print('trie.insert("app"):', trie.insert("app"))
print('trie.search("app"):', trie.search("app"))
print('trie.search("app"):', trie.get_start("app"))
print('trie.search("ap"):', trie.get_start('ap'))结果输出如下:
F:\ProgramData\Anaconda3\python.exe F:/Projects/nlp-trie/main.py
trie.insert("apple"): None
trie.insert("appal"): None
trie.insert("appear"): None
trie.insert("apply"): None
trie.insert("appulse"): None
trie.search("apple"): True
trie.search("app"): False
trie.startsWith("app"): True
trie.insert("app"): None
trie.search("app"): True
trie.search("app"): ['app']
trie.search("ap"): ['app', 'apple', 'apply', 'appal', 'appear', 'appulse']
Process finished with exit code 0应用
输入框提示/自动补全:trie 常用于搜索提示。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。 字符串检索、模糊匹配 文本预测、自动完成,see also,拼写检查 在NLP中的应用,主要有基于字典树的文本分词、短语提取、实体提取等
优缺点
优点:
可以最大限度地减少无谓的字符串比较,故可以用于词频统计和大量字符串排序。跟哈希表比较:
最坏情况时间复杂度比hash表好
没有冲突,除非一个key对应多个值(除key外的其他信息)
自带排序功能(类似Radix Sort),中序遍历trie可以得到排序。
缺点:
虽然不同单词共享前缀,但其实trie是一个以空间换时间的算法。其每一个字符都可能包含至多字符集大小数目的指针。
如果数据存储在外部存储器等较慢位置,Trie会较hash速度慢(hash访问O(1)次外存,Trie访问O(树高))。
长的浮点数等会让链变得很长。可用bitwise trie改进。
时间复杂度
时间复杂度:创建时间复杂度为O(L),查询时间复杂度是O(logL),查询时间复杂度最坏情况下是O(L),L是字符串的长度。
参考资料
字典树 百度百科 Trie wikipedia Trie Python实现 Trie树学习及python实现 python 实现 trie(字典) 树 Trie树(字典树)详细知识点及其应用
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: