
吴恩达:AI的中心到底是模型还是数据?
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Dario Radecic,Medium 高质技术博主
编译:颂贤

图源:Brandon Lopez (Unsplash)
一般的AI课程会介绍很多如何通过参数优化来提高机器学习模型准确性的方法,然而这些方法通常都存在一定的局限性。这是因为我们常常忽视了现代机器学习一个非常重要的核心——数据。如果我们没有处理好训练数据没,上百个小时的时间都会被浪费在调整一个低质量数据训练出来的模型上,模型的准确度很容易就会低于预期,而这和模型调优是没有太大关系的。怎样才能避免这样的问题呢?
粗略地看,其实每个AI项目都由两部分组成:模型和数据。对于代码这部分,我们总能使用第三方库来尽可能地提高代码质量,但从来没有人告诉我们该如何充分提升数据的质量。这就是本文想要介绍的新思路:以数据为中心的AI。究竟什么是以数据为中心的AI?数据的数量与质量到底哪一个优先级更高?哪里可以找到好的数据集?这些问题本文都将带大家探讨。
什么是以数据为中心的AI?
既然AI由模型和数据两部分组成,那么我们可以想到有两种基本思路来指导我们的机器学习:
以模型为中心: 通过改进模型来提升表现
以数据为中心: 通过改进数据来提升表现
其实,以数据为中心的AI(data-centric AI)这一概念是吴恩达(Andrew Ng)的发明。吴恩达早前在油管上做了一次直播问答,专门讲解了什么是以数据为中心的AI。他提出,最近发表的学术论文中,99%都是在谈论模型,只有1%是以数据为中心的。其中有一句话特别值得注意:“别再花太多心思在模型优化上了”(your model architecture is good enough)。
吴恩达何出此言呢?ResNet, VGG, EfficientNet等学术界各路天才的种种智慧结晶,已经让我们现在能够接触到的模型架构变得非常强大了。试图再站在这些巨人的肩膀上改善她们的工作只能达到杯水车薪的效果。
不过,以模型为中心的思路的确更适合那些喜欢钻研理论的人,她们可以直接把手头的知识应用到具体场景中提升模型性能。而且,以数据为中心的思路听起来并不讨巧,谁会喜欢每天乐此不疲地给数据做标注呢?
然而事实证明,我们能做到的大部分性能提升都是通过以数据为中心的方法实现的。吴恩达在他的演讲中就展示了下面这组数据:
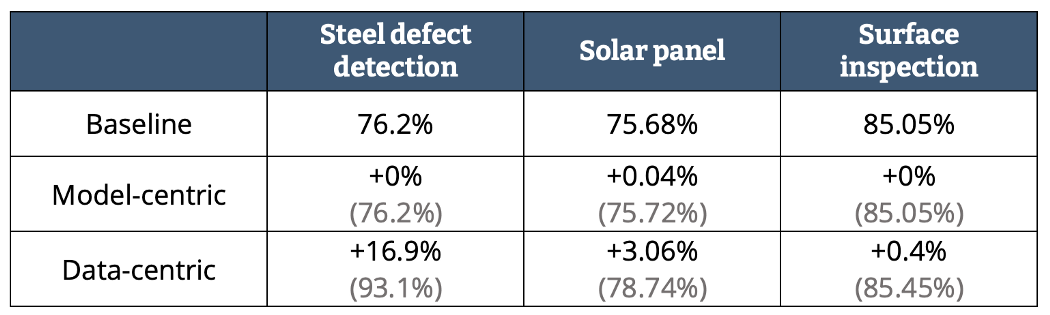
图1 — 基线、模型中心、数据中心性能比较(作者制图)
即使我们对钢铁缺陷这些事情没有什么了解,模型性能在数字上的显著提升我们是看得见的。我们可以看到,以模型为中心的方法对基线的改进不是零就是接近零,而且这种方法往往需要花费从业者数百小时的时间。
总结而言,我们可以得出一个很重要的经验教训:不要试图和一屋子的博士比智商。在想要改进模型之前,我们要首先确保手头上的数据质量是一流的。
数据要先保质还是保量?
要想追求数据的数量,通常的做法就是收集尽可能多的数据,并将其悉数扔给神经网络来学习映射关系。然而,一个数据集好用并不意味着它的数据量很大。我们可以参考数据集分享网站Kaggle上的数据集大小分布,图示如下:
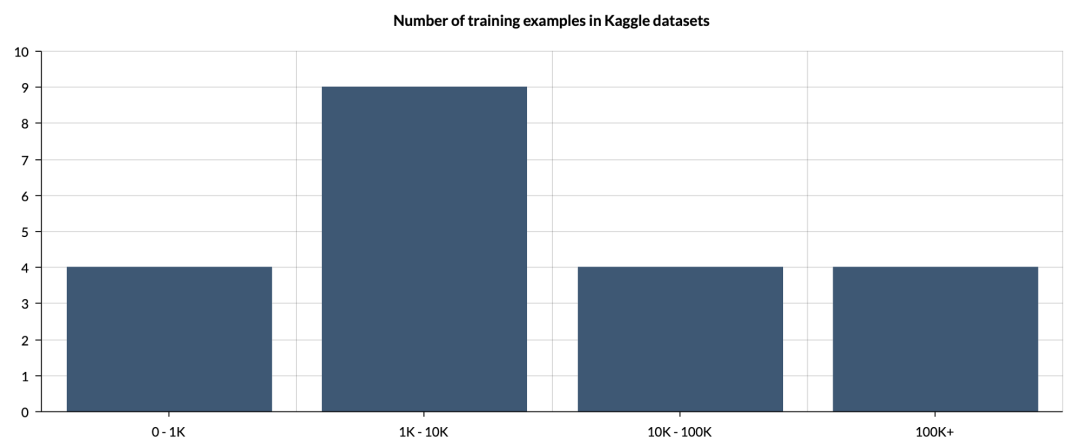
图2 — Kaggle上的数据集大小分布 (图源作者)
我们可以看到,大多数数据集并没有太多的数据。在以数据为中心的方法中,数据集的大小并不重要。当然,我们不可能用三张图片去训练神经网络,但我们的重点要放到质量上,而不是数量。就算我们没有成百上千的图片也没关系,已有的数据质量和标注准确度是至关重要的。我们可以参考下面的例子,下图是标注人员为两个橙子的位置做出的两种不同的标注方法。

图3 — 为物体检测任务标注边界的不同方法(图源作者)
想要让模型准确度下降很简单,只要给它灌入标注不一致的数据就可以了。如果要追求数据的质量,我们就必须有严格而统一的标注规则。项目同时有多家标注商时情况就更是如此。
不过,就算数据的质量能够保证,我们到底需要多少数据才算够呢?这个问题比你想象的要难回答。大多数算法在其文档中会标明一个最小的推荐数据量。例如,YOLOv5就建议每个类别至少有1500张图片。我本人曾经设法用比这更少的数据取得了很好的结果,但是如果有更多的训练样本,模型的准确性肯定会提高。
总结而言,拥有大量的数据能够如虎添翼,但数据的量绝不是必需品。小数据集只要能有较高的数据质量,我们就可以用较少的数据达到四两拨千斤的效果。
高质量数据集哪里找?
现在我们来看一下两个能够免费获取高质量数据集的平台。
Kaggle
Kaggle拥有大量包括图表和图像在内的数据集。同时,Kaggle经常会举办各种各样的机器学习竞赛,其中不乏现金奖励,非常适合那些想要展示自身技能的同学。不过,尽管Kaggle已经非常出名,它没有针对国内的网络进行优化,下载数据集并非易事。
图4 — Kaggle数据集主页
格物钛公开数据集平台
也许你没有听说过这个平台,不过它的出现确实给算法开发者们带来了极大的帮助,不论你身处国内还是国外。
在格物钛公开数据集平台(gas.graviti.cn/open-datasets),用户可以通过数据集的名称联想检索、应用场景筛选、标注类型筛选、推荐、更新时间及热度筛选,轻松找到所需数据集。同时,用户无需下载,即可在数据集详情页在线查看标注情况及标签分布,掌握数据细节。
不过,如果你想下载数据集至本地,格物钛用户提供高速稳定的下载服务。将全球资源Host至国内镜像,无需VPN访问,满带宽极速下载。与进入海外官网下载相比,格物钛至少提速100%。
简直是身处国内AI开发者的福音!
图5 — 格物钛公开数据集主页
事实上,格物钛平台上的数据集还在不断增长中,用户可以自发的上传一些开源数据集,其团队也会定期加入新的高质量公开数据集。例如,知名的自动驾驶数据集nuScenes就在平台上有所收录,并且有非常高效的在线可视化插件一键直观查看数据集内容:
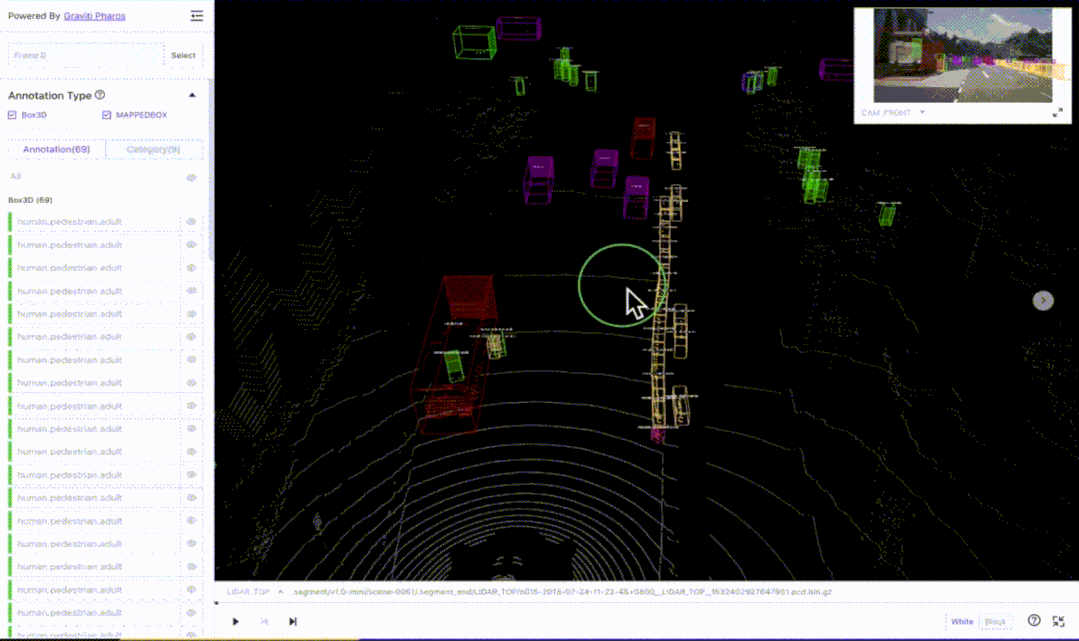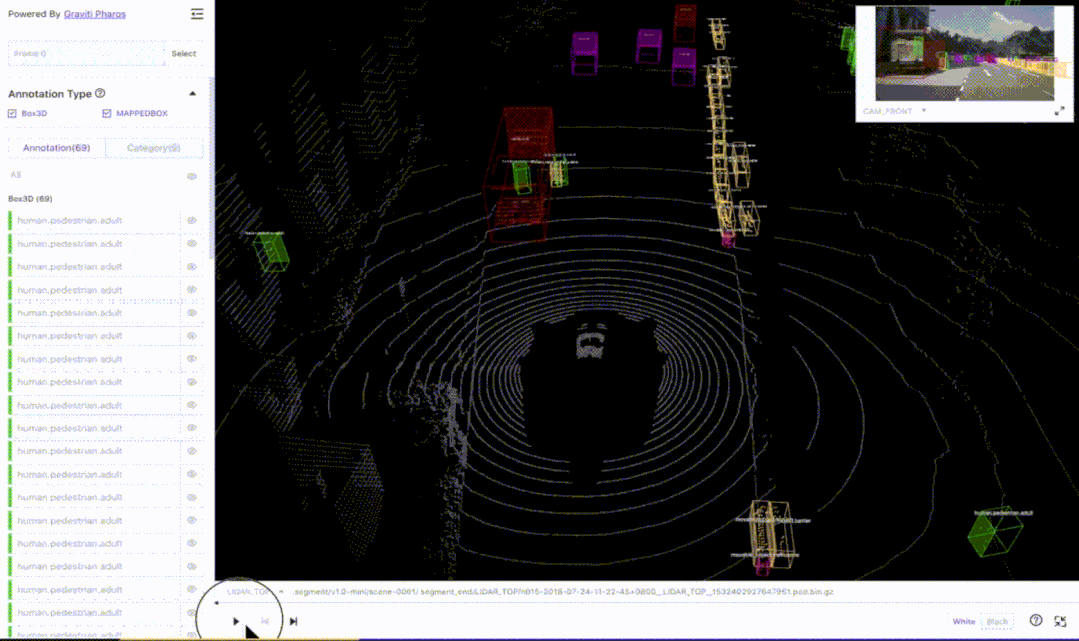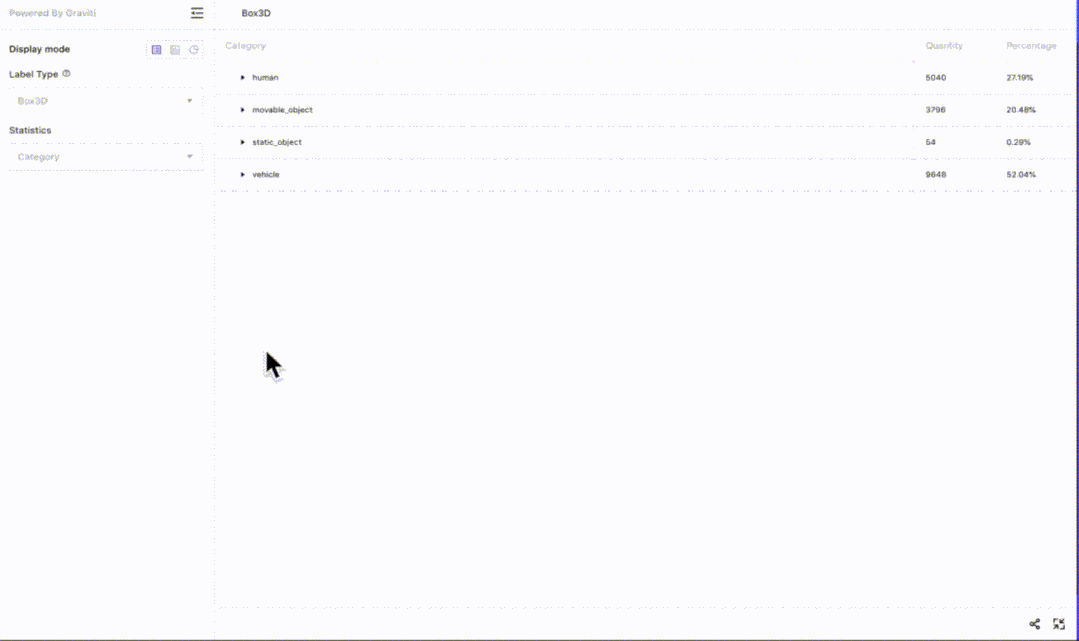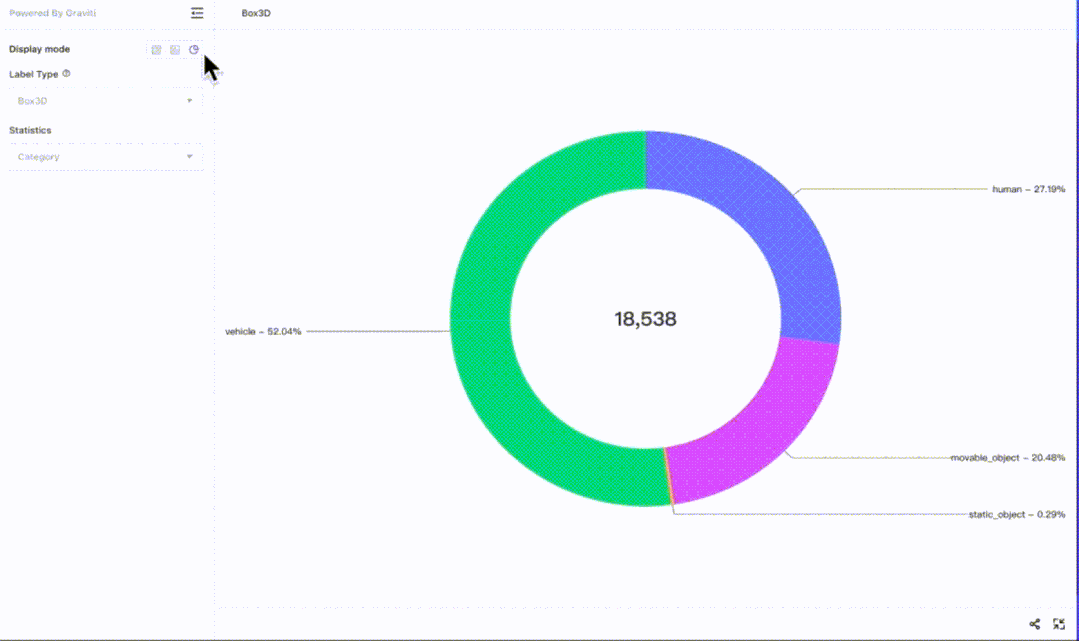
图6 — 格物钛平台上的nuScenes数据集
不仅如此,当你需要某些未被上传的特定数据集时,你可以加入格物钛社区(微信或Discord)。格物钛提供了问题与需求的反馈渠道,便于一对一针对性回应、跟进、解决用户的需求。
结语
以上就是对以数据为中心的AI的基本介绍。简单来说,以数据为中心的AI就是要更关心数据的质量而不是数量。然而,高质量的数据集是很难找到的。如果你想建立优质的机器学习模型,你就一定需要优质的数据集。对于接触数据集平台而言,Kaggle是一个很好的开始。但如果你对计算机视觉等具体领域感兴趣,并且想要以快捷高效的方式访问数据集,务必试试免费好用的格物钛公开数据集平台。
Open Datasets 👉
格物钛|公开数据集
graviti.cn/open-datasets
订阅号:格物钛 👉
微信号|Graviti_2019
微博|格物钛
https://www.graviti.cn/
点击阅读原文 / 访问格物钛官网