3月31日,2020年图灵奖重磅出炉,颁给了哥伦比亚大学计算机科学名誉教授 Alfred Vaino Aho 和斯坦福大学计算机科学名誉教授 Jeffrey David Ullman。 Jeff Ullman 是数据科学领域的巨擘,他的研究兴趣包括数据库理论、数据库集成、数据挖掘等。在去年撰写的一篇评论文章中,他用浅显的语言重新定义了,统计学、数据科学和机器学习之间的交叉点,并破除了其中的误读。他认为,尽管机器学习非常重要,但它远非实现有效数据科学所需的唯一工具。 「我并不认为机器学习可以完全取代数据库社区开发的算法。」
01
Have we missed the boat again? 多年来,数据库领域有一种言论认为,数据库系统正在变得无关紧要。大家似乎持一种绝望的心态。“have we missed the boat-again”这句话,在数据库社区里似乎司空见惯[8]。 但我想论证,数据库以及由数据库研究而产生的技术,对于“数据科学”仍然是必不可少的,特别是在解决科学、商业、医学等应用领域的重要问题上。数据库系统的核心,一直是如何尽最大可能处理最大的数据量,无论是以MB为单位的企业工资单数据、TB为单位的基因组信息,还是PB为单位的的卫星输出信息。因此,数据库的工作就是:研究一切相关数据。 为了论证这一观点,我主要回答三个问题:1. 统计真的是数据科学的重要组成部分吗?2. 机器学习就是数据科学的全部吗?3. 数据科学是否会对社会规范构成威胁? 我对这三个问题的回答都是“no”。我将试着依次回答这三个问题。
02
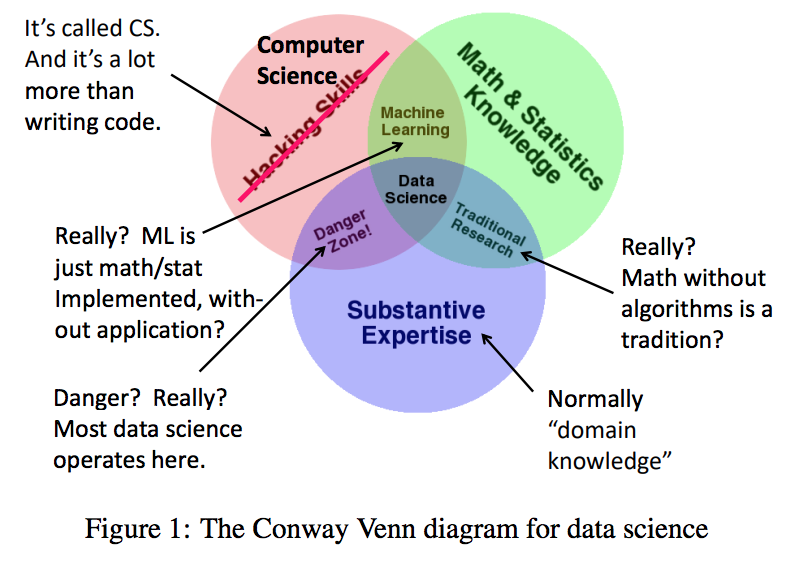
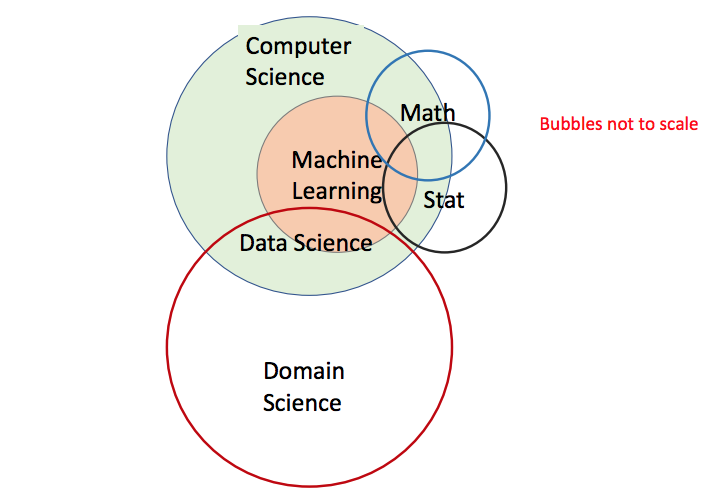
数据科学 vs. 统计学:谁是谁的子集? 几年前,我受邀参加了国家研究委员会(NRC)一个叫做“数据-科学-教育圆桌会议”的小组(详见 [16])。这个圆桌不是由 NRC 的计算机科学部门组织的,而是由统计部门组织的。参与者中,统计学家和计算机科学家的数量差不多,加上其他学科的一些人。当时的收获主要是看统计学家如何思考这个数据的世界及其应用。最明显的一点是,统计学领域将数据科学视为自己的领域。公平地讲,首先让我们明确一点,我非常尊重统计学家和他们所做的工作。统计学在现代数据研究中变得越来越重要,包括但不限于机器学习。许多统计学家开始像数据库界或者更其他计算机科学界那样,关注计算和数据分析。仅举一个小例子,我最喜欢的技术之一是局部敏感哈希算法(LSH),这是一个直接来源于数据库社区的想法。然而,我在斯坦福大学统计部门的一位同事 Art Owen 向我展示了关键步骤——最小哈希(minhashing),这一步骤很大程度上加速了这个过程——这是我们几年前就应该能够弄清楚的,但是没有弄清楚。然而,我在圆桌会议上的经验也让我感觉到,统计界的一些人正在努力将统计定义为数据科学的核心组成部分。相比之下,我更倾向于把高效处理大规模数据的算法和技术视为数据科学的中心。人们普遍认为,数据科学是一门结合了多个领域知识的学科,我对此完全赞同。但这些领域究竟是什么,它们又是如何相互作用的呢?这个问题如此重要,以至于不同社区纷纷发表维恩图来证明他们自己在数据科学中的中心地位。最近有一篇文章[10]对这些图表进行了总结和评论。其他维恩图表示相关的所有观点,请查询维基百科数据科学维恩图。
有一种对数据使用的指责是,由数据产生的系统反映了说话者所反对的社会的某些东西。这种误读的一个明显例子涉及 Word2Vec [13] ,这是谷歌几年前开发的一个系统(后来被BERT所取代) ,该系统将单词嵌入到高维向量空间中,从而使具有相似意义的单词具有相近的向量。直观的想法是看看通常围绕在单词 w 周围的单词。那么 w 的向量就是与其周围关联单词的方向的加权组合。例如,我们预期「可口可乐」和「百事可乐」有相似的向量,因为人们谈论它们的方式大致相同。当观察到某些向量方程的规律时,问题就出现了,例如作为向量,London − England + France = Paris也就是说,伦敦和巴黎,作为各自国家的首都和最大的城市,周围有许多反映这种地位的词汇。我们预期伦敦周围会有更多与英格兰有关的词汇,所以把它们拿走,代之以与法国有关的词汇。这个观察结果无关紧要,但是其他方程式引起了一些严重的争议,例如,doctor − man + woman = nurse这个方程式,它是在要求“给我找一个像医生一样的职业词汇,但要更倾向于女性。”。大约50% 的医生是女性,但接近90% 的护士是女性。我们希望医生和护士这两个词是相似的,但是后者更多地出现在「她」这样的词附近。所以这个等式是有一定道理的。这些负面例子真正反映的是,在这个社会中,女性更有可能和护理岗位联系到一起。我同意,很可能在不远的将来,情况会变化。但我的观点是: 不要责怪数据。像 Word2Vec 或者 BERT 这样的系统,当在一个像维基百科这样的大型语料库上训练时,将会反映出广大公众使用的语言,而这种数据的使用又会反映出人们普遍认为是真实的东西,不管我们是否喜欢这个真实。
The Last Word
我希望读者可以吸收到以下想法:•数据及其管理仍然是数据科学的本质。•尽管机器学习非常重要,但它远非实现有效数据科学所需的唯一工具或想法。•尽管数据有误用的情况,但如果数据反映的是世界的本来面目,而不是我们希望的那样,我们就不应该责怪数据本身。 原文链接:http://sites.computer.org/debull/A20june/p8.pdf 参考文献:[1] R. Agrawal, T. Imielinski, and A. Swami, “Mining associations between sets of items in massive databases,” Proc. ACM SIGMOD Intl. Conf. on Management of Data, pp. 207–216, 1993. [2] R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” Intl. Conf. on Very Large Databases, pp. 487–499, 1994. [3] T. Bolukbasi, K.-W. Chang, J. Zou, V. Saligrama, and A. Kalai, “Man is to computer programmer as woman is to homemaker? Debiasing word embeddings,” 30th Conference on Neural Information Processing Systems, Barcelona, 2016. [4] A.Z. Broder, M. Charikar, A.M. Frieze, and M. Mitzenmacher, “Min-wise independent permutations,” ACM Symposium on Theory of Computing, pp. 327–336, 1998. [5] T. Buonocore, “Man is to doctor as woman is to nurse: the gender bias of word embeddings,” https://towardsdatascience.com/gender-bias-word-embeddings-76d9806a0e17 [6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv:1810.04805, 2018. [7] A. Gionis, P. Indyk, and R. Motwani, “Similarity search in high dimensions via hashing,” Proc. Intl. Conf. on Very Large Databases, pp. 518–529, 1999. [8] B. Howe, M.J. Franklin, L.M. Haas, T. Kraska, and J.D. Ullman: “Data science education: we’re missing the boat, again,” ICDE, pp. 1473–1474, 2017. [9] https://www.kaggle.com/ [10] https://www.kdnuggets.com/2016/10/battle-data-science-venn-diagrams.html [11] J. Leskovec, A. Rajaraman, and J.D.Ullman, Mining of Massive Datasets 3rd edition, Cambridge Univ. Press, 2020. Available for download at http://www.mmds.org[12] P. Li, A.B. Owen, and C.H. Zhang. “One permutation hashing,” Conf. on Neural Information Processing Systems 2012, pp. 3122–3130. [13] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” ArXiv:1301.3781, 2013. [14] https://www.nationalacademies.org/event/10-20-2017/docs/DCE05D1E271C31C585455B25E43AE9E5462ED3312DB2 [15] https://www.nationalacademies.org/event/12-08-2017/docs/D8EE65EFC7F4B0C368D267EDAD10E5AB1BAFBE3369D2 [16] https://www.nationalacademies.org/our-work/roundtable-on-data-science-postsecondary-education [17] https://en.wikipedia.org/wiki/Right to explanation