
【极市打榜】算法竞赛/打榜通用技巧总结(附源码)

极市导读
极市打榜是面向计算机视觉开发者的算法竞技,参与者人人都可以通过提高算法分数(精度+性能分)获得早鸟奖励+分分超越奖励,排行榜前三名的胜利者将有机会获得该算法的极市复购订单,获得持续的订单收益。
提供免费算力+真实场景数据集;早鸟奖励+分分超越奖励+持续订单分成,实时提现!
前言
模型选取
目标检测 Yolo系列:yolov5, yolo4, yolov3等 SSD nanodet yolox 语义分割 BiSeNet STDC 目标追踪 yolov5+deepsort 视频(动作)分类 TSM SlowFast x3d
编码和训练
结果图可保存在 /project/train/result-graph,那么训练完成后即可在训练页面查看
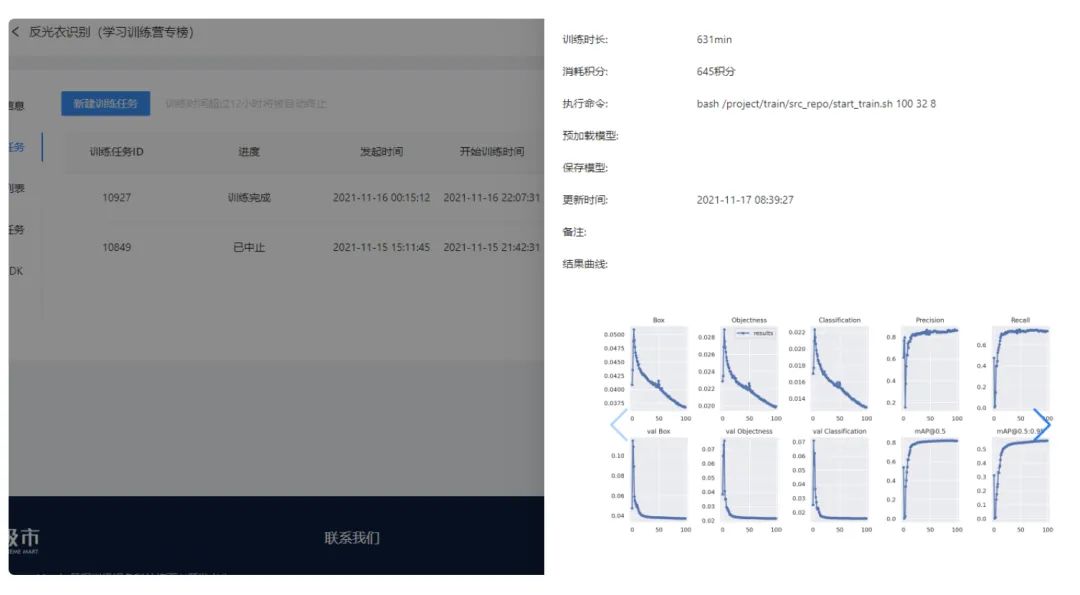
将训练的保存路径设置为 /project/train/models,那么训练终止后,从保存的模型重新加载后,仍然可以恢复训练

可以对随机划分数据集设置随机数种子,以保证每次训练的数据都是一致的
random.seed(1)
如果github下载过慢,这里我们可以使用一个镜像网址进行操作: hub.fastgit.org,例如将
git clone https://github.com/ExtremeMart/ev_sdk.git
wget https://github.com/ExtremeMart/dev-docs/archive/refs/tags/v3.0.3.zip
git clone https://hub.fastgit.org/ExtremeMart/ev_sdk.git
wget https://hub.fastgit.org/ExtremeMart/dev-docs/archive/refs/tags/v3.0.3.zip
如果遇到资源不足导致实例打开失败,可尝试多次启动实例,如果还是不行,可以尝试重建实例。
测试
pip install nvidia-pyindex
pip install nvidia-tensorrt pycuda
cd /usr/local
# install cuda10.2
mkdir temp && cd temp && wget https://minio.cvmart.net/user-file/9876/886bcb1539b2460f8938f63fb5643356.zip && unzip 886bcb1539b2460f8938f63fb5643356.zip
dpkg -i libxnvctrl0_440.33.01-0ubuntu1_amd64.deb libxnvctrl-dev_440.33.01-0ubuntu1_amd64.deb cuda-cluster-runtime-10-2_10.2.89-1_amd64.deb cuda-cluster-devel-10-2_10.2.89-1_amd64.deb nsight-compute-2019.5.0_2019.5.0.14-1_amd64.deb NsightSystems-linux-public-2019.5.2.16-b54ef97.deb
cd ../ && rm -rf temp cuda cuda-10.1 && ln -s /usr/local/cuda-10.2 /usr/local/cuda
# install cudnn8.1
wget https://minio.cvmart.net/user-file/9876/0e24bccb454b4f54aedb9395ff781691.deb && dpkg -i 0e24bccb454b4f54aedb9395ff781691.deb
# install TensorRT7.2.3
wget https://minio.cvmart.net/user-file/9876/10e90f8459754eebbabe0e95026f0119.gz && tar -xf 10e90f8459754eebbabe0e95026f0119.gz
echo "export LD_LIBRARY_PATH=/usr/local/TensorRT-7.2.3.4/lib:$LD_LIBRARY_PATH" >> ~/.zshrc && source ~/.zshrc
rm 10e90f8459754eebbabe0e95026f0119.gz 0e24bccb454b4f54aedb9395ff781691.deb
# build opencv-4.1.2
cd /home
wget https://minio.cvmart.net/user-file/9876/e695f9548daa4fd7a942691505bb3d94.zip && unzip e695f9548daa4fd7a942691505bb3d94.zip && rm e695f9548daa4fd7a942691505bb3d94.zip
cd opencv-4.1.2 && mkdir build && cd build
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local -D OPENCV_EXTRA_MODULES_PATH=/home/opencv_contrib -D PYTHON_DEFAULT_EXECUTABLE=/usr/bin/python3 -D BUILD_opencv_python3=OFF -D BUILD_opencv_python2=OFF -D PYTHON3_EXCUTABLE=/usr/bin/python3 -D WITH_CUDA=OFF -D OPENCV_GENERATE_PKGCONFIG=ON ..
make -j8
make install
更改测试输入尺寸,可以加速网络运行速度,但是可能会降低精度。 测试时,可以更改置信度等参数,去寻找更好的测试结果。 由于目前平台不支持测试备注,因此我们可以用文档记录每次所改的测试参数。
快速部署
例子
配置好训练环境和测试环境, 可参考前面。 对数据集进行转换,得到yolo格式的数据集,并划分数据集。
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import sys
import shutil
import pathlib
import random
import xml.etree.ElementTree as ET
import io
from global_config import *
train_data_dir = os.path.join(project_root, 'dataset/images/train/')
valid_data_dir = os.path.join(project_root, 'dataset/images/valid')
annotations_train_dir = os.path.join(project_root, 'dataset/labels/train')
annotations_valid_dir = os.path.join(project_root, 'dataset/labels/valid')
supported_fmt = ['.jpg', '.JPG']
def convert_box(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
return x * dw, y * dh, w * dw, h * dh
def xml_to_yolo(data_list,annotations_dir):
"""将data_list表示的(图片, 标签)对转换成yolo记录
"""
xml_list = []
for data in data_list:
out_file = open(os.path.join(annotations_dir, os.path.basename(data['label']).replace('.xml', '.txt')), 'w')
tree = ET.parse(data['label'])
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes: #or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert_box((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
out_file.close()
if __name__ == '__main__':
os.makedirs(project_root, exist_ok=True)
os.makedirs(train_data_dir, exist_ok=True)
os.makedirs(valid_data_dir, exist_ok=True)
os.makedirs(annotations_train_dir, exist_ok=True)
os.makedirs(annotations_valid_dir, exist_ok=True)
if not os.path.exists(sys.argv[1]):
print(f'{sys.argv[1]} 不存在!')
exit(-1)
# 遍历数据集目录下所有xml文件及其对应的图片
dataset_path = pathlib.Path(sys.argv[1])
found_data_list = []
for xml_file in dataset_path.glob('**/*.xml'):
possible_images = [xml_file.with_suffix(suffix) for suffix in supported_fmt]
supported_images = list(filter(lambda p: p.is_file(), possible_images))
if len(supported_images) == 0:
print(f'找不到对应的图片文件:`{xml_file.as_posix()}`')
continue
found_data_list.append({'image': supported_images[0], 'label': xml_file})
# 随机化数据集,将数据集拆分成训练集和验证集,并将其拷贝到/project/train/src_repo/dataset下
random.seed(1)
random.shuffle(found_data_list)
train_data_count = len(found_data_list) * 4 / 5
train_data_list = []
valid_data_list = []
for i, data in enumerate(found_data_list):
if i < train_data_count: # 训练集
dst = train_data_dir
data_list = train_data_list
else: # 验证集
dst = valid_data_dir
data_list = valid_data_list
image_dst = (pathlib.Path(dst) / data['image'].name).as_posix()
label_dst = (pathlib.Path(dst) / data['label'].name).as_posix()
shutil.copy(data['image'].as_posix(), image_dst)
shutil.copy(data['label'].as_posix(), label_dst)
data_list.append({'image': image_dst, 'label': label_dst})
#xml to yolo
xml_to_yolo(train_data_list, annotations_train_dir)
xml_to_yolo(valid_data_list, annotations_valid_dir)
print('Successfully converted xml to yolo.')
用 yolov5 对数据集进行训练,通过调参获得一个最好的模型。
#!/bin/bash
# 创建默认目录,训练过程中生成的模型文件、日志、图必须保存在这些固定目录下,训练完成后这些文件将被保存
rm -rf /project/train/models/result-graphs && rm -rf /project/train/log && rm -rf /project/train/src_repo/dataset
mkdir -p /project/train/result-graphs && mkdir -p /project/train/log
project_root_dir=/project/train/src_repo
dataset_dir=/home/data
log_file=/project/train/log/log.txt
if [ ! -z $1 ]; then
num_train_steps=$1
else
num_train_steps=10
fi
if [ ! -z $2 ]; then
batch_size=$2
else
batch_size=16
fi
if [ ! -z $3 ]; then
workers=$3
else
workers=2
fi
echo "Converting dataset..." \
&& python3 -u ${project_root_dir}/convert_dataset.py ${dataset_dir} | tee -a ${log_file} \
&& cd ${project_root_dir} && cp data.yaml yolov5/data/ \
&& pip install -i https://mirrors.cloud.tencent.com/pypi/simple -r /project/train/src_repo/yolov5/requirements.txt \
&& echo "Start training..." \
&& cd yolov5 && python3 -u train.py --data data.yaml --project /project/train/models --batch-size ${batch_size} --epochs ${num_train_steps} --workers ${workers} 2>&1 | tee -a ${log_file} \
&& echo "Done!!!" \
&& echo "Copy result images to /project/train/result-graphs ..." \
&& cp /project/train/models/exp/*.jpg /project/train/models/exp/*.png /project/train/result-graphs | tee -a ${log_file} \
&& echo "Finished!!!"
参考github的tensorrtx对模型进行转换,以及完成sdk的代码编写。
from __future__ import print_function
import logging as log
import os
import pathlib
import json
import cv2
import numpy as np
import time
from yolov5_trt import YoLov5TRT, warmUpThread
# For objection detection task, replace your target labels here.
categories = ['reflective_vest','no_reflective_vest','person_reflective_vest','person_no_reflective_vest']
def init():
"""
Initialize model
Returns: model
"""
engine_file_path = "/project/ev_sdk/model/best.engine"
yolov5_wrapper = YoLov5TRT(engine_file_path)
try:
#warm up
for i in range(5):
# create a new thread to do warm_up
thread1 = warmUpThread(yolov5_wrapper)
thread1.start()
thread1.join()
finally:
# destroy the instance
yolov5_wrapper.destroy()
return yolov5_wrapper
def process_image(net=None, input_image=None, args=None, **kwargs):
"""Do inference to analysis input_image and get output
Attributes:
net: model handle
input_image (numpy.ndarray): image to be process, format: (h, w, c), BGR
thresh: thresh value
Returns: process result
"""
if not net or input_image is None:
log.error('Invalid input args')
return json.dumps({'model_data':{'objects':[]}})
data = net.infer((x for x in [input_image]))[0]
res_json={'model_data':dict()}
if data[0] is None:
return json.dumps({'model_data':{'objects':[]}})
else:
detect_objs = []
for i in range(len(data[0])):
xyxy, conf, cls = data[0][i], data[1][i], int(data[2][i])
detect_objs.append({
'name': categories[cls],
'xmin': int(xyxy[0]),
'ymin': int(xyxy[1]),
'xmax': int(xyxy[2]),
'ymax': int(xyxy[3]),
'confidence': float(conf)
})
res_json['model_data']['objects'] = detect_objs
return json.dumps(res_json)
if __name__ == '__main__':
# Test API
img = cv2.imread('/project/ev_sdk/data/test.jpg')
predictor = init()
import time
s = time.time()
for i in range(20):
res = process_image(predictor, img)
e = time.time()
print(res)
print((e-s)/20)
更改阈值或者输入尺寸参数,进行测试得到最优结果。
总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论