
在目标检测中如何解决小目标的问题?
作者:Nabil MADALI 编译:ronghuaiyang AI公园
本文介绍了一些小目标物体检测的方法和思路。
在深度学习目标检测中,特别是人脸检测中,由于分辨率低、图像模糊、信息少、噪声多,小目标和小人脸的检测一直是一个实用和常见的难点问题。然而,在过去几年的发展中,也出现了一些提高小目标检测性能的解决方案。本文将对这些方法进行分析、整理和总结。
图像金字塔和多尺度滑动窗口检测
一开始,在深学习方法成为流行之前,对于不同尺度的目标,通常是从原始图像开始,使用不同的分辨率构建图像金字塔,然后使用分类器对金字塔的每一层进行滑动窗口的目标检测。

在著名的人脸检测器MTCNN中,使用图像金字塔法检测不同分辨率的人脸目标。然而,这种方法通常是缓慢的,虽然构建图像金字塔可以使用卷积核分离加速或简单粗暴地缩放,但仍需要做多个特征提取,后来有人借其想法想出一个特征金字塔网络FPN,在不同层融合特征,只需要一次正向计算,不需要缩放图片。它也被应用于小目标检测,这将在后面的文章中讨论。
简单,粗暴和可靠的数据增强
通过增加训练集中小目标样本的种类和数量,也可以提高小目标检测的性能。有两种简单而粗糙的方法:
针对COCO数据集中含有小目标的图片数量较少的问题,使用过采样策略:
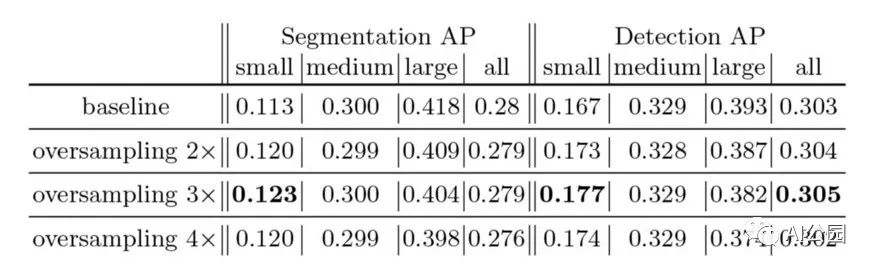
不同采样比的实验。我们观察到,不管检测小目标的比率是多少,过采样都有帮助。这个比例使我们能够在大小物体之间做出权衡。
针对同一张图片中小目标数量少的问题,使用分割mask切出小目标图像,然后使用复制和粘贴方法(当然,再加一些旋转和缩放)。

通过复制粘贴小目标来实现人工增强的例子。正如我们在这些例子中所观察到的,粘贴在同一幅图像上可以获得正确的小目标的周围环境。
在Anchor策略方法中,如果同一幅图中有更多的小目标,则会匹配更多的正样本。

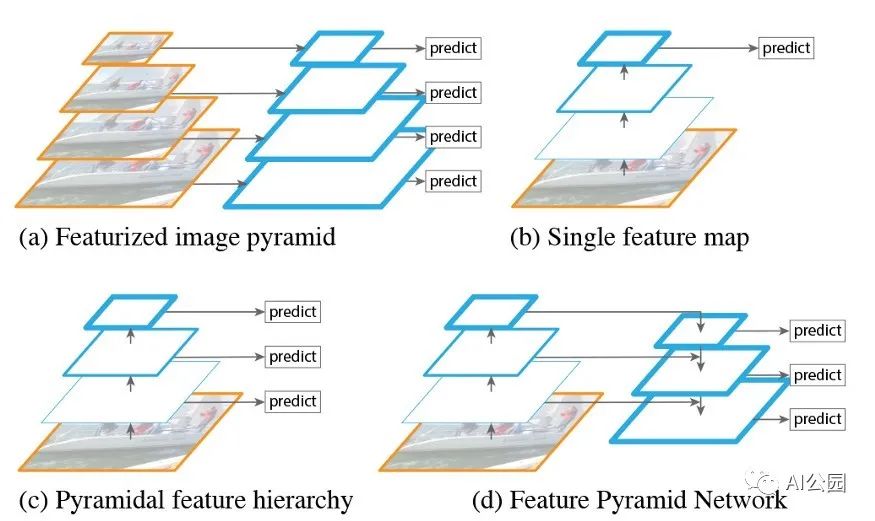
特征融合FPN
不同阶段的特征图对应不同的感受野,其所表达的信息抽象程度也不同。
浅层特征图感受野小,更适合检测小目标,深层特征图较大,更适合检测大目标。因此,有人提出将不同阶段的特征映射整合在一起来提高目标检测性能,称之为特征金字塔网络FPN。
由于可以通过融合不同分辨率的特征图来提高特征的丰富度和信息含量来检测不同大小的目标,自然会有人进一步猜测,如果只检测高分辨率的特征图(浅层特征)来检测小人脸,使用中分辨率特征图(中间特征)来检测大的脸。
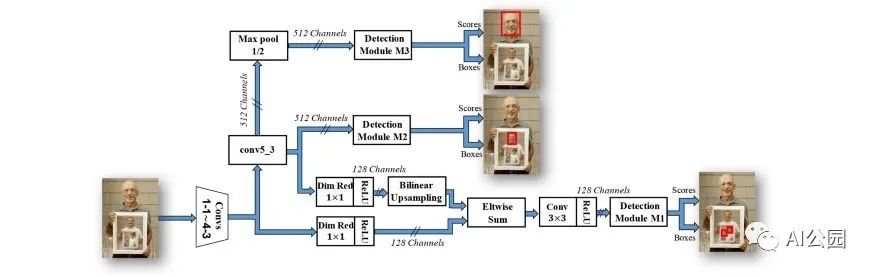
合适的训练方法SNIP, SNIPER, SAN
在机器学习中有一点很重要,模型预训练的分布应该尽可能接近测试输入的分布。因此,在大分辨率(如常见的224 x 224)下训练的模型不适合检测小分辨率的图像,然后放大并输入到模型中。
如果输入的是小分辨率的图像,则在小分辨率的图像上训练模型,如果没有,则应该先用大分辨率的图片训练模型,然后再用小分辨率的图片进行微调,最坏的情况是直接使用大分辨率的图像来预测小分辨率的图像(通过上采样放大)。
因此,在实际应用中,对输入图像进行放大并进行高速率的图像预训练,然后对小图像进行微调比针对小目标训练分类器效果更好。

更密集的Anchor采样和匹配策略S3FD, FaceBoxes
如前面的数据增强部分所述,将一个小目标复制到图片中的多个位置,可以增加小目标匹配的anchor数量,增加小目标的训练权重,减少网络对大目标的偏置。同样,在逆向思维中,如果数据集已经确定,我们也可以增加负责小目标的anchor的设置策略,使训练过程中对小目标的学习更加充分。
例如,在FaceBoxes中,其中一个贡献是anchor策略。
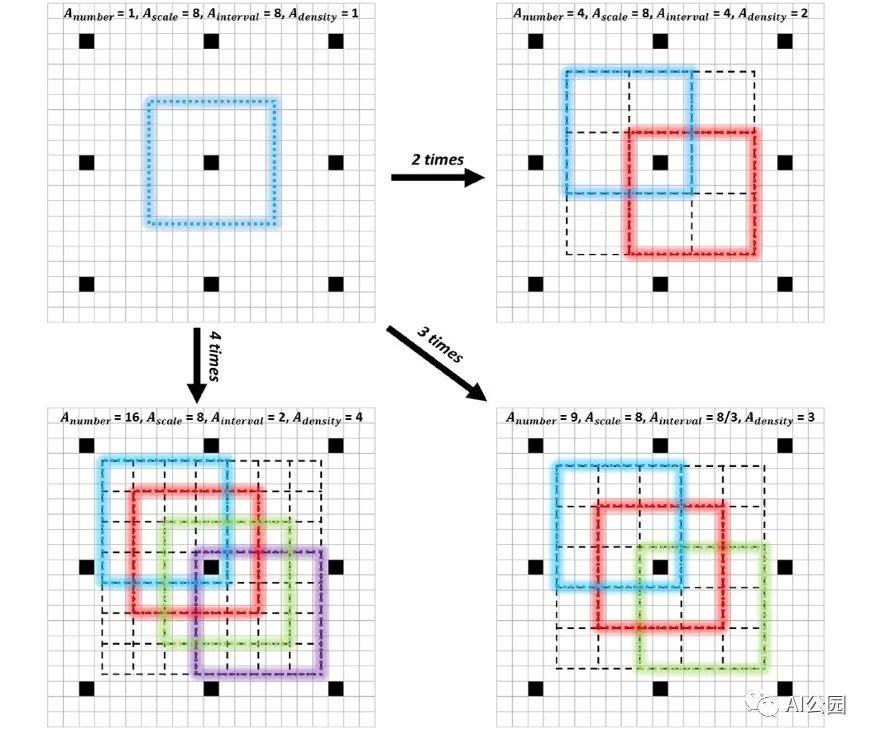
Anchor密集化策略,使不同类型的anchor在图像上具有相同的密度,显著提高小人脸的召回率。
总结
本文较详细地总结了一般目标检测和特殊人脸检测中常见的小目标检测解决方案。

英文原文:https://medium.datadriveninvestor.com/how-to-deal-with-small-objects-in-object-detection-44d28d136cbc
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!