
20B量级大模型性能媲美Llama2-70B!完全开源,从基座到工具全安排明白了

新智元报道
新智元报道
编辑:编辑部
【新智元导读】国产模型开源纪录,又被刷新了!上海AI实验室等机构开源的InternLM-20B,竟然能和Llama2-70B打个平手?
就在刚刚,国内开源模型参数量纪录,又被刷新了!
9月20日,上海人工智能实验室(上海AI实验室)与商汤科技联合香港中文大学和复旦大学,正式开源了200亿参数的InternLM-20B模型。
项目地址:https://github.com/InternLM/InternLM
魔搭社区:https://modelscope.cn/organization/Shanghai_AI_Laboratory
这次的200亿参数版书生·浦语大模型,可以说是「加量不加价」,参数量还不到三分之一,性能却可以剑挑当今开源模型的标杆——Llama2-70B。而当前主流的开源13B模型们,则在所有维度上都被InternLM-20B甩在身后。
不仅如此,面向大模型研发与应用的全链条工具体系也同时升级。
从开源模型本身,再到全链条的开源工具,这一次,上海AI实验室把自身研发大模型所沉淀的压箱底的宝藏,全都拿了出来,希望帮助广大研究者、机构、社会从业者,都能以极低成本和门槛,参与大模型带来的这场技术革命。

性能「同级领先」,门槛「开箱即用」,InternLM-20B,就是大模型走向千行百业的催化剂和新支点!
这股大模型的浪潮,将惠及每个人。
我们用的,全部开源
众所周知,在大模型的整个研发体系中,有串在一起的多个环节,这是十分复杂的一套闭环。
如何用更规范的代码方式去组织?拿到基座模型该怎么用?落地到应用的一步步过程中,有哪些注意事项?到处都是问题。
在经过日常工作中真正的实践后,上海AI实验室的团队沉淀出来一套宝贵经验。
现在,他们为了繁荣开源生态,干脆把模型从数据准备,到预训练、部署,再到评测应用,这整套流程中会涉及到的工具,全部开源了。
解密「独家配方」
数据,之于大模型重要性,就好比生产的原材料,没有动力来源,无法驱动智能AI系统运转。尤其,高质量的数据更是大模型产业化的关键要素之一。
在收集上,不仅需要有效地过滤和清洗从网页、书籍、专业报告论文等各种渠道中爬取的原始素材,还需要充分利用模型内测用户提供的反馈。
不过,要想让LLM能够获取关键能力,比如理解、编程、逻辑推理,成为真正的「六边形战士」,更重要的是自己去构建数据。
在这一方面,学术界的研究也是非常活跃,比如微软「Textbooks Are All You Need」,通过构建数据训练后的模型phi-1,能够在基准上取得相对领先优势。

就上海AI实验室团队来说,他们没有选择从单点方向去构建数据,而是从「全维度」,对整个知识体系梳理后构建语料。
因此,这些语料在知识和逻辑的密度上,是非常高的。
在大量的常规内容中加入少量的「催化剂」,不仅可以更好地激发出LLM的关键能力,而且模型对于相关信息的吸收和理解也会更强。
用上海AI实验室领军科学家林达华的话来说,「从某种意义上来说,这里的1个token,可以等同于10个,甚至100个传统token的效力」。
就算力方面,除了互联网大厂坐拥着丰富的资源外,开源社区大部分的开发者很难获取更多的算力。
「希望能够有轻量级的工具,能够把模型用起来」。这是上海AI实验室收到最多的社区反馈。
通过开源XTuner轻量级微调工具,用户可以在8GB消费级GPU上,用自己的数据就能微调上海AI实验室开源的模型。
此外,在模型应用方向上,「聊天对话」依旧是模型非常重要的能力的一部分。
上海AI实验室还想突出一点是,大模型作为中央Hub,使用工具解决问题,类似于Code Interpreter的方式去调用工具。
同时,在这个过程中,大模型还能进行自我反思,这便是LLM加持下智能体展现的巨大潜力。
林达华认为,Agent会是一个长期发展非常有价值的需要去探索的方向。
最终智能体的世界,整个组织分工也会在不断的升级和演进,未来肯定是非常多的智能体的共同存在,有各自擅长的领域,相互之间会有很多技术能够促进它们之间的交流。
那么,此次工具链具体升级的地方在何处?
- 数据:OpenDataLab开源「书生·万卷」预训练语料
数据上,书生·万卷1.0多模态训练语料8月14日正式开源,数据总量超总量超过2TB,包含了文本数据集、图文数据集、视频数据集三部分。
通过对高质量语料的「消化」,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
截止目前,已经有近10万的下载量。

- 预训练:InternLM高效预训练框架
预训练阶段,InternLM仓库也开源了预训练框架InternLM-Train。
一方面,深度整合了Transformer模型算子,使得训练效率得到提升,另一方面则提出了独特的Hybrid Zero技术,实现了计算和通信的高效重叠,训练过程中的跨节点通信流量大大降低。
得益于极致的性能优化,这套开源体系实现了千卡并行计算的高效率,训练性能达到了行业领先水平。
- 微调:InternLM全参数微调、XTuner轻量级微调
低成本大模型微调工具箱XTuner也在近期开源,支持了Llama等多种开源大模型,以及LoRA、QLoRA等微调算法。
硬件要求上,XTuner最低只需8GB显存,就可以对7B模型进行低成本微调,20B模型的微调也能在24G显存的消费级显卡上完成。
XTuner为各类开源模型提供了多样的微调框架
- 部署:LMDeploy支持十亿到千亿参数语言模型的高效推理
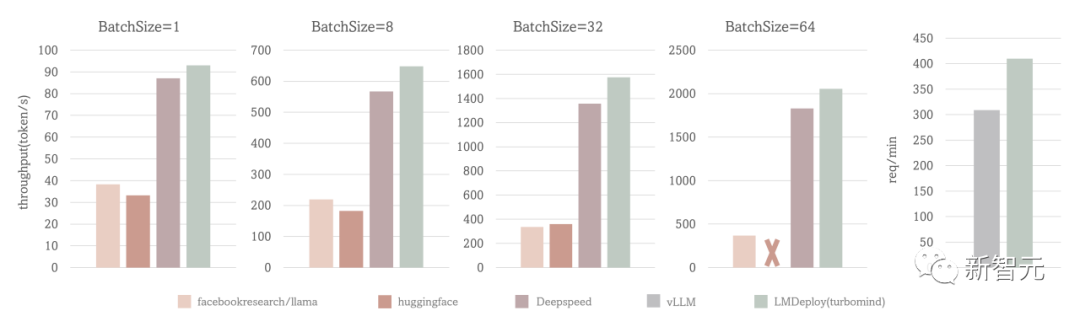
部署方面,LMDeploy涵盖了大模型的全套轻量化、推理部署和服务解决方案。
它支持了从十亿到千亿参数的高效模型推理,在吞吐量等性能上超过了社区主流开源项目FasterTransformer,vLLM,Deepspeed等。
- 评测:OpenCompass一站式、全方位大模型评测平台
评测部分,开源的大模型评测平台OpenCompass提供了学科、语言、知识、理解、推理五大维度的评测体系。
同时,它还支持50+评测数据集、30万道评测题目,支持零样本、小样本及思维链评测,是目前最全面的开源评测平台。

- 应用:Lagent轻量灵活的智能体框架
在最后的应用环节,上海AI实验室团队将重点放在了智能体上,开发并开源了Lagent轻量灵活的智能体框架。
它能够支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供典型工具为大语言模型赋能。
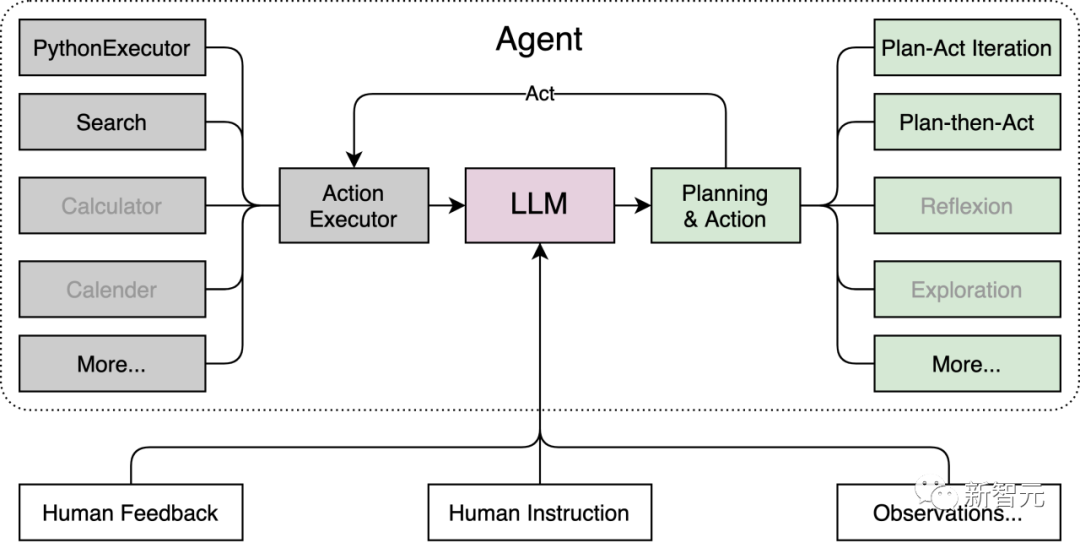
这套开源框架集合了多种类型的智能体能力,包括经典的ReAct、AutoGPT和ReWoo等。
这个框架的代码结构不仅清晰,而且简单。只用不到20行代码,开发者就能创建一个属于自己的智能体。
另外,Lagent支持包括InternLM,Llama,ChatGPT在内的多个大模型。
在Lagent加持下,这些智能体能够调用大语言模型进行规划推理和工具调用,并在执行过程中及时进行反思和自我修正。
国内首发16k上下文,200亿参数打平Llama2-70B
除了全套的大模型工具链外,上海AI实验室还全新开源了高达200亿参数的InternLM-20B。
评测结果显示,在同量级开源模型中,InternLM-20B是当之无愧的综合性能最优。

- 超长上下文支持
首先,在语境长度上,InternLM-20B可以支持高达16K的上下文窗口。
如下图所示,InternLM-20B阅读了某知名咖啡品牌的长新闻后,能够对三个提问做出准确回答。

对于超级长篇的论文和报告,InternLM-20B也能准确地提取摘要。
比如,输入经典的ResNet论文后,它立马写出了摘要,准确概括了ResNet的核心思想和实验效果。

- 调用工具,自学成才
其次,在长语境的支持下,模型的能力被大大拓展,无论是工具调用、代码解释,还是反思修正,都有了更大的空间。而这也成了在InternLM-20B之上打造智能体的关键技术。
现在,InternLM-20B不仅可以支持日期、天气、旅行、体育等数十个方向的内容输出,以及上万个不同的API,而且还能过类似Code Interpreter的方式去进行工具的调用。
与此同时,在这个过程中,它还能进行反思修正,跟现实场景产生联系。
在清华等机构联合发布的大模型工具调用评测集ToolBench中,InternLM-20B和ChatGPT相比,达到了63.5%的胜率,在该榜单上取得了最优结果。
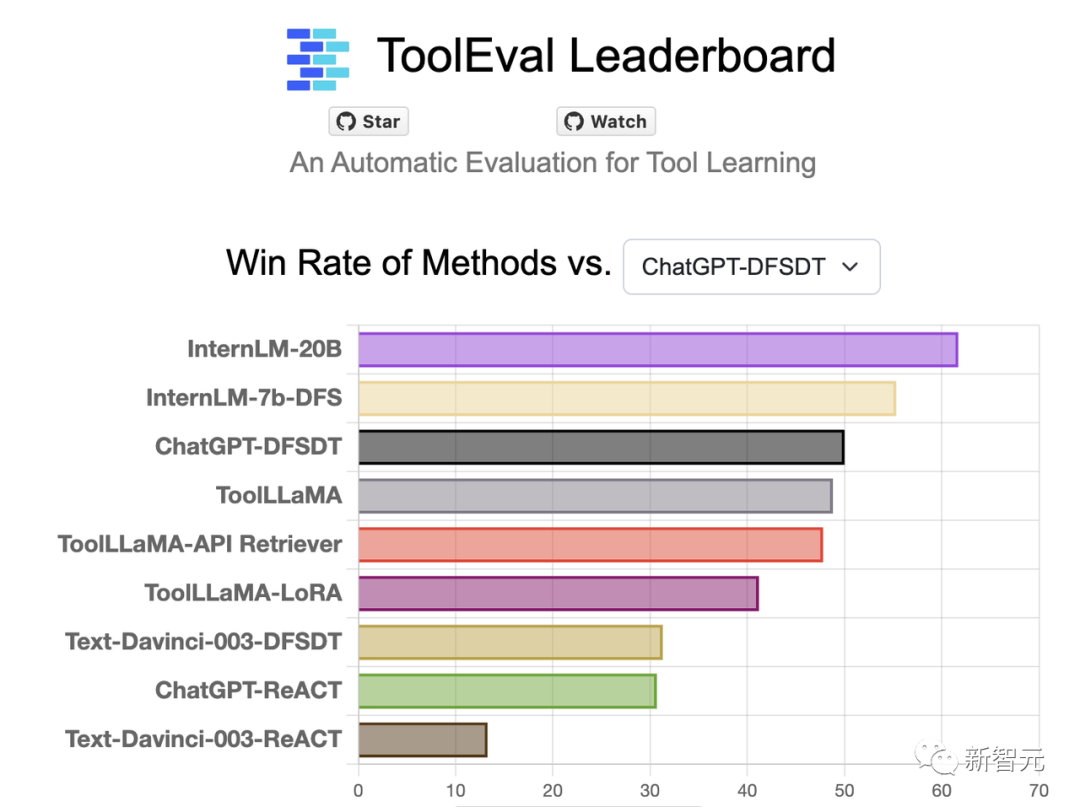
而且,InternLM-20B模型还展现出一定的零样本泛化能力。即使模型在训练过程中并没有学过一些工具,它竟然也能根据工具描述和用户提问来调用工具。
如下图所示,给它提供一些AI工具,它就可以自己进行规划和推理,完成用户问题。
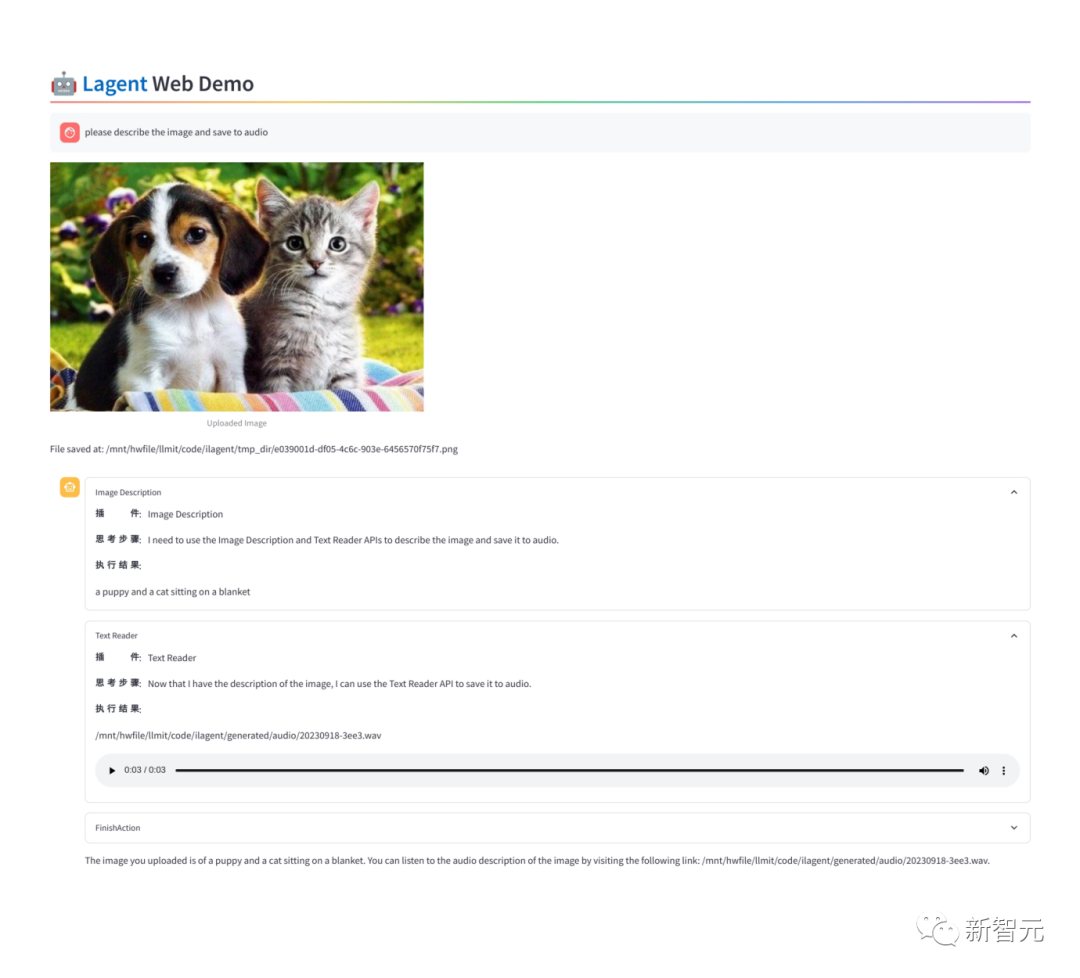
- 同量级全面领先
在多达50款各个维度的主流评测集上,InternLM-20B也一举实现了同量级开源模型的综合性能最优。
与此同时,在平均成绩上也明显超越了规模更大的Llama-33B,甚至在部分评测中还能小胜Llama2-70B。
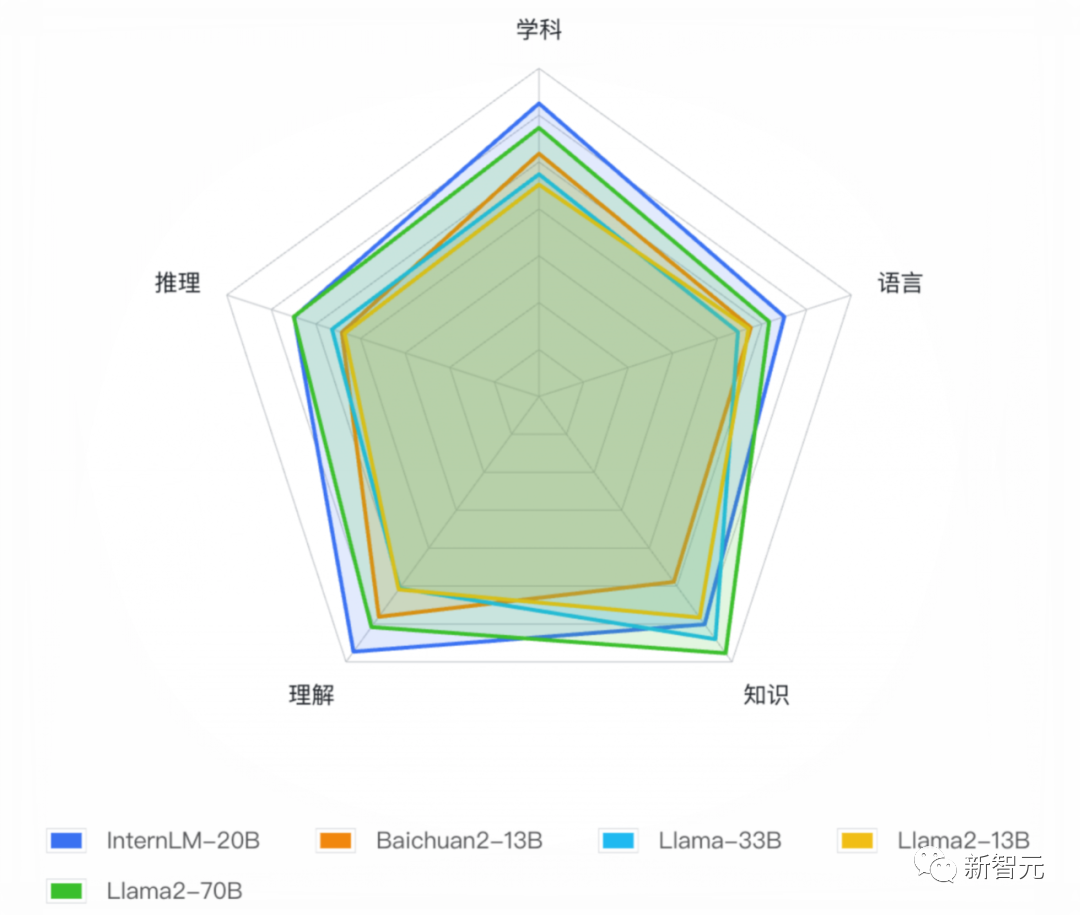
具体来说,InternLM-20B在MMLU、C-Eval、AGIEval综合性学科评测中成绩优异,在同量级开源模型中处于领先位置。
尤其是在包含中文学科考试的C-Eval和AGIEval上,表现明显超过了Llama2-70B。

在考验事实性知识的评测上,InternLM-20B全面超越了13B模型,并且能与Llama-33B一较高下。
但相比于Llama-65B或者Llama2-70B仍有一定差距。

在理解能力维度,InternLM-20B的表现更是突出,全面超越了包括Llama2-70B在内的各量级开源模型。
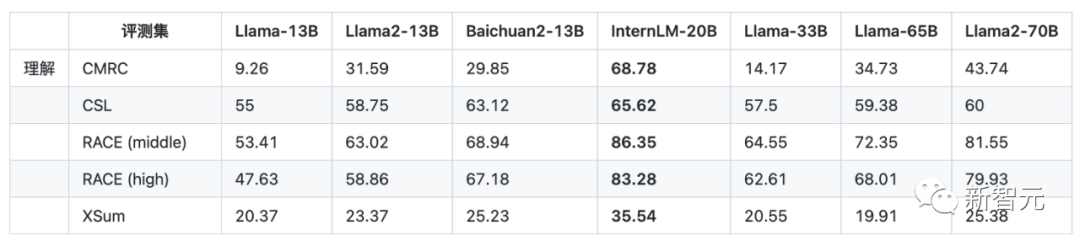
推理,是考倒了不少模型的「拦路虎」,考验的是大模型真金白银的本事,也很大程度上决定了模型是否能支撑实际应用。
在下述四个推理测评集上,InternLM-20B的成绩均超越了主流的13B开源模型,甚至已经接近了Llama-65B的推理能力。

编程能力上,InternLM-20B也有了显著提升。在HumanEval和MBPP两个典型评测集上,接近了Llama2-70B。

注:上述截图中的粗体为13B-33B量级范围内,各项最佳成绩。
在HuggingFace最新公布的Open LLM Leaderboard评测榜单上,InternLM-20B在参数量60B以下基模型中平均成绩领先,也超过了Llama-65B。

- 更安全的开源模型
最后,在价值对齐上,InternLM-20B也更加完善、更为安全。
如果你向它提出带有偏见的问题,它就会立马识别出其中的不安全因素,给出正确的价值引导。

大模型,从来都不是大厂的专利
大模型浪潮掀起后,我们需要关注的,不仅仅是在测评榜单上拔得头筹,还有如何让大模型从「AI皇冠上的明珠」,成为千行百业都可用的「全新生产力」。
纵观历史,真正引领时代的技术,不只是颠覆性的创新,更重要的,是做到低成本、低门槛、人人可用。但OpenAI、谷歌这样的大厂是绝对不会把其中具体的细节公之于众。
而这,正是上海AI实验室的初心之所在。
自6月首发以来,书生·浦语已经完成了多轮升级,在开源社区和产业界产生了广泛影响。

而且,除了把代码在GitHub上开放、把模型放在HuggingFace和魔搭社区,上海AI实验室甚至每天都会派专人去看社区里的反馈,对用户提问悉心解答。
此前,Meta的LLaMA模型开源,引爆了ChatGPT平替狂潮,让文本大模型迎来了Stable Diffustion时刻。
就如同今天羊驼家族的繁荣生态,上海AI实验室的开源努力,必将给社区带来不可估量的价值。

对于全球范围内活跃的开发者和研究者,书生·浦语会提供一个体量适中、但能力非常强的基座。
大部分企业,尤其是中小企业,虽然看到了大模型的趋势,但是不太可能像大厂一样花很大代价去购买算力,并且吸引最顶尖的人才。
实际上,从7月6号的人工智能大会开始,上海AI实验室就已经在做全链条地做开源。比如XTuner能以非常轻量级的方式,让用户只用自己的一些数据,就能训出自己的模型。

不仅如此,一个团队把开源社区的问题、语料、文档和XTuner模型结合,训练出了一个开源社区客服。这就是对开源社区实打实的贡献。
甚至,上海AI实验室把自己的整个技术体系,都分享给了社区(也就是上文提到的全链条工具体系)。

全社会如此多的行业,如此多的企业,如此多的机构和研发者,如果能实实在在把大模型的价值落地,将是非常重要的力量。
他们拥有无穷的创造力,唯一缺的就是资源。
而上海AI实验室的「雪中送炭」,必然会让大模型在落地领域发挥出巨大的价值。
正如林达华所言——
作为实验室,我们能提供基础模型以及将各行业的know-how融汇成数据、模型能力的一系列工具,并且将它们做得非常易用、教会更多人用,让它们能在各个行业里开花结果。
全链条工具体系开源链接
「书生·万卷」预训练语料:
https://github.com/opendatalab/WanJuan1.0
InternLM预训练框架:
https://github.com/InternLM/InternLM
XTuner微调工具箱:
https://github.com/InternLM/xtuner
LMDeploy推理工具链:
https://github.com/InternLM/lmdeploy
OpenCompas大模型评测平台:
https://github.com/open-compass/opencompass
Lagent智能体框架:
https://github.com/InternLM/lagent



评论