
ICML 2021 大奖出炉!谷歌大脑摘桂冠,Hinton高徒获时间检验奖

新智元报道
新智元报道
来源:ICML
编辑:yaxin 好困 Priscilla
【新智元导读】刚刚,ICML 2021 杰出论文奖出炉!本次共有6篇论文获奖,来自多伦多大学和谷歌大脑的研究人员斩获杰出论文奖。时间考验奖颁给Hinton高徒郑宇怀,表彰10年前的经典论文,还有4篇获杰出论文提名奖,其中有两位上交大校友陆昱成和田渊栋。
就在今天,机器学习顶会ICML公布了2021年度的论文获奖名单!

本次大会共有6篇论文获奖,其中包括1篇杰出论文奖,4篇杰出论文提名奖,以及1篇时间检验奖。
来自多伦多大学和谷歌大脑的研究人员斩获杰出论文奖,Hinton高徒郑宇怀获时间检验奖。
ICML 2021是第38届年会,受疫情影响,本届会议在7月18日-7月24日采用线上会议的形式举行。
本届会议中,共有430多位华人论文入选ICML,西北大学汪昭然和普林斯顿大学杨卓然9篇论文入选,并列第一。

2021年ICML一共接收了1184篇论文,其中包含1018篇短论文和166篇长论文,接收率为21.48%,近五年最低。
在这1184份论文中,组委会精心挑选出了6篇论文,授予杰出论文奖、杰出论文提名奖和时间检验奖。
杰出论文
杰出论文
今年杰出论文奖的作者来自多伦多大学和Google Brain。

论文地址:http://proceedings.mlr.press/v139/vicol21a.html
作者指出,目前在一些计算图中优化参数的方法存在高变异梯度、偏差、缓慢更新或大量内存使用等问题。
因此,本文引入了一种Persistent Evolution Strategies(PES)的方法。
PES通过在整个序列中积累修正项来消除这些偏差,并允许快速更新参数,内存使用率低,无偏差,并且具有合理的方差特性。
实验证明,PES与其他几种合成任务的梯度估计方法相比具有优势,并适用于训练学习型优化器和调整超参数。
作者介绍

论文一作Paul Vicol,来自多伦多大学和Vector Institute机器学习小组的博士生。
主要研究领域为神经网络、贝叶斯推论、生成模型和强化学习,以及根据大脑工作原理改进神经网络等。
2016年,Paul Vicol在西蒙弗雷泽大学获得了计算机科学硕士学位,硕士研究侧重于信念变化,即一个知识表示领域,涉及根据新信息更新知识库,曾开发一个名为Equibel的Python包,能够让研究人员更容易在多智能体系统中试验信念变化。
2014年获得西蒙弗雷泽大学计算机科学学士学位。
Hinton高徒郑宇怀获时间检验奖,表彰10年前经典
Hinton高徒郑宇怀获时间检验奖,表彰10年前经典
时间检验奖(Test of Time Award)是颁给那些被时间和事后证明对机器学习界具有持久价值的论文。

Bayesian Learning via Stochastic Gradient Langevin Dynamics 获得了时间检验奖。
ICML 2021 时间考验奖颁给了2011年的一项研究,作者分别来自加利福尼亚大学的Max Welling(高通荷兰公司技术副总裁)和伦敦大学学院的Yee Whye Teh(郑宇怀,牛津大学教授)。

论文地址:https://icml.cc/Conferences/2011/papers/398_icmlpaper.pdf
值得一提的是,郑宇怀(Yee Whye Teh)可是深度学习三巨头之一Hinton的高徒,曾在2006 年与 Hinton 合著论文《A fast learning algorithm for deep belief nets》,引发了深度学习革命!
1997年他于加拿大滑铁卢大学获得计算机科学与数学学士学位,之后在多伦多大学师从Geoffery Hinton,并于2003年获得计算机博士学位。

杰出论文提名奖
杰出论文提名奖
杰出论文提名1 :分散训练中的最佳复杂度

论文地址:https://arxiv.org/pdf/2006.08085.pdf
作者提出,去中心化(Decentralization)是一种扩大并行机器学习系统规模的有效方法。为此,作者在随机非凸环境下为复杂的迭代提供了一个下界。
作者通过构造证明了这个下界是严格的和可实现的,同时作者还指出,现有的分散训练算法(如D-PSGD)在已知的收敛率和理论值上存在一定的差距。
作者进一步提出了gossip式分散算法DeTAG,该算法只需要一个对数间距就能达到下界。
作者将DeTAG与其他分散算法在图像分类任务上进行了比较,结果表明,DeTAG与基线相比具有更快的收敛性,尤其是在无数据混洗以及在稀疏网络的情况下。
作者介绍
杰出论文奖的获奖者是来自康奈尔大学的计算机科学专业博士陆昱成。

他在上海交通大学获得了电子工程的工程学学士学位。并且对建立可扩展和可证明正确的机器学习系统有广泛兴趣。
此外,陆昱成还发表过多篇顶会和期刊的论文。

杰出论文提名2 :离散分布的可扩展采样
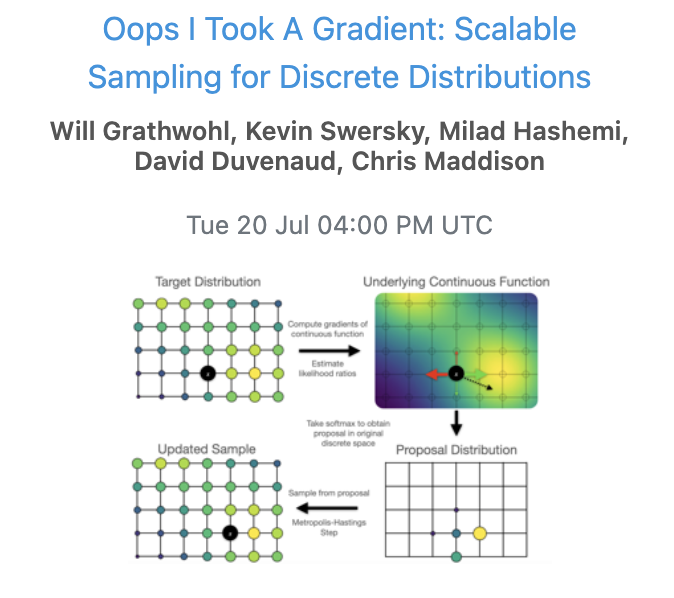
论文地址:https://arxiv.org/abs/2102.04509
针对具有离散变量的概率模型,作者提出了一种通用的、可扩展的近似采样策略。该方法利用似然函数与其离散输入的梯度,更新Metropolis-Hastings采样。
结果表明,结果表明,在如sing模型、Potts模型、受限玻尔兹曼机和隐马尔科夫模型等许多有难度的设定中,这种方法优于一般的采样器。
作者还展示了改进的采样器在高维离散数据上训练基于能量的深度模型(EBM)时的应用。这种方法的性能优于变异自动编码器和现有的基于能量的模型。
最后,作者表明该方法可在局部更新的采样器类别中接近最优。
作者介绍
论文一作Will Grathwohl,2014年在麻省理工学院取得了数学本科学位,如今是多伦多大学机器学习小组博士生,导师是Richard Zemel和David Duvenaud。
主要研究领域为生成模型,以及如何让模型更加灵活,并能够应用于下游判别任务。

2019年曾在Google Brain兼职。2021年夏季将完成博士学位,秋季将入职位于纽约的Deepmind。
曾获Borealis AI研究生奖学金、华为奖、ICLR 2018 Travel Award等奖项。
共参与发表19篇论文,其中包括顶会论文8篇。
杰出论文提名3 :理解非对比自监督学习动态

论文地址:https://arxiv.org/abs/2102.06810
自监督学习 (SSL) 的对比方法通过最小化同一数据点(positive pairs)的两个增强视图之间的距离,和最大化不同数据点(negative pairs)的视图之间的距离来学习表征。
最近BYOL和SimSiam的非对比自监督学习方法在没有negative pairs的情况下也能表现出卓越的性能。
作者受到简单线性网络中非线性学习动态的启发,提出了一种新方法DirectPred,它根据输入的统计数据直接设置线性预测器,而无需梯度训练。
同时,作者首次尝试分析非对比自监督学习训练的行为以及多个超参数的经验效应。
在ImageNet上,DirectPred的性能与使用BatchNorm的双层非线性预测器相当,并且在300个epoch的训练中比线性预测器强2.5%,在60个epoch的训练中强5%。

作者介绍
田渊栋,在上海交通大学计算机本科和硕士学位后,到卡耐基梅隆大学机器人研究所攻读博士学位。

博士毕业后加入了谷歌无人驾驶汽车项目组,现为Facebook人工智能研究院(FAIR)研究员、研究经理。
他曾获2013年ICCV马尔奖提名(Marr Prize Honorable Mentions )。
杰出论文提名4:利用张量链解决高维抛物线型PDEs

论文地址:https://arxiv.org/abs/2102.11830
由于传统的基于网格的方法往往受到维数灾难的影响,高维偏微分方程(PDEs)的数值处理面临着艰巨的挑战。
作者认为,张量链(Tensor Train)为抛物线型PDEs提供了一个可行的近似框架。通过反向随机差分方程和回归型方法,有望利用潜在的低秩结构,完成压缩和高效计算。
由此,作者提出了新的迭代方案,其中包括显式和快速或隐式和精确的更新。
实验证明,与基于SOTA神经网络的方法相比,该方法在准确性和计算效率之间得到了有效的权衡。
作者介绍
论文一作Lorenz Richter,本科和硕士均就读于德国柏林自由大学(Freie Universität Berlin),获得数学、心理学学士学位,数学硕士学位。

2017年在勃兰登堡工业大学攻读数学专业博士学位,将于今年博士毕业。
2018年创办了一家专门从事计算机视觉和遥感领域的软件项目实施公司dida Datenschmiede GmbH,现为公司CTO。
ICML 2021 华人作者入围情况
ICML 2021 华人作者入围情况
本届ICML 2021获奖论文中,华人作者约有430名,其中一作华人学生209名(据不完全统计)。
相较于去年,一作华人学生数量明显提升,2020年共118人。
据Aminer统计,华人作者投稿数量最多为9篇,来自西北大学汪昭然和普林斯顿大学杨卓然并列第一。

排在第二的是来自RIKEN 高级智能项目中心的Gang Niu,共有8篇论文入选。

第三名是来自斯坦福大学的Percy Liang,共有7篇论文入选(去年8篇,位列第一)。
再来看一作华人学生,来自得克萨斯大学奥斯汀分校的陈天龙位列第一,共有5篇论文入选。
谷歌一骑绝尘,北大31篇,实力碾压清华
谷歌一骑绝尘,北大31篇,实力碾压清华
根据谷歌AI Blog 统计,本次来自于 Google 的论文一共被收录了109 篇,位居所有企业与科研机构之首,足见其在机器学习的行业领军地位。
其次是MIT、斯坦福大学、伯克利、微软、卡内基梅隆大学,均超过50篇。
在国内,在接收的1184篇论文中,中国大陆高校和机构共占了166多篇。其中,北京大学31篇 ,清华大学26篇。
国内投稿最多的机构华为(14篇)、腾讯(10篇)、阿里巴巴(10篇)。
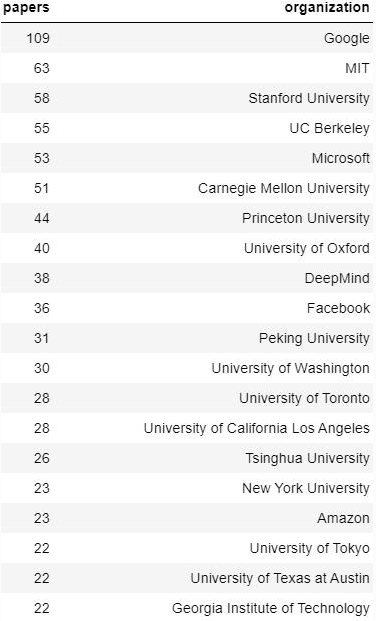
图源:网络(据不完全统计)
其他企业界收录情况(据不完全统计):
Facebook:共 36 篇论文被接收
Amazon:共 23 篇论文被接收
IBM:共 18 篇论文被接收
Apple:共 10 篇论文被接收
NVIDIA:共 8 篇论文被接收
参考资料:
https://icml.cc/virtual/2021/awards_detail
https://www.aminer.cn/conf/icml2021/roster http://blog.itpub.net/31562039/viewspace-2775694/
