
论文听读: ICML 2020 Hinton 提出自监督学习框架
〄 本音频由算法生成,请对照文字阅读。
今天介绍一篇由 Hinton 大佬在今年 ICML 会议上提出的工作。近年来人工智能吸引了大量资本的追捧,但也要求它能够落地。而当前能够落地的往往是监督学习,依赖大量的标注数据。然而,在实际中,很多应用场景是很难获得海量的标注数据,因此无监督学习将是大势所趋。
不管是计算机视觉、自然语言处理,还是其他应用领域,无监督学习一直在进步。例如,在计算机视觉领域,很多自监督学习方法被提出来用于学习图像的表示。虽然性能不断提升,但始终逊于监督方法。这篇论文提出的 SimCLR,虽然作为自监督学习方法,但在 ImageNet 分类上却超越了监督方法。这是怎么做到的呢?
1快速解读
我们可以回忆一下小时候认识这个世界的经历。对于出现在我们视野里的事物,一般不会有大量实例供我们学习,但我们能够轻易记住并识别它们。或许人脑有一套特殊的机制科学家还没发现,但有一点或许起着一定作用,那就是对比。
比如看到猫猫狗狗,不需要大量实例,我们就能区别它们。怎么做到的呢?不清楚,或许另外一点也在发挥着作用,那就是联想。人脑有很强的联想能力,即使是看到一张猫的静态照片,我们也可以发挥想象,得到一系列猫可能的样子,包括形状、大小和纹理等。
这对应于计算机来说,就是数据增强。但是我们不能把猫联想成老虎或者狮子啥的,因此需要有所限制,即保持一定相似性的数据增强。怎么给计算机增加这个限制呢?可以两两比较,同类间的相似性高于非同类间的相似性。接下来的任务就是设计具体的网络和损失函数,然后用数据去自监督训练。
以上是本号对这篇论文的简单解读,下面是对该论文的动机和算法细节的详细解读,花十分钟可以快速理解该论文的要点。

2引言
为了让计算机自监督学习,有必要想一下我们小时候是怎么学习的。记得小时候的课本上有这样的题目,

让小朋友看左边动物的图像,然后在右边找出同类。

这样的练习是为了让孩子通过对比更好地识别一个物体。那我们能用类似的方式来教机器学习物体的表示吗?
事实证明,我们可以通过一种所谓的对比学习来教会机器分辨相似和不同的物体。

3机器对比学习
要让机器学会对比学习,需要完成以下三件事,
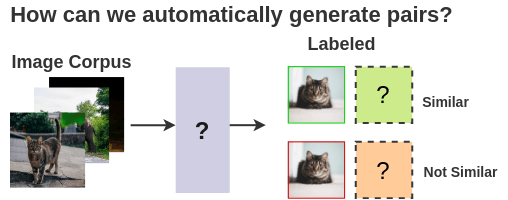
1 相似和非相似图像对
我们需要相似和非相似的图像样本对来训练模型。

监督学习需要人手动制作这样的图像对。为了实现算法自动化,我们可以利用自监督学习。但是我们如何表示它呢?
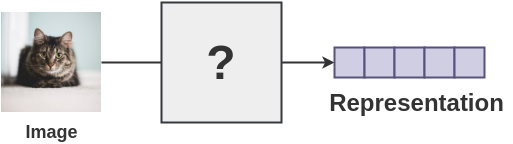
2 获得图像的表示
需要某种机制来让机器得到图像的表示。
3 量化图像对相似性
需要一个机制来计算两个图像的相似性。

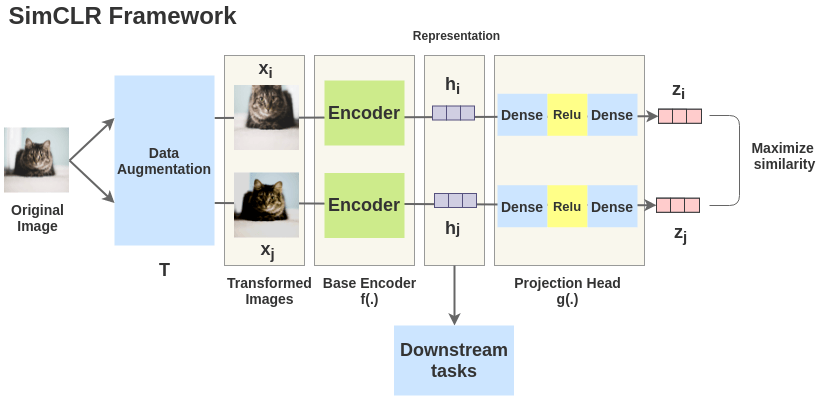
4SimCLR 框架
SimCLR 框架,正如全文所示,非常简单。取一幅图像,对其进行随机变换,得到一对增广图像
〄手把手例子
让我们通过一个示例来一探 SimCLR 框架的究竟。首先,我们有一个包含数百万未标记图像的训练库。

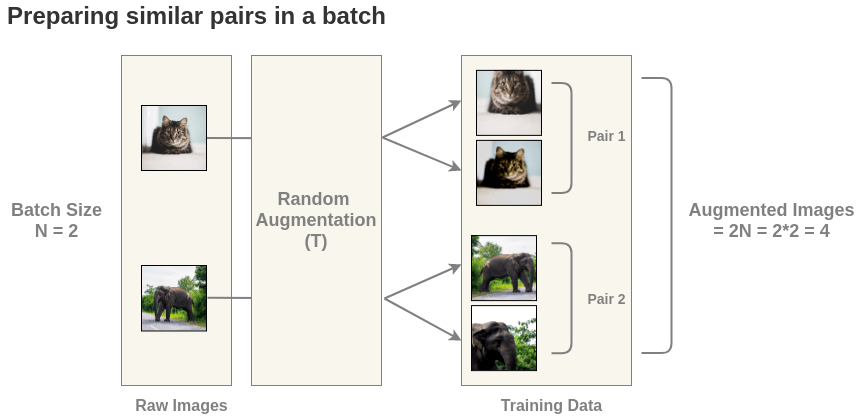
1、数据增强
首先,从原始图像集生成批大小为 N 的 batch。为了简单起见,我们取一批大小为 N = 2 的数据。在论文中,他们使用 8192 大小的 batch。

论文中定义了一个随机变换函数 random (crop + flip + color jitter + grayscale)。
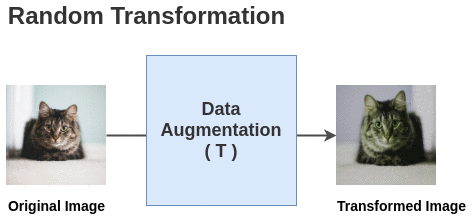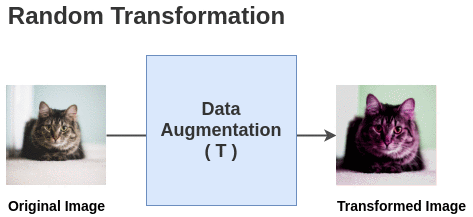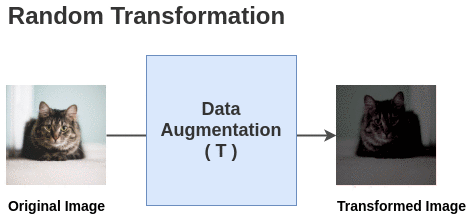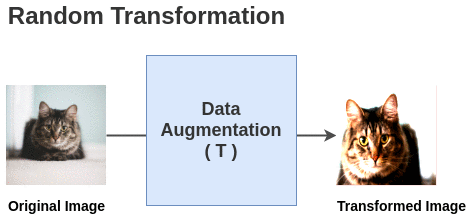
对于这个 batch 中的每一幅图像,使用随机变换函数得到一对图像。因为我们这里 batch 大小为 2,所以总共得到 2N = 4 张图像。
2、图像表示
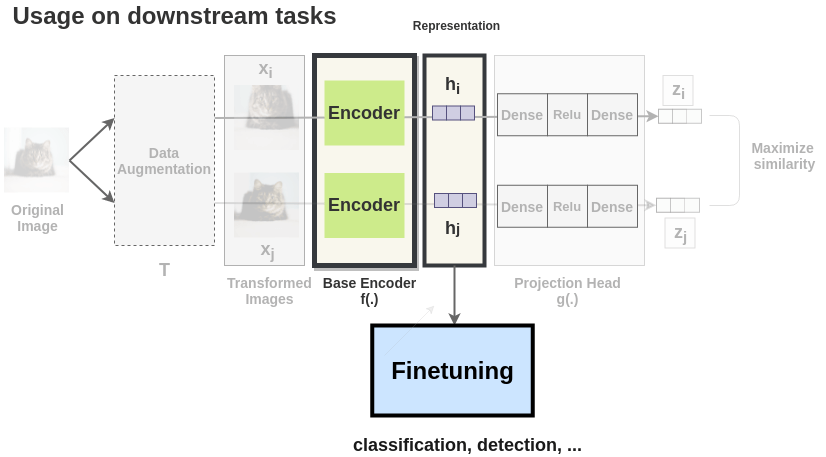
图像对中增强过的图像都通过一个编码器来获得图像表示。所使用的编码器是通用的,可用其他架构替换。下面显示的两个编码器权值共享,我们得到向量
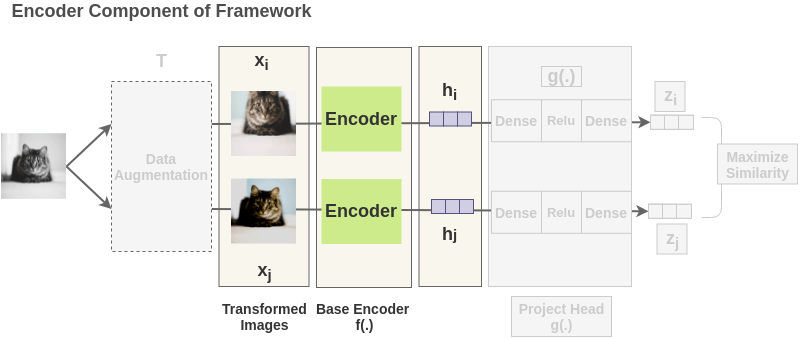
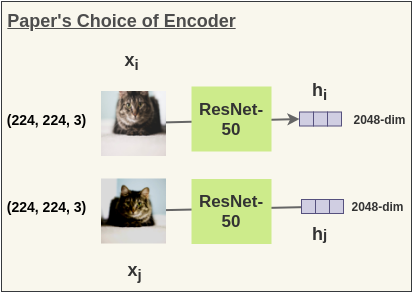
在文中,作者使用 ResNet-50 架构作为 ConvNet 编码器。输出是一个 2048 维的向量
3、投影头
两个增强图像的表示 Dense -> Relu -> Dense 作非线性变换,投影得到
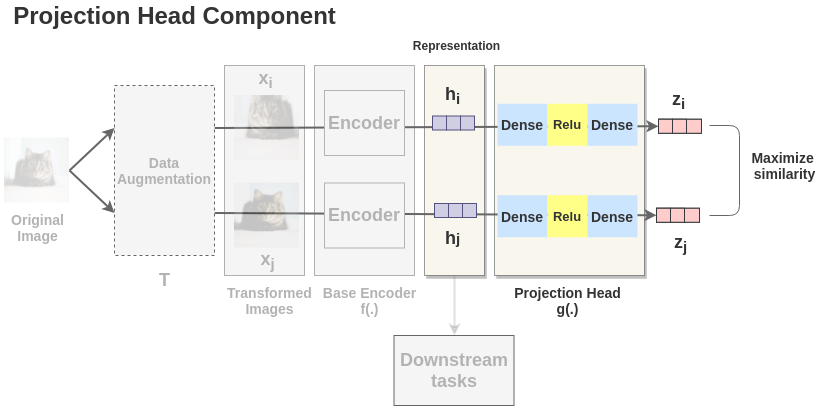
4、模型调优
对于 batch 中的每个增强图像,我们得到其嵌入向量

用这些嵌入计算损失,步骤如下:
现在,用余弦相似度计算图像的两个增强图像之间的相似度。对于两个增强的图像
其中
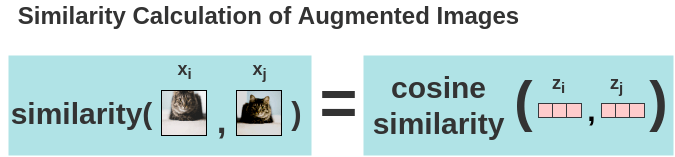
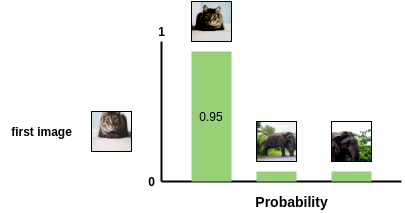
使用上述公式计算 batch 中所有增强图像两两之间的余弦相似度。如图所示,在理想情况下,增强后的猫图像之间的相似度会很高,而猫和大象图像之间的相似度会比较低。

SimCLR 使用了一种对比损失,称为 NT-Xent 损失。
首先,将 batch 的增强对逐个取出。

接下来,使用 softmax 函数来得到这两个图像的相似性概率。
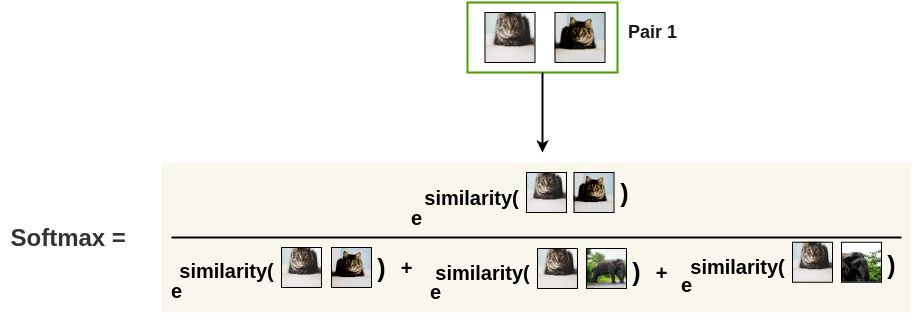
这个 softmax 计算在类似的情况经常见到,但这也是这个算法的巧妙之处。等后面最小化损失函数之后就知道了,这里相当于希望两张增强猫的图像具有最相似的概率。那么其他图像呢?与左边这张增强猫图像的相似概率不计算了吗?是的,这一点也比较重要,就是 batch 中所有其它图像都被为看成不相似的图像(负样本对),因此不需要像其它方法那样引入专门的架构。
然后,通过取上述计算的对数的负数来计算这个图像对的损失。这个公式就是噪声对比估计 NCE 损失,

在图像位置互换的情况下,我们再次计算同一对图像的损失。

最后,我们计算 N=2 的所有配对的损失并取平均值。
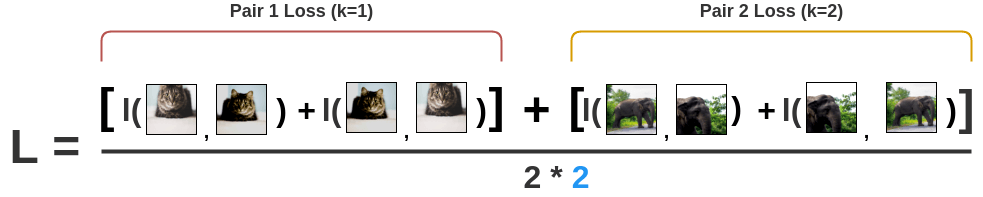
基于这种损失,编码器和投影头表示法会随着训练得到改善,最终使得相似图像的表示在空间中更接近。
〄下游任务
一旦 SimCLR 模型被训练在对比学习任务上,可以用于迁移学习。为此,使用来自编码器的表示,而不是从投影头获得的表示。得到的表示可以用在像 ImageNet 图像分类等下游任务上。
〄结果比较
论文声称 SimCLR 比之前 ImageNet 上的自监督方法更好。下图显示了在 ImageNet 上基于不同自监督方法学习表示训练的线性分类器的 top-1 精度。SimCLR 以粗体显示,灰色的
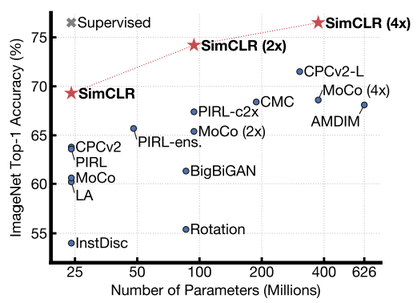
在
ImageNet ilsvrc-2012上,实现了 76.5% 的 top-1 准确率,比之前的 SOTA 自监督方法Contrastive Predictive Coding提高了 7%,与有监督的 ResNet50 相当。当训练 1% 的标签时,它达到 85.8% 的 top-5 精度,超过了 AlexNet,但使用的标签数据少了 100 倍。
思考: SimCLR 只是自监督学习了图像的表示,并没有直接识别分类,上面比较的线性分类器还是在一定程度上依赖监督学习。如果直接用 SimCLR 的编码表示再加 KNN 作无监督分类呢?
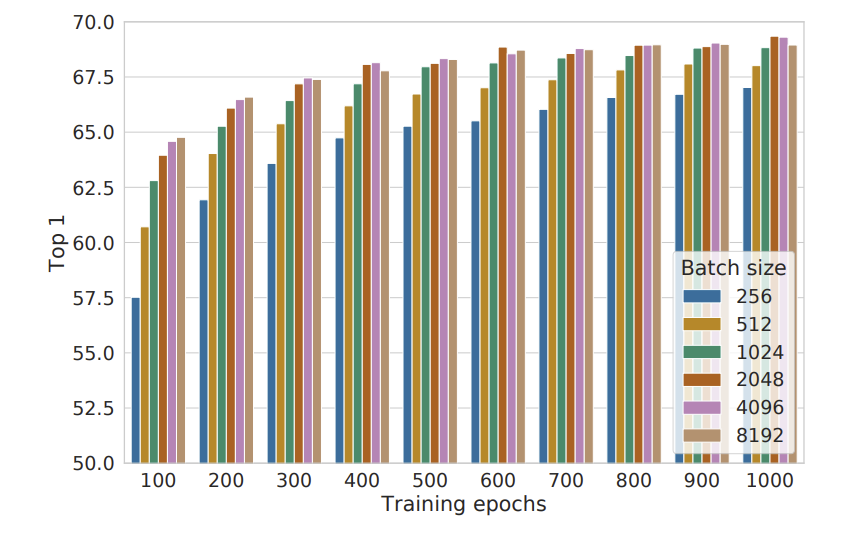
再看一下不同的 batch size 对性能的影响。简单理解就是对于对比学习来说,训练时 batch size 越大,一下子涉及的负样本数量就越多,越利于收敛。
〄SimCLR 代码
本文作者的 Tensorflow 官方实现版本放在 GitHub 上。他们还为使用 Tensorflow Hub 的 ResNet50 架构的 1 倍、2 倍和 3 倍变体提供了预训练模型[1]。
有各种非官方的 SimCLR PyTorch 实现,它们已经在小型数据集上测试过,比如 CIFAR-10[2] 和 STL-10[3]。
5小结
〄思 考 题
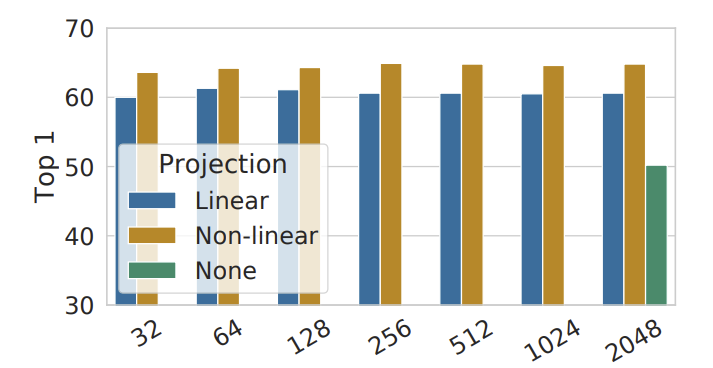
最后提一个问题,投影头将表示变换成投影表示,然后再用投影表示计算相似度。这个投影头起到什么作用呢?是不是必需的呢?文中的图 8. 给出了部分答案。
⟳参考资料⟲
预训练模型: https://github.com/google-research/simclr#pre-trained-models-for-simclrv1
[2]CIFAR-10: https://github.com/leftthomas/SimCLR
[3]STL-10: https://github.com/Spijkervet/SimCLR
[4]论文: https://arxiv.org/pdf/2002.05709.pdf
[5]代码: https://github.com/google-research/simclr
[6]参考1: https://amitness.com/2020/03/illustrated-simclr/
[7]参考2: https://zhuanlan.zhihu.com/p/107269105