
继 Facebook 开源 PyTorch3D 后,谷歌开源 TensorFlow 3D 场景理解库
转自:机器之心
【导语】:继 2020 年初 Facebook 开源基于 PyTorch 的 3D 计算机视觉库 PyTorch3D 之后,谷歌也于近日开源了一个基于 TF 框架的高度模块化和高效处理库 TensorFlow 3D。目前,该库已经开源。
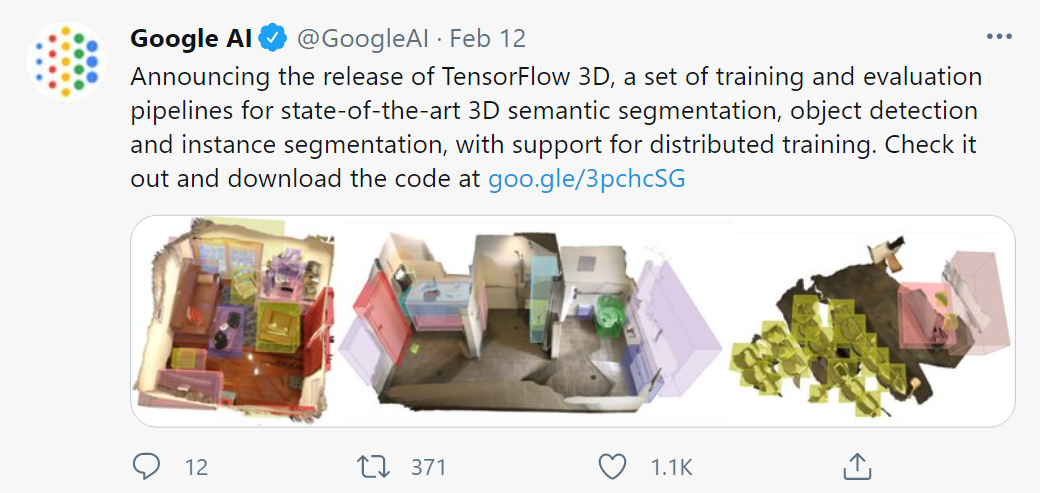
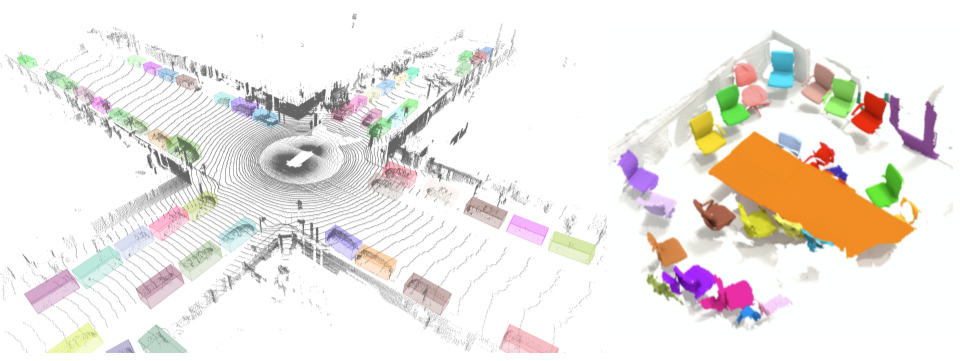


- EOF -
更多优秀开源项目(点击下方图片可跳转)



开源前哨
日常分享热门、有趣和实用的开源项目。参与维护10万+star 的开源技术资源库,包括:Python, Java, C/C++, Go, JS, CSS, Node.js, PHP, .NET 等
关注后获取
回复 资源 获取 10万+ star 开源资源
分享、点赞和在看
支持我们分享更多优秀开源项目,谢谢!
评论