
物体检测中的Objectness是什么?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自AI公园
作者:Nathan Zhao
编译:ronghuaiyang
在本文中,我们将讨论目标检测模型和Objectness的基础知识。
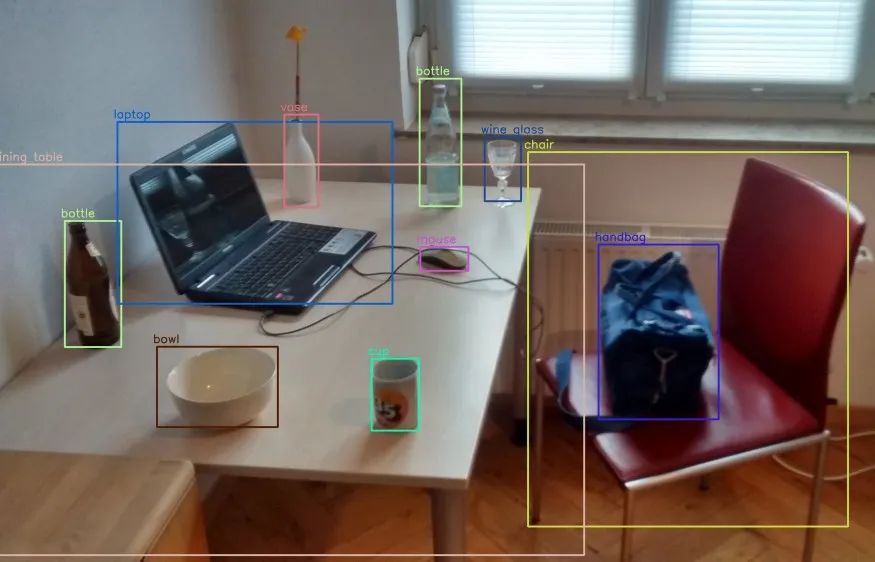
什么是物体检测模型?
物体检测模型本质上,正如其名称所示,检测物体。这意味着给定一个图像,它可以告诉你物体在哪里,以及这个物体是什么。例如,在上面的图像中,我们有许多物体,并且使用物体检测模型,我们已经检测出不同的物体在图像中的位置。
这类模型有很多应用。举几个例子,物体检测在以下方面很有用:
自动驾驶汽车,可以检测到乘客、其他车辆、红绿灯和停车标志。 安保,模型可以探测到公共区域的枪支或炸弹,并向附近的警察报警。
总的来说,这类模型非常有用,在过去几年里,机器学习社区已经对它们进行了大量的研究。
物体检测中区域建议的介绍
首先,让我们了解一下物体检测模型是如何工作的。首先,我们必须给出一个物体的建议位置。我们把这个建议的位置称为我们感兴趣的区域,通常显示在一个边界框(也称为图像窗口)中。根据物体检测模型的类型,我们可以通过许多不同的方式来实现这一点。
朴素方法:我们将图像分割成多个部分,并对每个部分进行分类。这种方法效率低下是因为必须对每个生成的窗口应用分类网络(CNN),导致计算时间长。
滑动窗口方法:我们预先确定好窗口比例(或“锚”),然后滑过图像。对于每个窗口,我们处理它并继续滑动。与朴素方法类似,这种方法生成的窗口较多,处理时间也比较长。
选择性搜索:使用颜色相似度,纹理相似度,和一些其他的图像细节,我们可以用算法将图像分割成区域。虽然选择性搜索算法本身是耗时的,但这使得分类网络的应用需求较少。
区域建议网络:我们创建一个单独的网络来确定图像中感兴趣的区域。这使得我们的模型工作得更快,但也使得我们最终模型的准确性依赖于多个网络。
上面列出的这些不同选项之间有一些区别,但一般来说,当我们加快网络的处理时间时,我们往往会牺牲模型的准确性。
区域建议机制的主要问题是,如果建议的区域不包含物体,那么你的分类网络也会去分类这个区域,并给出一个错误的标记。
那么,什么是Objectness?
Objectness本质上是物体存在于感兴趣区域内的概率的度量。如果我们Objectness很高,这意味着图像窗口可能包含一个物体。这允许我们快速地删除不包含任何物体的图像窗口。
如果一幅图像具有较高的Objectness,我们期望它具有:
在整个图像中具有唯一性 物体周围有严格的边界 与周围环境的外观不同

例如,在上面的图像中,我们期望红色框具有较低的Objectness,蓝色框具有中等的Objectness,绿色框具有较高的Objectness。这是因为绿色的框“紧密”地围绕着我们的物体,而蓝色的框则很松散,而红色的框根本不包含任何物体。
我们如何度量Objectness?
有大量的参数影响图像窗口的objectness。
多尺度显著性:这本质上是对图像窗口的外观独特性的度量。与整个图像相比,框中唯一性像素的密度越高,该值就越高。
颜色对比度:框内像素与建议图像窗口周围区域的颜色对比度越大,该值越大。
边缘密度:我们定义边缘为物体的边界,这个值是图像窗口边界附近的边缘的度量值。一个有趣的算法可以找到这些边缘:https://cv-tricks.com/opencv-dnn/edge-detection-hed/。
超像素跨越:我们定义超像素是几乎相同颜色的像素团。如果该值很高,则框内的所有超像素只包含在其边界内。

以上参数值越高,objectness越高。试着将上述参数与我们前面列出的具有高objectness的图像的期望联系起来。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~