
熵
"聊聊熵"

AI-CODE | 作者 / AI-code
这是人类之奴公众号的第58篇原创文章

"熵"在多个学科中都是一个非常重要的概率,今天我们要探讨的是信息论中的"熵"。
在探讨"熵"之前,我们先来了解一些预备知识点:
"信息","信息量"
"信息"的一种科学性定义为:信息是被消除的不确定性。
"太阳从东方升起",这就不是一条信息。
因为"太阳从东方升起"这是人皆尽知的一件事,它并没有消除不确定性。
但判断一句话是否传达了信息,这也是一个人类主观看待的一个问题。
"太阳是太阳系的中心"对于我们当代人来说不是一条信息。
但对于哥白尼时代及其以前时代的人来说,却是信息量巨大的一句话。
要将"信息"这个科学概率运用于计算机科学中,就必须寻找到一种非常合适的信息量化指标,因为计算机科学是一门数字科学。
"信息量"就是对"信息"数量大小的衡量指标,它的数学表达式为:
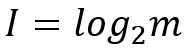
其中m为可能情况的数量,比如中国乒乓球队与日本乒乓球队进行比赛,那么比赛的结果就只有两种情况:中国乒乓球队胜、日本乒乓球队胜。
该事件对应的m便为2,带入上式可知该事件的信息量为1,单位为比特。
判断一个数学表达式的好坏,可以通过实例来看它是否符合我们的直觉。
对于中国乒乓球队与日本乒乓球队的比赛,我们的直觉告诉我们中国乒乓球队战胜日本乒乓球队是毫无悬念的,而信息量又是指消除不确定性的定量衡量,所以这不应该是信息量为0吗?
这种质疑是合理的,上述信息量的表达式只有在所有可能发生事件的发生可能性均等的情况下使用才是最合适的。
日常生活中极少发生的事件一旦发生,是非常引人注目的;而司空见惯的事件却很少人会去关注。
因此,极少见事件携带的信息量巨大,即事物出现的概率越小,信息量越大;事物出现的概率越大,信息量越小。
因此,信息量用下式来计算更合适:
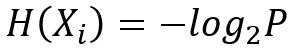
上式P表示事件Xi发生的先验概率,所谓先验概率,就是这个事件按照常理,按照一般性规律发生的概率。
在掌握了"信息"、"信息量"这两个概率后,我们再来揭秘"熵"。
"熵"在信息科学中可以表达为信息杂乱程度的量化描述,其数学表达式为:
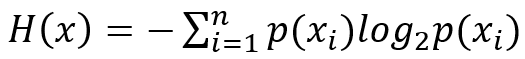
从上述表达式,我们发现"熵"为各个事件发生的概率乘以各自的信息量,然后各项加和。
通过计算,我们发现熵具有以下规律:
信息越确定、越单一,熵越小;
信息越不确定、越混乱,熵越大。
对于"熵"计算机科学中的运用,我们要把握住"熵是度量信息混乱程度的量"这句话。
