
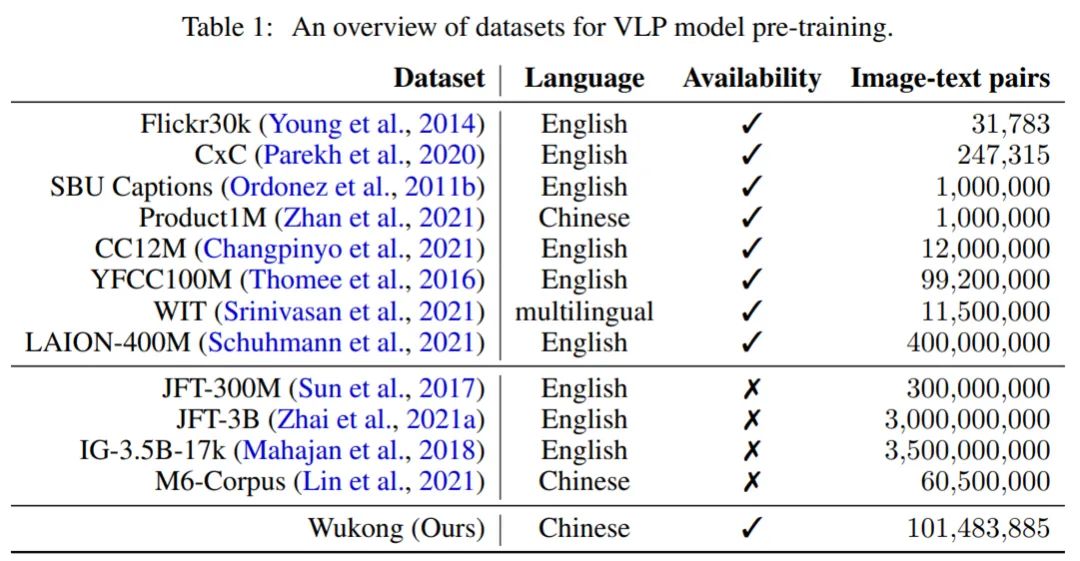
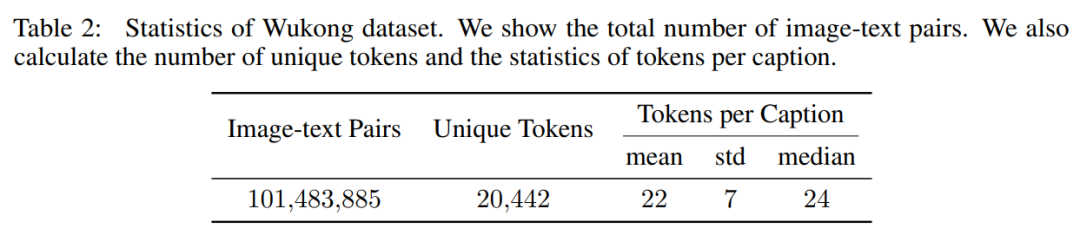
华为诺亚开源首个亿级中文多模态数据集-悟空,填补中文NLP社区一大空白
华为诺亚方舟实验室的研究者提出了一个大规模的中文的跨模态数据库 ——「悟空」,并在此基础上对不同的多模态预训练模型进行基准测试,有助于中文的视觉语言预训练算法开发和发展。

论文地址:https://arxiv.org/pdf/2202.06767.pdf
数据集地址:https://wukong-dataset.github.io/wukong-dataset/benchmark.html
发布了具有 1 亿个图文对的大规模视觉和中文语言预训练数据集,涵盖了更全面的视觉概念;
发布了一组使用各种流行架构和方法预训练好的大规模视觉 - 语言模型,并提供针对已发布模型的全面基准测试;
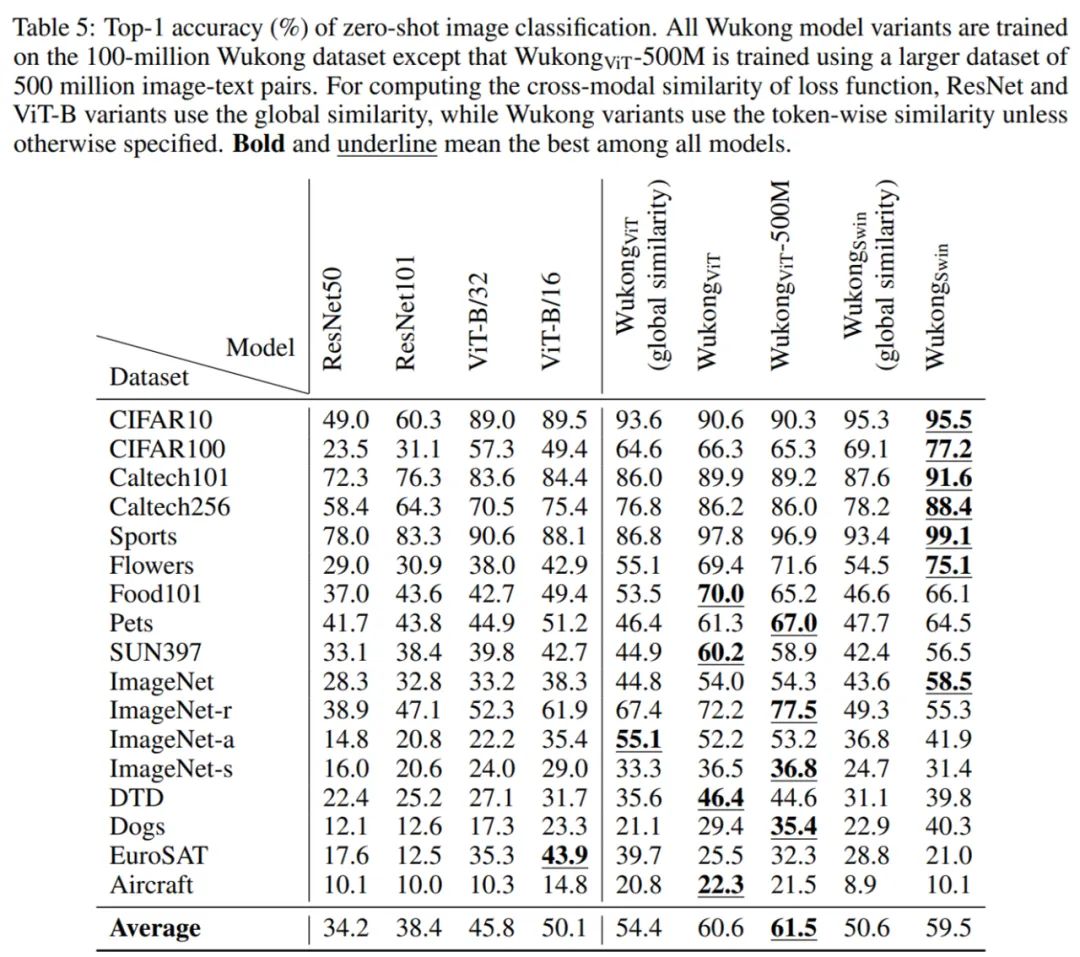
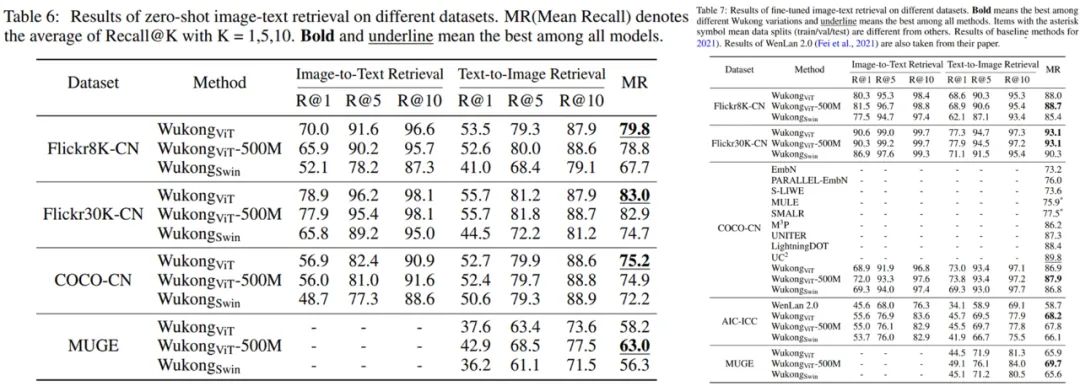
发布的预训练模型在数个中文基准测试任务,例如由 17 个数据集组成的零样本图像分类任务和由 5 个数据集组成的图像文本检索任务,表现出了最优性能。


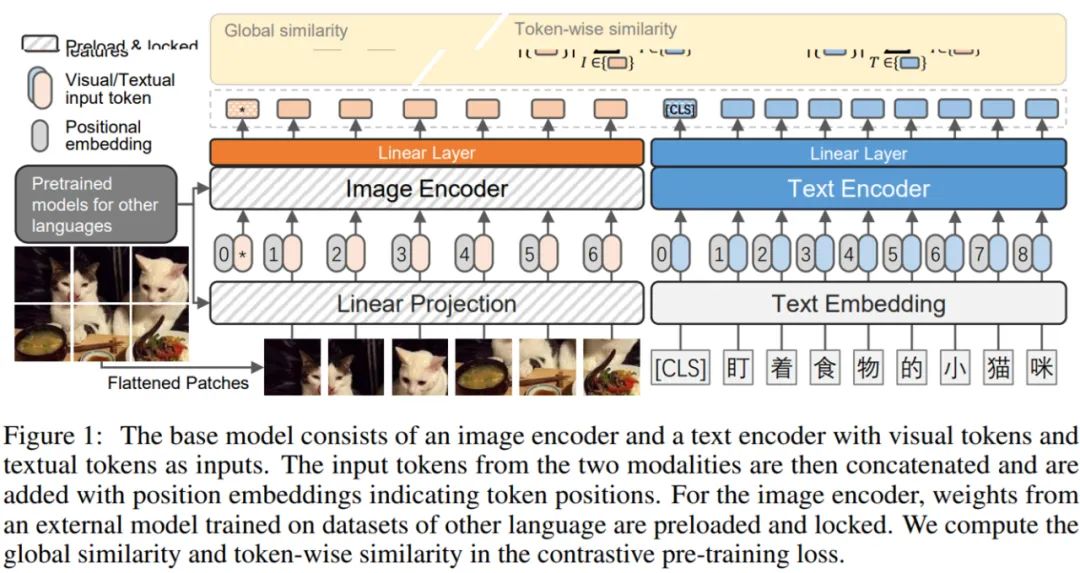
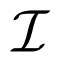 去定义图像样本集合,同时
去定义图像样本集合,同时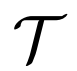 代表文本数据。给定一个图像样本
代表文本数据。给定一个图像样本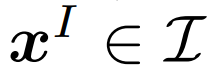 和一个文本样本
和一个文本样本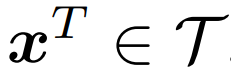 ,该模型的目标是让联合多模态空间中的配对的图像和文本表示接近,不配对的则远离。
,该模型的目标是让联合多模态空间中的配对的图像和文本表示接近,不配对的则远离。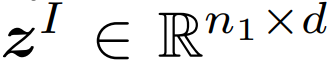 和
和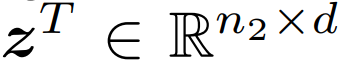 。这里,n_1 和 n_2 是每个图片和文本中的(未填充的)词 token 的数量。
。这里,n_1 和 n_2 是每个图片和文本中的(未填充的)词 token 的数量。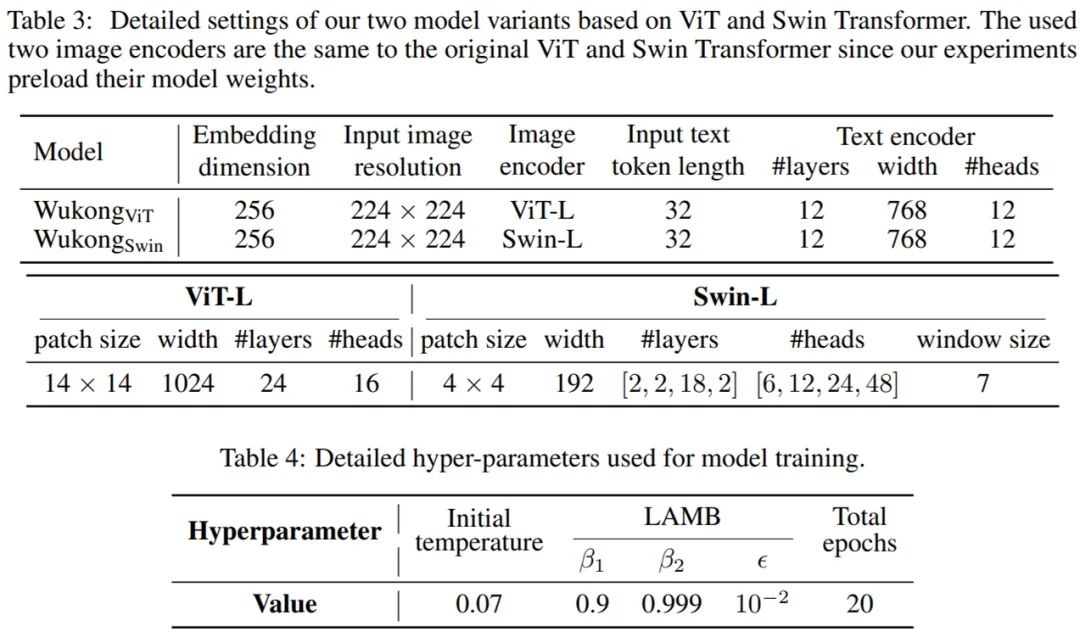

© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论