点击下面卡片关注“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
继 2020 年初 Facebook 开源基于 PyTorch 的 3D 计算机视觉库 PyTorch3D 之后,谷歌也于近日开源了一个基于 TF 框架的高度模块化和高效处理库 TensorFlow 3D。目前,该库已经开源。
3D 计算机视觉是一个非常重要的研究课题,选择合适的计算框架对处理效果将会产生很大的影响。此前,机器之心曾介绍过 Facebook 开源的基于 PyTorch 框架的 3D 计算机视觉处理库 PyTorch3D,该库在 3D 建模、渲染等多方面处理操作上表现出了更好的效果。最近,另一个常用的深度学习框架 TensorFlow 也有了自己的高度模块化和高效处理库。它就是谷歌 AI 推出的 TensorFlow 3D(TF 3D),将 3D 深度学习能力引入到了 TensorFlow 框架中。TF 3D 库基于 TensorFlow 2 和 Keras 构建,使得更易于构建、训练和部署 3D 语义分割、3D 实例分割和 3D 目标检测模型。目前,TF 3D 库已经开源。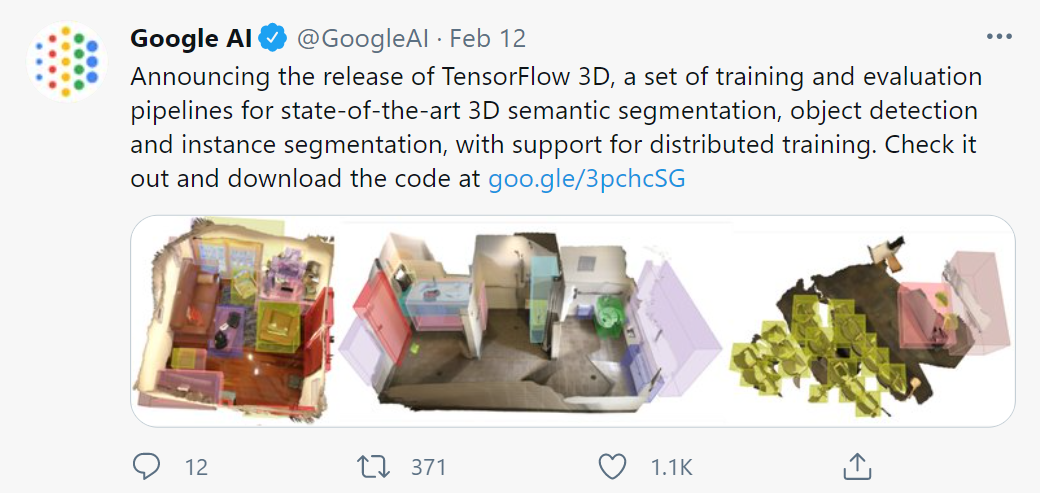
GitHub 项目地址:https://github.com/google-research/google-research/tree/master/tf3d
TF 3D 提供了一系列流行的运算、损失函数、数据处理工具、模型和指标,使得更广泛的研究社区方便地开发、训练和部署 SOTA 3D 场景理解模型。TF 3D 还包含用于 SOTA 3D 语义分割、3D 目标检测和 3D 实例分割的训练和评估 pipeline,并支持分布式训练。该库还支持 3D 物体形状预测、点云配准和点云加密等潜在应用。此外,TF 3D 提供了用于训练和评估标准 3D 场景理解数据集的统一数据集规划和配置,目前支持 Waymo Open、ScanNet 和 Rio 三个数据集。不过,用户可以自由地将 NuScenes 和 Kitti 等其他流行数据集转化为类似格式,并在预先存在或自定义创建的 pipeline 中使用它们。最后,用户可以将 TF 3D 用于多种 3D 深度学习研究和应用,比如快速原型设计以及尝试新思路来部署实时推理系统。下图(左)为 TF 3D 库中 3D 目标检测模型在 Waymo Open 数据集帧上的输出示例;下图(右)为 TF 3D 库中 3D 实例分割模型在 ScanNet 数据集场景上的输出示例。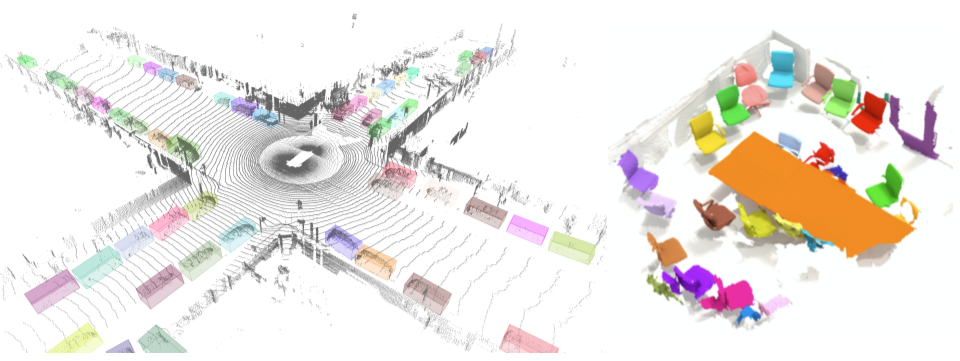
谷歌详细介绍了 TF 3D 库中提供的高效和可配置稀疏卷积骨干网络,该网络是在各种 3D 场景理解任务上取得 SOTA 结果的关键。在 TF 3D 库中,谷歌使用子流形稀疏卷积和池化操作,这两者被设计用于更高效地处理 3D 稀疏数据。稀疏卷积模型是大多数户外自动驾驶(如 Waymo 和 NuScenes)和室内基准(如 ScanNet)中使用的 SOTA 方法的核心。谷歌还使用各种 CUDA 技术来加速计算(如哈希算法、共享内存中分割 / 缓存滤波器以及位操作)。在 Waymo Open 数据集上的实验表明,这种实现的速度约是利用预先存在 TensorFlow 操作的实现的 20 倍。TF 3D 库中使用 3D 子流形稀疏 U-Net 架构来提取每个体素(voxel)的特征。通过令网络提取稀疏和细微特征并结合它们以做出预测,U-Net 架构已被证实非常有效。在结构上,U-Net 网络包含三个模块:编码器、瓶颈层和解码器,它们均是由大量具有潜在池化或非池化操作的稀疏卷积块组成的。
稀疏卷积网络是 TF 3D 中所提供 3D 场景理解 pipeline 的骨干。并且,3D 语义分割、3D 实例分割和 3D 目标检测模型使用稀疏卷积网络来提取稀疏体素的特征,然后添加一个或多个额外的预测头(head)来推理感兴趣的任务。用户可以通过改变编码器或解码器层数和每个层的卷积数,以及调整卷积滤波器大小来配置 U-Net 网络,从而探索不同骨干网络配置下各种速度或准确率的权衡。目前,TF 3D 支持三个 pipeline,分别是 3D 语义分割、3D 实例分割和 3D 目标检测。3D 语义分割模型仅有一个用于预测每体素(per-voxel )语义分数的输出头,这些语义被映射回点以预测每点的语义标签。下图为 ScanNet 数据集中室内场景的 3D 语义分割结果:
除了预测语义之外,3D 实例分割的另一目的是将属于同一物体的体素集中分组在一起。TF 3D 中使用的 3D 实例分割算法基于谷歌之前基于深度度量学习的 2D 图像分割。模型预测每体素的实例嵌入向量和每体素的语义分数。实例嵌入向量将这些体素嵌入至一个嵌入空间,在此空间中,属于同一物体实例的体素紧密靠拢,而属于不同物体的体素彼此远离。在这种情况下,输入的是点云而不是图像,并且使用了 3D 稀疏网络而不是 2D 图像网络。在推理时,贪婪算法每次选择一个实例种子,并利用体素嵌入之间的距离将它们分组为片段。3D 目标检测模型预测每体素大小、中心、旋转矩阵和目标语义分数。在推理时使用 box proposal 机制,将成千上万个每体素 box 预测缩减为数个准确的 box 建议;在训练时将 box 预测和分类损失应用于每体素预测。谷歌在预测和真值 box 角(box corner)之间的距离上应用到了 Huber 损失。由于 Huer 函数根据 box 大小、中心和旋转矩阵来估计 box 角并且它是可微的,因此该函数将自动传回这些预测的目标特性。此外,谷歌使用了一个动态的 box 分类损失,它将与真值强烈重叠的 box 分类为正(positive),将与真值不重叠的 box 分类为负(negative)。下图为 ScanNet 数据集上的 3D 目标检测结果:
参考链接:https://ai.googleblog.com/2021/02/3d-scene-understanding-with-tensorflow.html▲点击上方卡片,关注我们
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
