
基于OpenCV的面部关键点检测实战
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

这篇文章概述了用于构建面部关键点检测模型的技术,这些技术是Udacity的AI Nanodegree程序的一部分。
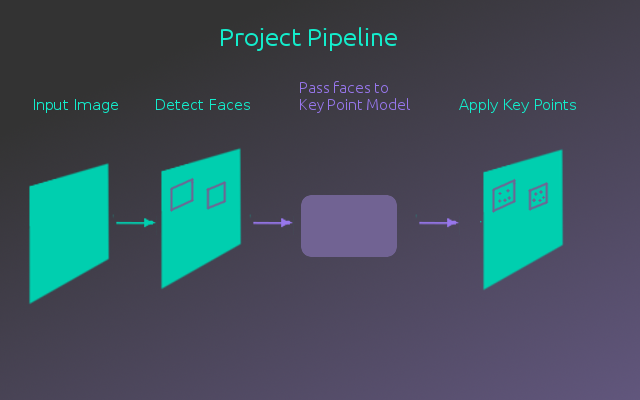
在Udacity的AIND的最终项目中,目标是创建一个面部关键点检测模型。然后将此模型集成到完整的流水线中,该流水线拍摄图像,识别图像中的任何面孔,然后检测这些面孔的关键点。
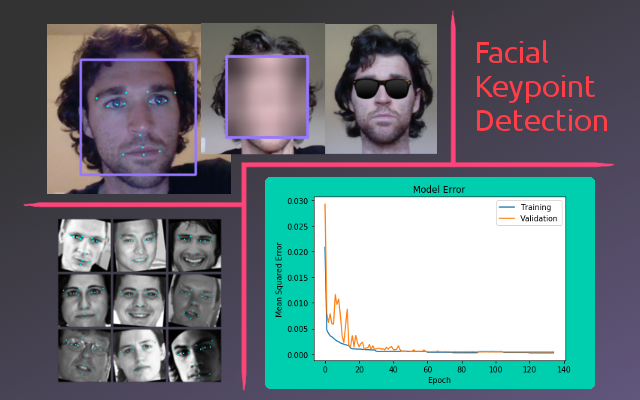
该项目的一部分是要熟悉OpenCV库。具体来说,是在预处理输入图像时使用它。在此项目中,它用于将图像转换为灰度并检测图像中的人脸。OpenCV的另一个有用功能是高斯模糊,可以用来隐藏检测到的面部的身份。下图显示了对图像应用面部检测和高斯模糊的结果。

使用OpenCV库中的面部检测器,然后可以裁剪图像中的面部,以将其输入到关键点检测模型中。
为了训练关键点检测模型,使用了具有相应关键点标签的面部数据集。该数据集来自Kaggle,由96个x 96灰度面部图像组成,带有15个(x,y)坐标标记了面部关键点。原始数据集包含7049张图像,但是并非所有图像都具有完整的15个关键点标签。为了解决这个问题,只使用了具有全部15个关键点的图像。剩下2140张图像,其中500张被分成了测试集。下图显示了数据集的样本。

使用相对较小的1640张图像训练集,可以以几种方式增强数据,以增加模型可以从中学习的示例图像的数量。由于不仅需要增强输入图像,而且还必须增强关键点标签,以便它们与新增强的图像上的相同点相匹配,这一点变得更具挑战性。应用了两种类型的扩充,概述此过程的代码可以在Jupyter笔记本项目中找到。
水平翻转—这是相对简单的。图像的x值和关键点反映在图像的中心。对应于脸部左侧的关键点被替换为相应的右关键点。这使训练数据增加了一倍。以下是水平翻转的示例。

旋转和缩放—旋转和缩放更具挑战性,但是由于使用了OpenCV,因此很容易构造一个可同时应用于图像及其关键点的旋转/缩放矩阵。将旋转/缩放后的数据集版本添加到普通数据集后,训练示例再次加倍。下面是这种扩充的一个示例。

扩充原始数据集后,该模型现在有6560个示例可以进行训练。
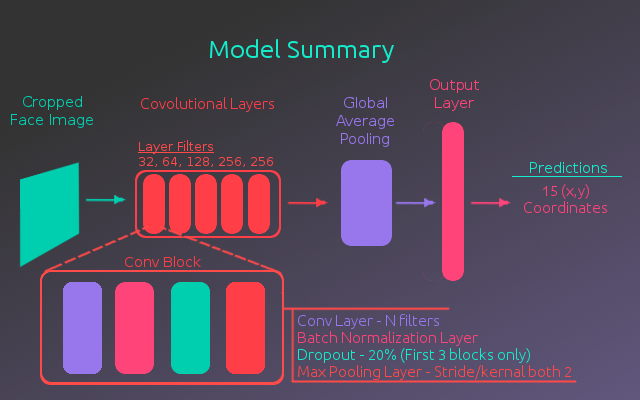
用于此模型的体系结构大致基于VGG16模型,该模型是为在ImageNet上进行分类而构建的卷积神经网络。VGG16模型使用5个卷积块从图像中提取特征。这些块由几个卷积层组成,后跟一个最大池化层,其中图像尺寸减小了一半。在用于该项目的模型中,每个卷积块只有一个卷积层。这样做的原因是,由于数据量有限,因此较简单的模型不太可能过拟合。
除了使用较少的卷积层之外,还将丢失层添加到前3个卷积块中,其丢失率为20%,并且在每个卷积层之后添加了批处理归一化层。最初的VGG16网络都缺少这两种更新的技术,有助于防止过度安装。
使用这种架构提取图像特征,将卷积层的输出馈送到全局平均池化层,然后馈送到30个节点(15个关键点中每个点的x,y值)的完全连接的输出层。下图说明了该模型的完整架构。
为了训练模型,使用标记的关键点和预测关键点的均方误差来计算损失。发现Adam优化器提供了最佳结果。还发现,通过提高批量大小和学习率可以实现最低的损失。从0.001的学习率开始,对模型进行了针对32、64和128批次大小的15个时期的训练。对于0.0001和0.00001的学习率重复此步骤。原因是批次数量较小时,梯度下降步骤更加随机(随机性更高),因为它是在较少的示例中进行平均的结果。当优化达到最小值时,参数步应代表更通用的解决方案,方法是采用较大批次大小的平均梯度来提供。
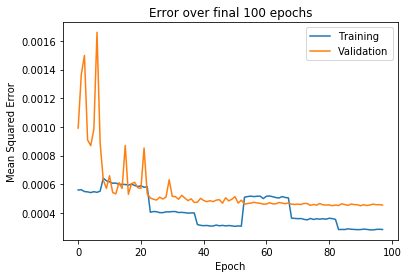
下图显示了训练曲线,后者显示了最后时期的近距离视图。如你们在最后时期所看到的,训练损失的步骤是由每种学习率的批量大小增加而产生的。
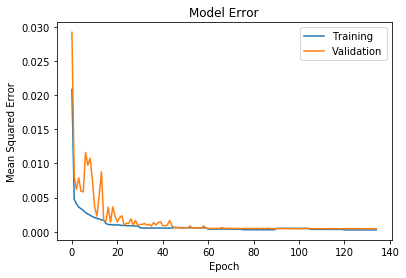
经过第一轮训练后,模型相对准确。为了利用原始数据集中的所有数据,使用经过训练的模型来预测缺失值的关键点并将其用作标签。本质上,数据集具有大量不完整的示例,这些示例被扔掉了,但它们仍然从确实存在的关键点那里获得有用的信息。为了从该信息中学习,模型以其最佳猜测填充了不完整的点。
以伪标签完整数据集并像以前一样对其进行扩充,使用29520个示例创建了一个新的训练数据集。然后,该模型继续对该数据集进行训练,然后再进行对原始的全标签数据集的另一轮训练。最终,模型误差被训练为低于0.0005。我们对此感到非常高兴,正如项目笔记本所述:“一个很好的模型将实现约0.0015的损失”。此外,当绘制在测试图像上时,关键点预测似乎位于你们期望的位置。
通过训练关键点检测模型,将面部检测器和模型组合起来,将关键点应用于图像中的面部。下图给出了此过程的示例产品。

此外,该模型已扩展为可与网络摄像头一起使用,并使用关键点功能应用蒙版滤镜(在这种情况下为太阳镜)。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~