日前,吴恩达在圣诞节之际回顾了2020年AI的一些重大事件,包括AI应对新冠疫情、数据集存在种族偏见、对抗虚假信息算法、AlphaFold预测蛋白质三维结构、1750亿参数的GPT-3出现等等,并为大家送上节日祝福。亲爱的朋友们,在过去的十年中,每年我都会飞往新加坡或香港,与我的母亲一起庆祝她的12月22日的生日。今年,我们则是通过Zoom线上庆生。尽管距离遥远,但我仍然感到很高兴,我的家人们可以从美国,新加坡,香港,香港和新西兰一起线上聚会,并演唱同步性很差的“Happy Birthday To You”。
我希望我也可以和大家一起在Zoom上通话,以祝大家节日快乐,新年快乐!
节假日期间,我经常想一想重要的人,回顾他们为我或他人所做的事,并默默地表示我对他们的感谢。这使我感到与他们的联系更加紧密。
我觉得在我们远离社交的假期中思考这一点非常有价值:谁是您生活中最重要的人,您可能出于什么原因要感谢他们?无论是面对面的还是在线的,我都希望您能找到属于自己的方式——在这个假期里培养于最重要的人之间的关系。
2020年回顾

在过去一年,一种新的具有高度传染性的冠状病毒破坏了人们的正常生活,它所导致的社会裂痕也威胁到了我们的共同利益。
在这一年期间,有大量的机器学习工程师参与其中,设计了用于新冠肺炎(Covid-19)诊断和治疗的工具、建立了识别仇恨言论和虚假信息的模型,并指出和强调了整个AI社区偏见的存在。但是事情也有轻松的一面:这一年里可以将睡衣一键转换成西装的在家办公工具、GPT-3语言模型、在AI辅助艺术和表演方面的引人入胜的实验。接下来请就让我们一起探讨过去一年我们的艰辛和辉煌。1、AI加快了科学家对冠状病毒疫苗的搜寻,全球的机器学习研究人员争先恐后地利用AI技术来对抗冠状病毒。2、巴黎和戛纳市在公交车站、公共汽车和市场中使用计算机视觉评估了法规的遵守情况。3、多哥政府训练一个模型以识别卫星图像中的贫困地区,然后使用模型的输出指导将救济金分配给最需要的人。 摄影:环球影业集团/阿拉米4、聊天机器人提供了合成的虚拟朋友,供被疫情封锁的人们孤独时聊天和调情。5、对于在家工作的人们,视频会议公司训练AI模型来过滤背景噪音并将睡衣变成虚拟的商务正装。6、中国许多机构合作开发了一种可在CT扫描中检测Covid-19的模型,其准确度超过90%。该模型已在七个国家/地区部署,到目前为止,该模型的代码已下载了超过300万次。
摄影:环球影业集团/阿拉米4、聊天机器人提供了合成的虚拟朋友,供被疫情封锁的人们孤独时聊天和调情。5、对于在家工作的人们,视频会议公司训练AI模型来过滤背景噪音并将睡衣变成虚拟的商务正装。6、中国许多机构合作开发了一种可在CT扫描中检测Covid-19的模型,其准确度超过90%。该模型已在七个国家/地区部署,到目前为止,该模型的代码已下载了超过300万次。 相关链接:https://www.cell.com/cell/pdf/S0092-8674(20)30551-1.pdf7、美国生物技术公司Moderna,其疫苗于12月份获得美国食品药品监督管理局的批准,它使用机器学习来优化mRNA序列以转化为可以测试的分子。
相关链接:https://www.cell.com/cell/pdf/S0092-8674(20)30551-1.pdf7、美国生物技术公司Moderna,其疫苗于12月份获得美国食品药品监督管理局的批准,它使用机器学习来优化mRNA序列以转化为可以测试的分子。 图源:https://www.shutterstock.com/新闻背后:AI可能仍在治疗Covid-19中起重要作用。某非营利组织使用了半监督式深度学习平台来筛选14,000种候选抗病毒药物。该系统验证了有望用于动物试验的四种化合物。8、在防范新冠疫情传播中,口罩成为了绝对主力。为了让大众乖乖带上口罩,人们可谓是操碎了心,AI也在这时候帮上了忙。有人开发了一套AI系统,号称能够根据一个人说话的口音“听”出是否佩戴口罩,且检测的准确率已经达到了78.8%。研究人员开发这项技术的初衷是,他们发现,戴上口罩会影响语音的的效果,这是由于肌肉收缩、发声量增加和传输损失引起的。如今,戴口罩已经成为了日常。为了适应全民戴口罩的新环境,许多AI应用也在对自身进行升级。一些企业就开发出了口罩检测模型,可以判断人群中的个体是否有戴口罩,甚至还开发了对戴口罩人脸进行身份识别的模型。我的立场:人工智能不是万能药,但这种新型、高病毒性、高传染性冠状病毒的问世已经成为人类利用AI对抗传染病能力的有力试验。当生成对抗网络渗透到文化、社会和科学领域时,它们正悄悄地在网络中充斥着无数的合成图像。
图源:https://www.shutterstock.com/新闻背后:AI可能仍在治疗Covid-19中起重要作用。某非营利组织使用了半监督式深度学习平台来筛选14,000种候选抗病毒药物。该系统验证了有望用于动物试验的四种化合物。8、在防范新冠疫情传播中,口罩成为了绝对主力。为了让大众乖乖带上口罩,人们可谓是操碎了心,AI也在这时候帮上了忙。有人开发了一套AI系统,号称能够根据一个人说话的口音“听”出是否佩戴口罩,且检测的准确率已经达到了78.8%。研究人员开发这项技术的初衷是,他们发现,戴上口罩会影响语音的的效果,这是由于肌肉收缩、发声量增加和传输损失引起的。如今,戴口罩已经成为了日常。为了适应全民戴口罩的新环境,许多AI应用也在对自身进行升级。一些企业就开发出了口罩检测模型,可以判断人群中的个体是否有戴口罩,甚至还开发了对戴口罩人脸进行身份识别的模型。我的立场:人工智能不是万能药,但这种新型、高病毒性、高传染性冠状病毒的问世已经成为人类利用AI对抗传染病能力的有力试验。当生成对抗网络渗透到文化、社会和科学领域时,它们正悄悄地在网络中充斥着无数的合成图像。 图源:TechtalkDeepfake出现在主流娱乐活动、商业广告、政治活动中,甚至出现在纪录片中,用来替换当事人的真实面貌以提供隐私保护。在喧嚣中,对图像生成器的在线前端的狂潮基本上没有引起人们的注意。受到2019年的“ This Person Does Not Exist”(一个可以生成假的、逼真的个人肖像网络应用程序)的启发,具有幽默感的工程师采用模仿现实世界细节的生成对抗网络(GAN)。1、经过训练的Google Earth 可以使“This City Does Not Exist”产生大大小小的不存在的定居点的鸟瞰图。
图源:TechtalkDeepfake出现在主流娱乐活动、商业广告、政治活动中,甚至出现在纪录片中,用来替换当事人的真实面貌以提供隐私保护。在喧嚣中,对图像生成器的在线前端的狂潮基本上没有引起人们的注意。受到2019年的“ This Person Does Not Exist”(一个可以生成假的、逼真的个人肖像网络应用程序)的启发,具有幽默感的工程师采用模仿现实世界细节的生成对抗网络(GAN)。1、经过训练的Google Earth 可以使“This City Does Not Exist”产生大大小小的不存在的定居点的鸟瞰图。 AI生成的假的鸟瞰图 图源:http://thiscitydoesnotexist.com/2、“This Horse Does Not Exist” 可以生成各种各样的姿势、品种和状态的马:图源:https://thishorsedoesnotexist.com/3、 “This Pizza Does Not Exist” 生成不存在的披萨,与真实的披萨相比,可能会缺少一些奶酪和酱汁的光泽感。4、用AI生成的不存在的中国山水画,欺骗了众多艺术爱好者。
AI生成的假的鸟瞰图 图源:http://thiscitydoesnotexist.com/2、“This Horse Does Not Exist” 可以生成各种各样的姿势、品种和状态的马:图源:https://thishorsedoesnotexist.com/3、 “This Pizza Does Not Exist” 生成不存在的披萨,与真实的披萨相比,可能会缺少一些奶酪和酱汁的光泽感。4、用AI生成的不存在的中国山水画,欺骗了众多艺术爱好者。 论文链接:https://arxiv.org/pdf/2011.05552.pdf关于GAN的发展、应用和风险等问题,我曾经对Ian Goodfellow进行了简单的访谈。Ian Goodfellow表示,他在GAN那篇论文中就列举了很多未来可能的研究方向,但没有想过域到域的转换(domain-to-domain translation),比如CycleGAN。关于GAN的用途,Ian Goodfellow认为,将GAN应用在医学领域会更有意义,比如为牙科患者设计个性化的牙冠,以及设计药物等等。最后,谈到GAN输出中包含的偏见,Ian Goodfellow表示:“随着GAN生成人脸越来越逼真,GAN可以通过为其他机器学习算法生成训练数据,来抵消训练数据中的偏见。如果你使用的语言在数据中代表性不高,则可以对其进行过度采样。但是,我希望还有其他方法可以解决数据集中代表性不足的问题。”https://blog.deeplearning.ai/blog/the-batch-gan-special-issue-ian-goodfellow-for-real-detecting-fakes-including-minorities-synthesizing-training-data-applying-virtual-make-up由于数据集的编译、标记和使用方式的不同,导致其在模型训练过程中会对社会边缘化群体产生偏见。研究人员的审查促进了AI的改革,同时也加深了人们对AI所隐含的社会偏见的认识。今年涉及的典型案例包括:1、知名计算机视觉数据集ImageNet被推到了风口浪尖。ImageNet的创建者李飞飞及其同事对数据集进行了重新梳理,并删除了WordNet词汇数据库带来的种族主义、性别歧视和其他贬义标签。 2、一项研究发现,即使使用未经标记的ImageNet数据进行训练,其模型也可能由于数据多样性不足而引起偏差。3、麻省理工学院计算机科学与人工智能实验室撤回了Tiny Images数据集,原因是有外部研究人员发现该数据库充斥着性暗示、种族歧视等大量不良标签。4、用于训练StyleGAN的数据集FlickrFaces-HQ(FFHQ)同样缺乏足够的多样性。基于StyleGAN模型训练的PULSE算法将美国黑人总统巴拉克·奥巴马(Barack Obama)的肖像画变成了白人。(PULSE可以将提高低分辨率照片转化为高分辨率的图像)在PULSE事件爆发后,Facebook首席科学家Yann LeCun和当时Google AI伦理负责人Timnit Gebru之间展开了一场辩论,争论的焦点在于:机器学习中的社会偏见是出自AI数据集,还是AI模型?LeCun的立场是:模型在训练“存在偏见的数据集”之前不存在偏见,也就是模型本身不存在偏见,而且有偏见的数据集是可以修改的。Gebru则表示:正如我们在信中所说的,这种偏见是在社会差异的背景下产生的,要消除AI系统的偏见,必须解决整个领域的差异。随后,在关于偏见的进一步分歧中,Gebru和谷歌分道扬镳。Gebru对人脸识别技术进行过深入研究,并曾就科技行业缺乏多样性发表过言论。此次Gebru被谷歌解雇事件的起因是Gebru想要发表一篇关于大型语言模型的社会危害的论文,但被谷歌内部否决、要求撤稿,Gebru尝试沟通无果,控诉谷歌不尊重边缘群体的人权。我的立场:确保数据集中的偏见在任务开始前被删除,而这项重要的工作才刚刚开始。https://blog.deeplearning.ai/blog/the-batch-ais-progress-problem-recognizing-masked-faces-mapping-underwater-ecosystems-augmenting-feature全球新冠疫情和有争议的美国大选掀起了一场虚假信息风暴,大型AI科技公司均受到了影响。面对来自公众日益增加的压力——阻止煽动性谎言,Facebook、Google的YouTube部门以及Twitter在争相更新其推荐引擎。据了解,纪录片Netflix对他们进行了严厉的痛斥;美国国会议员对他们展开了调查;民意测验显示,他们已经失去了大多数美国人的信任。这几家公司尝试通过各种算法和策略解决虚假信息问题,例如:1、在发现了数百个包含AI生成的虚假头像的用户个人资料后,Facebook严厉打击了被认为有误导性的操纵媒体,并彻底禁止了Deepfake视频。该公司继续开发深度学习工具,以检测仇恨言论,导致偏见的模因以及有关Covid-19的错误信息。2、YouTube开发了一个分类器来识别所谓的边界内容:包括仇恨言论、宣传阴谋论、医学错误信息以及其他想法的视频。3、Facebook和Twitter关闭了他们认为是扰乱国家宣传活动的账户。4、这三家公司在含有美国大选误导性信息内容中均添加了免责声明。Twitter采取了最严格的政策,直接举报了特朗普的虚假推文。不过,他们显然没有做出触及底线的更改。而且其改革可能也不会持续很久,因为他们采取的政策有的已经松懈,有的已经发生了适得其反的效果。比如:
论文链接:https://arxiv.org/pdf/2011.05552.pdf关于GAN的发展、应用和风险等问题,我曾经对Ian Goodfellow进行了简单的访谈。Ian Goodfellow表示,他在GAN那篇论文中就列举了很多未来可能的研究方向,但没有想过域到域的转换(domain-to-domain translation),比如CycleGAN。关于GAN的用途,Ian Goodfellow认为,将GAN应用在医学领域会更有意义,比如为牙科患者设计个性化的牙冠,以及设计药物等等。最后,谈到GAN输出中包含的偏见,Ian Goodfellow表示:“随着GAN生成人脸越来越逼真,GAN可以通过为其他机器学习算法生成训练数据,来抵消训练数据中的偏见。如果你使用的语言在数据中代表性不高,则可以对其进行过度采样。但是,我希望还有其他方法可以解决数据集中代表性不足的问题。”https://blog.deeplearning.ai/blog/the-batch-gan-special-issue-ian-goodfellow-for-real-detecting-fakes-including-minorities-synthesizing-training-data-applying-virtual-make-up由于数据集的编译、标记和使用方式的不同,导致其在模型训练过程中会对社会边缘化群体产生偏见。研究人员的审查促进了AI的改革,同时也加深了人们对AI所隐含的社会偏见的认识。今年涉及的典型案例包括:1、知名计算机视觉数据集ImageNet被推到了风口浪尖。ImageNet的创建者李飞飞及其同事对数据集进行了重新梳理,并删除了WordNet词汇数据库带来的种族主义、性别歧视和其他贬义标签。 2、一项研究发现,即使使用未经标记的ImageNet数据进行训练,其模型也可能由于数据多样性不足而引起偏差。3、麻省理工学院计算机科学与人工智能实验室撤回了Tiny Images数据集,原因是有外部研究人员发现该数据库充斥着性暗示、种族歧视等大量不良标签。4、用于训练StyleGAN的数据集FlickrFaces-HQ(FFHQ)同样缺乏足够的多样性。基于StyleGAN模型训练的PULSE算法将美国黑人总统巴拉克·奥巴马(Barack Obama)的肖像画变成了白人。(PULSE可以将提高低分辨率照片转化为高分辨率的图像)在PULSE事件爆发后,Facebook首席科学家Yann LeCun和当时Google AI伦理负责人Timnit Gebru之间展开了一场辩论,争论的焦点在于:机器学习中的社会偏见是出自AI数据集,还是AI模型?LeCun的立场是:模型在训练“存在偏见的数据集”之前不存在偏见,也就是模型本身不存在偏见,而且有偏见的数据集是可以修改的。Gebru则表示:正如我们在信中所说的,这种偏见是在社会差异的背景下产生的,要消除AI系统的偏见,必须解决整个领域的差异。随后,在关于偏见的进一步分歧中,Gebru和谷歌分道扬镳。Gebru对人脸识别技术进行过深入研究,并曾就科技行业缺乏多样性发表过言论。此次Gebru被谷歌解雇事件的起因是Gebru想要发表一篇关于大型语言模型的社会危害的论文,但被谷歌内部否决、要求撤稿,Gebru尝试沟通无果,控诉谷歌不尊重边缘群体的人权。我的立场:确保数据集中的偏见在任务开始前被删除,而这项重要的工作才刚刚开始。https://blog.deeplearning.ai/blog/the-batch-ais-progress-problem-recognizing-masked-faces-mapping-underwater-ecosystems-augmenting-feature全球新冠疫情和有争议的美国大选掀起了一场虚假信息风暴,大型AI科技公司均受到了影响。面对来自公众日益增加的压力——阻止煽动性谎言,Facebook、Google的YouTube部门以及Twitter在争相更新其推荐引擎。据了解,纪录片Netflix对他们进行了严厉的痛斥;美国国会议员对他们展开了调查;民意测验显示,他们已经失去了大多数美国人的信任。这几家公司尝试通过各种算法和策略解决虚假信息问题,例如:1、在发现了数百个包含AI生成的虚假头像的用户个人资料后,Facebook严厉打击了被认为有误导性的操纵媒体,并彻底禁止了Deepfake视频。该公司继续开发深度学习工具,以检测仇恨言论,导致偏见的模因以及有关Covid-19的错误信息。2、YouTube开发了一个分类器来识别所谓的边界内容:包括仇恨言论、宣传阴谋论、医学错误信息以及其他想法的视频。3、Facebook和Twitter关闭了他们认为是扰乱国家宣传活动的账户。4、这三家公司在含有美国大选误导性信息内容中均添加了免责声明。Twitter采取了最严格的政策,直接举报了特朗普的虚假推文。不过,他们显然没有做出触及底线的更改。而且其改革可能也不会持续很久,因为他们采取的政策有的已经松懈,有的已经发生了适得其反的效果。比如:- 今年6月,《华尔街日报》报道说,一些Facebook高管已经停止使用部分监管工具。该公司后来撤销了在选举期间使用的修改算法,因为它促进了某些新闻源的知名度。Facebook不够诚意的做法已经导致了一些员工辞职。
- YouTube采用的算法成功减少了虚假信息内容的创作者的访问量。但是,它也增加了某些经常传播同样可疑信息的大型实体网站的访问量。
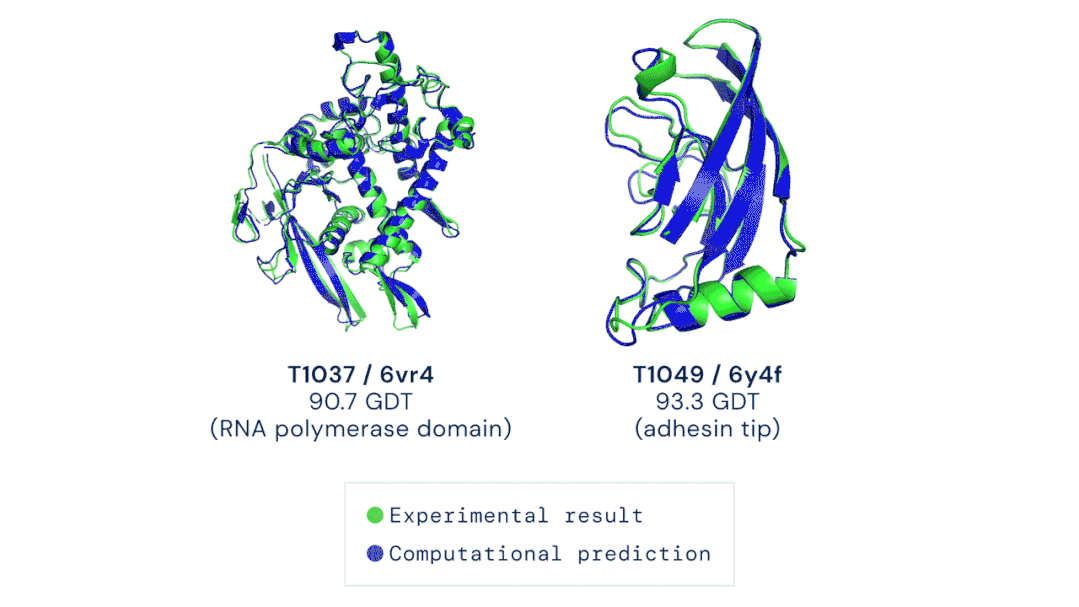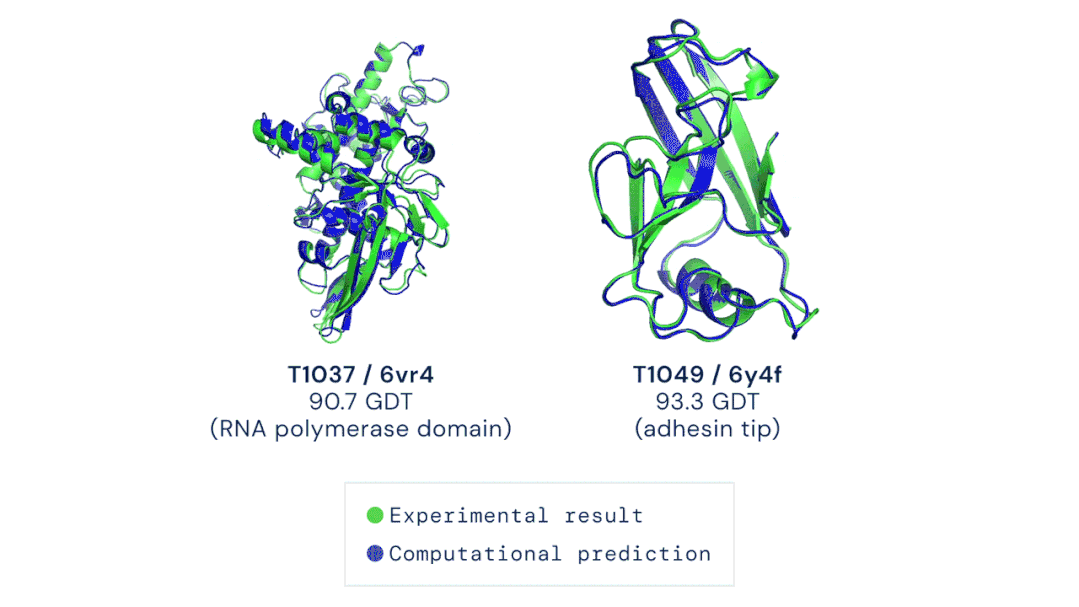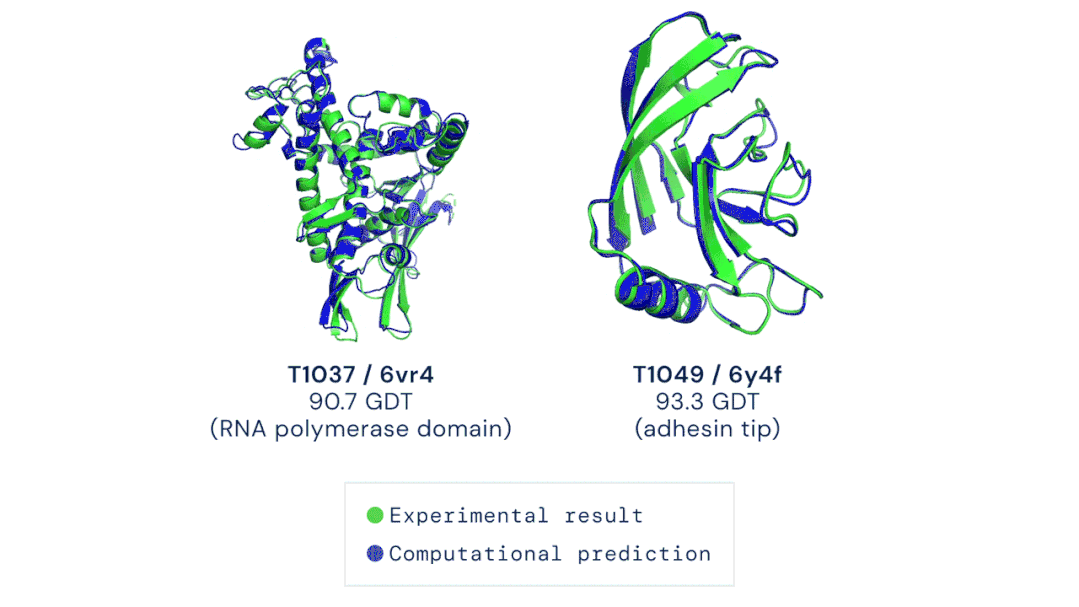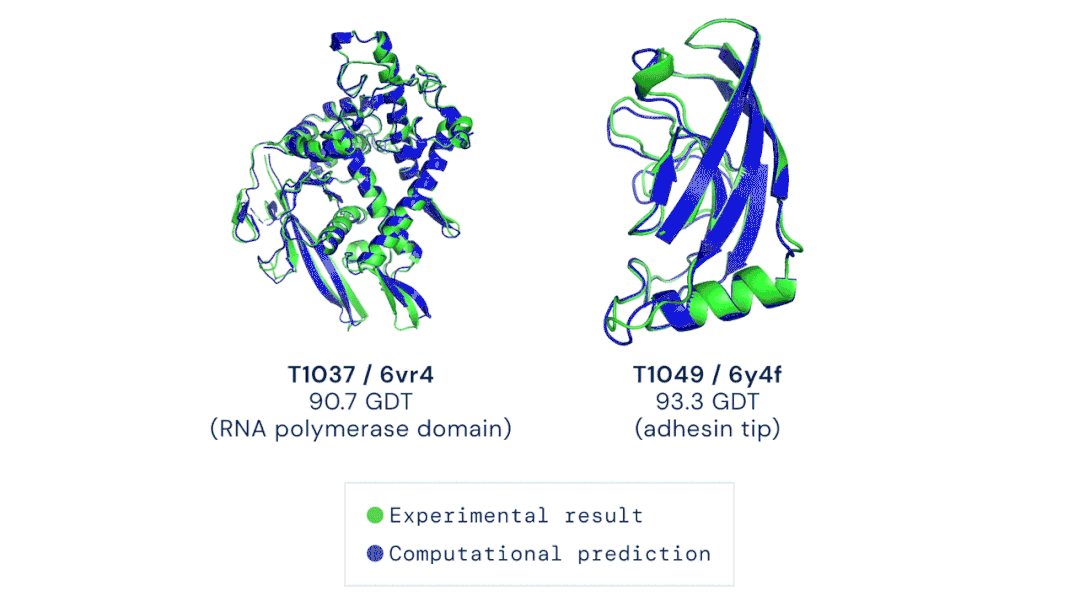
我的立场:在这场猫和老鼠的游戏中,目前尚无明确的方法能够赢得那些造谣者或虚假内容传播者,但是猫在这场游戏中必须保持领先的地位,否则将会失去公众的信任,或者遭到监管机构的调查。 AI在医学领域的制度阻碍逐渐减少,为深度学习在医疗设备和治疗中的广泛应用奠定了基础。前不久,DeepMind的AlphaFold2 模型在短短几个小时内就确定了蛋白质的三维结构,其对研发新型药物的承诺和对生物学的洞察迅速引起了人们的关注。具体而言,是DeepMind的第二代AlphaFold 在国际蛋白质结构预测竞赛(CASP)上击败了其余的参会选手,能够精确地基于氨基酸序列,预测蛋白质的3D结构。其准确性可以与使用冷冻电子显微镜(CryoEM)、核磁共振或 X 射线晶体学等实验技术解析的3D结构相媲美。据了解,医疗机构已经采取了行动将此类技术纳入了主流医学实践中。以下制度上的转变提高了医疗AI的知名度,也让它越来越受到认可:1、美国最大的医疗保险公司已同意向某些使用了机器学习设备的医生提供补偿。2、美国食品药品监督管理局(FDA)批准了几种新的基于AI的治疗方法和设备,例如心脏超声检查系统。3、一个跨学科的国际医学专家小组介绍了两个协议:Spirit和Consort,该协议旨在确保基于AI的临床试验能够遵循最佳实践,同时,便于外部评审人验证试验成果并进行报告。我的立场:AI在医学中的应用要求医生和医院重新组织其工作流程,这在一定程度上延缓了AI应用的进度。一旦FDA和医疗保障制度变得更加明朗,临床医生就会获得更大的动力去做出改变以适应它们。更多信息:Deeplearning AI医疗专刊包括深度学习在诊断、预防和治疗方面的应用,以及AI医学教父Eric Topol的独家专访。https://blog.deeplearning.ai/blog/the-batch-ai-for-medicine-special-eric-topols-planetary-health-system-discovering-drugs-diagnosing-heart-disease-predicting-infections-alexa-for-doctors自然语言处理的神经网络规模越来越大,功能也越来越丰富、有趣。例如GPT-3可以用来写作画图、敲代码、玩游戏等,被网友们玩出了50多种新用法。GPT-3是OpenAI打造的包含1750亿参数的文本生成器,它展示了自然语言处理方面的持续进步。同时,它展现了机器学习领域的广泛趋势:模型参数呈指数增长,无监督学习成为主流,且越来越普遍。  图源:Musings about Librarianship1、GPT-3的写作能力比上一代GPT-2更加强大,以至于用它来撰写博客文章和Reddit评论时,成功欺骗了很多人类读者。另外,也有很多人以不同的方式展现了GPT-3的创造性,例如撰写哲学文章、与历史人物对话。
图源:Musings about Librarianship1、GPT-3的写作能力比上一代GPT-2更加强大,以至于用它来撰写博客文章和Reddit评论时,成功欺骗了很多人类读者。另外,也有很多人以不同的方式展现了GPT-3的创造性,例如撰写哲学文章、与历史人物对话。  图注:AI生成的哲学文章2、语言模型促进了商业工具的发展,例如帮助Apple自动更正功能区分不同语言;让Amazon的语音小助手Alexa能够跟随对话内容切换;更新机器人律师,对非法称呼美国公民的电话销售商提起诉讼。3、OpenAI的GPT-2能够训练像素数据生成(即iGPT),iGPT通过填充部分模糊的内容以生成怪异的图像。我的立场:语言模型显然越大越好,但它还不止于此。iGPT预示着在图像和文字上训练的模型(至少在OpenAI的工作中),它可能比2020年的大型语言模型更聪明、更怪异。更多信息:NLP特刊包括有关如何消除偏见,以及对NLP先驱Noam Shazeer的独家采访。https://blog.deeplearning.ai/blog/the-batch-nlp-special-issue-powerful-techniques-from-amazon-apple-facebook-google-microsoft-salesforce
图注:AI生成的哲学文章2、语言模型促进了商业工具的发展,例如帮助Apple自动更正功能区分不同语言;让Amazon的语音小助手Alexa能够跟随对话内容切换;更新机器人律师,对非法称呼美国公民的电话销售商提起诉讼。3、OpenAI的GPT-2能够训练像素数据生成(即iGPT),iGPT通过填充部分模糊的内容以生成怪异的图像。我的立场:语言模型显然越大越好,但它还不止于此。iGPT预示着在图像和文字上训练的模型(至少在OpenAI的工作中),它可能比2020年的大型语言模型更聪明、更怪异。更多信息:NLP特刊包括有关如何消除偏见,以及对NLP先驱Noam Shazeer的独家采访。https://blog.deeplearning.ai/blog/the-batch-nlp-special-issue-powerful-techniques-from-amazon-apple-facebook-google-microsoft-salesforce2021年展望
与吴恩达的2020年回顾相呼应,Highland Capital Partners 风险投资家 Rob Toews 对 2021 年 AI 的领域将会发生什么提出了 10 个大胆预测,包含了从学术研究、监管等各个领域。其中两者提到的话题有很多重合的部分,比如Deepfake、GPT-3、AlphaFold等,基于这些事物在今年的关注度,相信读者也不会感到意外,以下节选7个供读者参考。
以下内容转载自学术头条
1、Deepfake 骗局将引发广泛的混乱和错误信息

Deepfake 技术正在迅速改进和扩散。加蓬和巴西最近发生的事件,反映出了该技术在政治领域具有的破坏力。2021 年将是 Deepfake 内容在美国成为主流的一年,有相当一小部分人最初认为它是真实的。Deepfake 所引起破坏的,很可能就是一个公众人物发表具有争议评论的视频。
作为回应,一些政策制定者将加大呼吁力度,认为大型科技公司必须负责监管 Deepfake 技术在其平台上的传播。
2、有关联邦学习的学术研究将激增
对于消费者和监管机构而言,数据隐私的保护正成为一个日益紧迫的问题。因此,保护隐私的 AI 方法将继续成为构建机器学习模型的最可持续的方式。这些方法中最突出的是联邦学习(Federated Learning)。
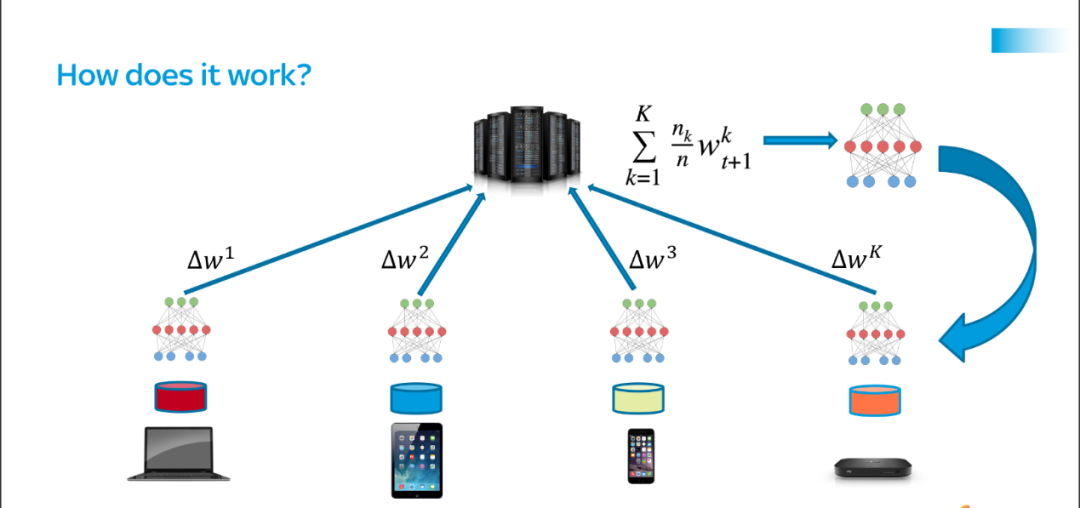 (来源:Proandroidde)
(来源:Proandroidde)
据谷歌学术(Google Scholar)统计,有关联邦学习的学术研究论文数量已经从 2018 年的 254 篇增加到 2019 年的 1340 篇,到 2020 年该领域的论文发表数量达到了 3940 篇。这种指数级的增长将持续下去:到 2021 年,将发表超过 10000 篇关于联邦学习主题的研究论文。
3、AI 芯片初创公司将被大型半导体公司超高价收购
专为 AI 工作负载而打造的硅基芯片,是半导体行业的未来。英特尔去年以 20 亿美元收购 Habana Labs 就是对这一趋势的认可。为了防止自身受到干扰,另一家传统芯片制造商将在 2021 年大举收购一家 AI 芯片初创公司。
 (来源:Designnews)
(来源:Designnews)
最可能的收购目标:Graphcore、Cerebras、SambaNova
最有可能的收购者:NVIDIA、AMD、Qualcomm、Intel
4、AI 药物公司将被大型制药公司以超高价收购
大型制药公司已经意识到这样一个事实,即机器学习提供了革新药物发现和开发的潜力。2021 年,一家主要的制药公司将出资收购一家 AI 药物初创公司,将其技术和人才引入到公司内部。
 (来源:Nature)
(来源:Nature)
最可能的收购目标:Recursion、Exscientia、Insitro、Atomwise
最有可能的收购方:Bayer、GlaxoSmithKline、Novartis、Bristol Myers Squibb、Eli Lilly、Gilead
5、GPT-4 参数将超过一万亿
OpenAI 在 2019 年发布了 GPT-2,它拥有 15 亿个参数,这是第一个具有超过 10 亿个参数的非线性规划(NLP)模型。当时,这被认为是惊人的模型。2020 年,OpenAI 在全球发布了 GPT-3,其参数高达 1750 亿。

第一个参数超过 1 万亿的模型最有可能来自 OpenAI,并命名为 GPT-4。其他可能突破万亿参数模型大关的组织包括 Microsoft、NVIDIA、Facebook 和 Google。
随着第一个参数超过 1 万亿的模型发布,模型 “军备竞赛” 将在 2021 年继续。
6、AI 将成为监管机构反垄断调查的重要部分
今年,美国和欧洲的监管机构对亚马逊、苹果、Facebook 和 Google 正式发起了反垄断诉讼。到目前为止,监管机构在阐述针对科技巨头的反垄断案件时,并没有明确关注 AI。
 图 | 多家公司参加反垄断调查(来源:Venture Beat)
图 | 多家公司参加反垄断调查(来源:Venture Beat)
在未来的一年里,预计监管机构将开始更频繁地关注、提及 AI,阐述这些公司如何以及为什么不公平地扼杀竞争。核心讨论的地方是,这些公司的数据垄断让它们在开发有效的机器学习算法方面拥有不可逾越的优势。
7、生物将继续是机器学习最热门、最具变革性的领域
这是这个列表中最不可预测的部分,同时它也是这个列表中最重要的预测。
 图 | AlphaFold 解决蛋白质结构问题(来源:Edward Kinsman)
图 | AlphaFold 解决蛋白质结构问题(来源:Edward Kinsman)
无论是在学术研究、创业投资和主流媒体关注方面,生物学都将日益成为应用人工智能影响最大的领域。DeepMind 上个月的历史性 AlphaFold 成就,其影响将需要数年才能完全发挥出来。而当前这些 AI 在生物领域的成果,仅仅是人类通过将计算方法和机器学习应用于生物学奥秘实现成就的开端。
https://blog.deeplearning.ai/blog/the-batch-biggest-ai-stories-of-2020-covid-triage-fun-with-gans-disinfo-whack-a-mole-gpt-superstar-imagenet-recall-fda-approvals?utm_source=Social&utm_medium=Twitter&utm_campaign=TheBatch_12.23.20https://www.forbes.com/sites/robtoews/2020/12/22/10-ai-predictions-for-2021/
往期精彩:
【原创首发】机器学习公式推导与代码实现30讲.pdf
【原创首发】深度学习语义分割理论与实战指南.pdf
谈中小企业算法岗面试
算法工程师研发技能表
真正想做算法的,不要害怕内卷
技术学习不能眼高手低
技术人要学会自我营销
做人不能过拟合
求个在看