
提速20倍!谷歌AI发布TensorFlow 3D
来源:新智元
编辑:LRS,LQ,小匀
随着自动驾驶汽车与机器人的深入发展,激光雷达、深度传感摄像机、雷达等3D传感器已经成为了获取道路数据的必要设备。
而利用这些传感器的机器学习系统则显得尤为重要,因为它可以帮助硬件在现实世界中进行导航等操作。
近期,包括目标检测、透明目标检测等模型的3D场景理解方面取得了很大进展,但是由于3D数据可用的工具和资源有限,这个领域仍面临挑战。
TensorFlow 3D:TensorFlow与3D深度学习合体
TensorFlow 3D:TensorFlow与3D深度学习合体
为了进一步提高对3D场景的建模,简化研究人员的工作,Google AI发布了TensorFlow 3D (TF 3D) ,一个高度模块化、高效的库,旨在将3D深度学习能力引入TensorFlow.
TF 3D提供了一系列当下常用的操作、损失函数、数据处理工具、模型和度量,使更多的研究团队能够开发、培训和部署最先进的3D场景理解模型。
TF 3D包含用于最先进的3D语义分割、3D目标检测和3D实例分割的培训和评估任务,还支持分布式训练。
另外,TF 3D还支持其他潜在的应用,如三维物体形状预测、点云配准和点云增密。此外,它提供了一个统一的数据集规范和训练、评价标准三维场景理解数据集的配置。
目前,TF 3D支持Waymo Open、 ScanNet和Rio数据集。
然而,用户可以自由地将其他流行的数据集,如NuScenes和Kitti,转换成类似的格式,并将其用于已有或自定义的pipeline模型中,还可以利用TF 3D进行各种3D深度学习研究和应用,从快速原型设计到部署实时推理系统。
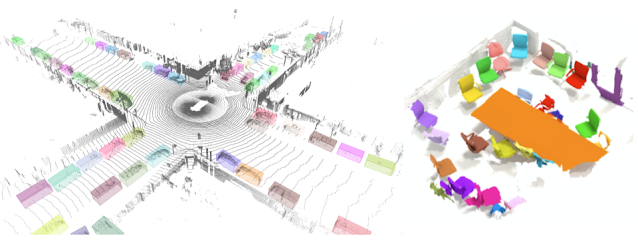 左边显示的是TF 3D中3D物体检测模型在Waymo Open Dataset的一帧画面上的输出示例。右边是ScanNet数据集上3D实例分割模型的输出示例。
左边显示的是TF 3D中3D物体检测模型在Waymo Open Dataset的一帧画面上的输出示例。右边是ScanNet数据集上3D实例分割模型的输出示例。
在这里,我们将介绍在TF 3D中提供的高效且可配置的稀疏卷积骨干,这是在各种3D场景理解任务中获得最先进结果的关键。
此外,我们将逐一介绍TF 3D目前支持的3个流水线任务: 3D语义分割、3D目标检测分割和3D实例分割。
3D稀疏卷积网络
3D稀疏卷积网络
传感器采集到的3D数据通常包含一个场景,该场景包含一组感兴趣的物体(如汽车、行人等),其周围大多是开放空间。所以,3D数据本质上是稀疏的。
在这样的环境中,卷积的标准实现将需要大量的计算、消耗大量的内存。因此,在TF 3D 中,我们采用了流形稀疏卷积(submanifold sparse convolution)和池操作,这些操作可以更有效地处理3D稀疏数据。
稀疏卷积模型是大多数户外自动驾驶(如Waymo,NuScenes)和室内基准测试(如 ScanNet)中应用的sota方法的关键。

谷歌还应用了各种CUDA技术来加快计算速度(如hash、在共享内存中分区/缓存过滤器以及使用位操作)。
在Waymo Open数据集上的实验表明,这种实现比预先设计好的TensorFlow操作要快「20倍」左右。

图源:Waymo Open Dataset on GitHub
然后,TF 3D使用3D流形稀疏U-Net架构来提取每个voxel的特征。通过让网络提取粗细特征并将它们组合起来进行预测,U-Net架构已被证明是有效的。
U-Net网络由编码器、瓶颈和解码器三个模块组成,每个模块都由许多稀疏卷积块组成,并可能进行池化或非池化操作。
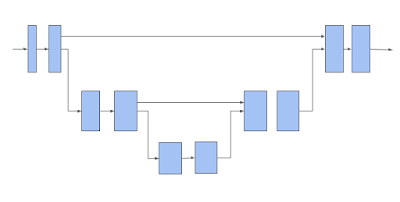
一个3D稀疏体素U-Net架构。注意,一个水平的箭头接收体素特征,并对其应用流形稀疏卷积。向下移动的箭头会执行流形稀疏池化。向上移动的箭头将收集池化的特征,与水平方向箭头的特征进行concat,并对concat后的特征进行流形稀疏卷积。
上述稀疏卷积网络是TF 3D提供的3D场景理解pipeline模型的backbone。
下面描述的每个模型使用这个骨干网络提取稀疏体素特征,然后添加一个或多个额外的预测头来推断感兴趣的任务。
用户可以通过改变编码器/解码器层数和每层卷积的数量来配置U-Net网络,并通过修改卷积滤波器的尺寸,从而能够通过不同的网络配置来权衡的速度和精度。
三维语义分割
三维语义分割
三维语义分割模型只有一个输出,用于预测每一个点的语义分数,将其映射回点,预测每一个点的语义标签。

从ScanNet数据集对室内场景进行3D语义分割。
三维实例分割
三维实例分割
在三维实例分割中,除了要预测语义,更重要的是将同一对象的体素组合在一起。
在TF 3D中使用的3D实例分割算法是基于用深度度量学习方法进行的2D图像分割工作。这种模型预测能预测每个体素的实例嵌入向量以及每个体素的语义评分。
实例嵌入向量将体素映射到一个嵌入空间,其中对应于同一对象实例的体素相距很近,而对应于不同对象的体素相距很远。
在这种情况下,输入是一个点云而不是一个图像,并且他将使用一个三维稀疏网络而不是一个二维图像网络。在推理过程中利用贪心算法选取实例种子,并利用体素嵌入的距离函数将不同的体素聚合到对应的实例上去。
三维目标检测
三维目标检测
目标检测模型可以预测每个体素的大小、中心和旋转矩阵以及对象的语义评分。
在推理时,推选机制将给出的多个候选框处理为少数几个精确的3D目标框。在训练时使用了预测与GT间的Huber Loss距离来计算损失。由于利用大小、中心和旋转矩阵估算框边角是可差分过程,损失可以自然地传递到预测过程的权重中。研究人员利用动态框分类损失来对预测的框进行正例和负例进行区分。

ScanNet数据集上的3D物体检测结果。
TF 3D只是市场上的3D深度学习扩展之一。2020年,Facebook推出了 PyTorch3D,专注于3D渲染和虚拟现实。另一个是英伟达的Kaolin,这是一个模块化的可分辨渲染的应用,如高分辨率模拟环境。
从这个概述来看,TF 3D应用程序似乎更专注于机器人感知和映射,而其他选项则更专注于3D模拟和渲染。为了实现3D渲染,Google推出了TensorFlow Graphics.
参考资料:
往期精彩:
点个在看