
基于Clickhouse 的用户圈选实践
1. 背景
在伴鱼,我们努力了解我们的用户,旨在为用户提供更好的服务。APP 内容推荐,需要根据用户特征来决定推送内容;促销活动,需要针对不同的用户群体设计不同的活动方案;线上产品售卖,也需要了解用户喜好,才能更好地把产品卖给用户。
为此,我们搭建了用户画像平台。本文将首先探讨平台的功能需求、标签体系定位,随后介绍平台的架构和具体功能实现。
2. 功能
用户画像平台把重点放在了分析场景,使用方主要是公司各业务线的运营和数据分析同学。平台在一期主要支持以下几个功能。
定义标签:标签是用于描述用户的一个维度,例如「注册设备类型」、「常驻城市」、「年龄段」等。
人群圈选:指定一组用户标签和其对应的标签值,得到符合条件的用户人群。例如,找出「城市为北京,且设备类型为苹果」的用户。
用户画像:对于人群圈选结果,查看该人群的标签分布。例如,查看「城市为北京,且设备类型为苹果」的用户的年龄段分布。
3. 标签体系
确定完用户画像平台的使用场景和主要功能,我们再来倒推看用户标签体系。用户标签可以从两个维度进行分类:标签的实时性,和标签的值类型。
首先看标签的实时性。考虑到用户画像平台的主要功能是「人群圈选」和「用户画像查看」,而这两个功能都不需要非常高的实时性,那么实时标签的收益就不大,T+1 的非实时标签完全能满足数据分析和运营同学的需求。
再来看标签的值类型,即标签是枚举和还是非枚举的。枚举标签,顾名思义,就是指标签值可枚举的标签,例如 device_type, network_type, country, city 等,这类标签往往在人群圈选方面有较大作用。而非枚举标签,就是标签值可无限递增的标签,比如 active_days,register_date 等,这类标签大多会用来做用户信息展示。考虑到「人群圈选」是各业务线最迫切的需求,我们在一期舍弃了非枚举标签这个功能。
综上,我们就确定了用户画像平台的一期标签体系为非实时的枚举标签,主要满足「人群圈选」和「人群画像」这两个查询功能。
4. 架构与实现
在架构上,用户画像平台分为两个模块:数据写入,分析查询。
4.1 数据写入
数据写入模块为人群圈选和用户画像功能提供数据支持。具体流程分为两步。
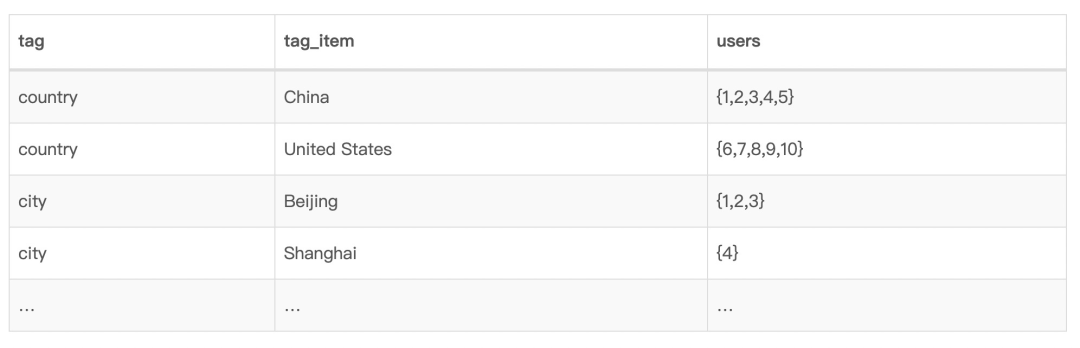
第一步,大数据团队完成每日标签计算后,得到一张 Hive 大宽表,如下表所示。表的每一行代表一个用户,每一列代表一个标签。

第二步,大数据团队将大宽表的数据「转置」后批量写入 ClickHouse,如下表所示。表中的每一行代表一个标签实例(即标签和标签值的组合),例如「city = Beijing」。此外,这一行同时存储了具有该标签值的所有用户的集合,服务于分析查询模块。
4.2 分析查询
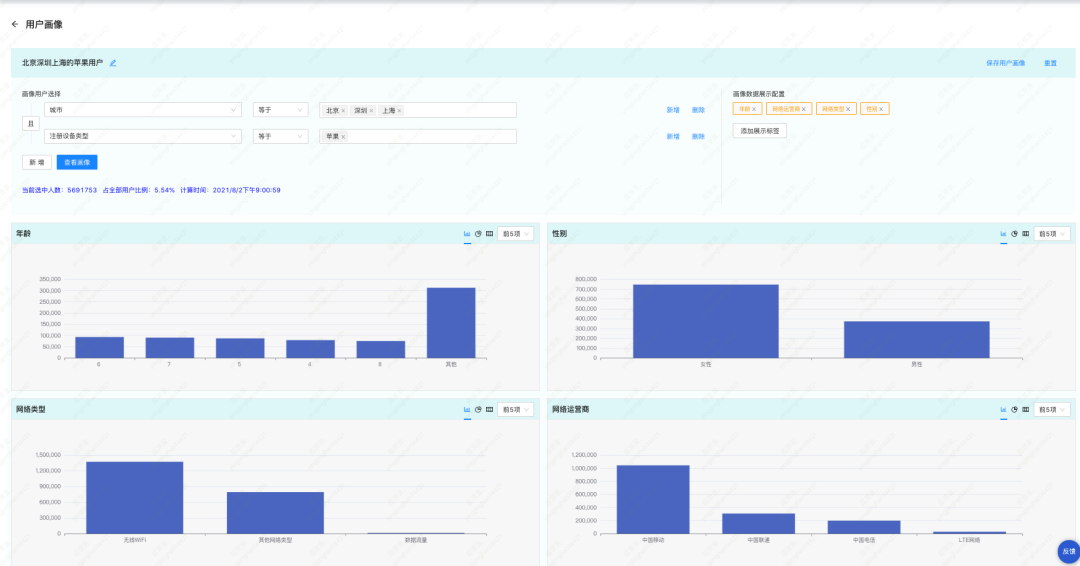
分析查询模块则实现了人群圈选和用户画像的查询。用户通过前端页面,进行标签、标签值、组合方式的勾选,后端将它们拼接为 SQL 语句,从 ClickHouse 中查询数据,展示给前端页面。例如,在下图中,我们圈选了属于北京、深圳、上海的苹果用户,并且按照年龄、网络运营商、网络类型、性别查看人群的分布情况。
不难看出,ClickHouse 在用户画像平台的数据存储和计算中起到了最关键的作用。下面,让我们一起来回答几个问题:
如何设计 ClickHouse 的表结构?
如何使用 ClickHouse 进行人群圈选?
如何使用 ClickHouse 查看人群画像?
4.2.1 设计 ClickHouse 表结构
根据使用场景,我们设计 ClickHouse 表结构如下:
CREATE TABLE analytics.user_tag_bitmap_local(`tag` String,`tag_item` String,`p_day` Date,`origin_user` UInt64,`users` AggregateFunction(groupBitmap, UInt64) MATERIALIZED bitmapBuild([origin_user]))ENGINE = ReplicatedAggregatingMergeTree('/clickhouse/tables/{shard}/analytics/user_tag_bitmap_local', '{replica}')PARTITION BY toYYYYMMDD(p_day)ORDER BY (tag, tag_item)SETTINGS index_granularity = 8192;
首先,看表的名称。表名包含 _local 后缀,即这是一个本地表,也存在一个对应的分布式表。我们使用「写本地表,读分布式表」的读写分离模式,具体原因可以参考《伴鱼事件分析平台:设计篇》的「如何高效写入 ClickHouse」一节。
然后,看表包含的字段。
tag代表标签, tag_item 代表标签值。因为在标签的圈选查询中,经常有tag = "city" AND tag_item = "beijing"的语句,我们将(tag, tag_item)作为主键,以提高查询效率。p_day代表数据写入的日期,也作为 ClickHouse 的分片键。因为每天的标签数据都是全量导入,p_day 不仅可以用来区分标签版本,也方便我们批量删除历史数据。origin_user是单个用户 ID。然而,相比单个用户的标签情况,我们更关心具有特定标签的用户人群。因此,我们使用users字段来表达根据origin_user聚合得到用户人群。为此,我们使用了 AggregatingMergeTree,它在原始数据插入后自动触发聚合,将具有相同 (tag, tag_item, p_day) 的数据聚合为一行。
最后,看表的存储引擎,我们使用了 ReplicatedAggregatingMergeTree 引擎。前文中我们提到 Aggregating 是用来聚合数据,而 Replicated 则是用来创建数据副本,对应双副本存储模式。
4.2.2 使用 ClickHouse 进行人群圈选
组合不同标签,圈选出最适合某个活动的用户人群里,是运营同学们较为关心的步骤。例如,我们想找出城市为北京、性别为女的用户。
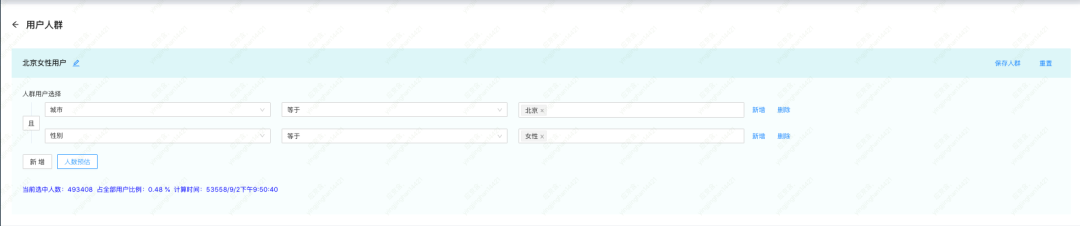 图注:用户人群查询
图注:用户人群查询
我们只需首先找到城市为北京的用户人群(用 bitmap 表示),然后找到性别为女的用户人群,然后对它们进行 AND 操作即可。具体查询如下:
WITH(SELECT groupBitmapMergeState(users)FROM user_tag_bitmap_allWHERE p_day = '2021_06_01' AND tag = 'city' AND tag_item = 'beijing') AS user_group_1,(SELECT groupBitmapMergeState(users)FROM user_tag_bitmap_allWHERE p_day = '2021_06_01' AND tag = 'gender' AND tag_item = 'female') AS user_group_2SELECT bitmapToArray(bitmapAnd(user_group_1, user_group_2))
其中,groupBitmapMergeState 函数对通过 WHERE 筛除得到的任意个数的 bitmap (users) 进行 AND 操作,而 bitmapAnd 只能对两个 bitmap 进行 AND 操作。
4.2.3 使用 ClickHouse 查看用户画像
再回到刚刚的例子,圈选得到「北京的女性用户」这一人群后,我们想知道,人群中有多少人在用苹果设备,而有多少人在用安卓。这类标签分布信息,就是我们所说的用户画像。
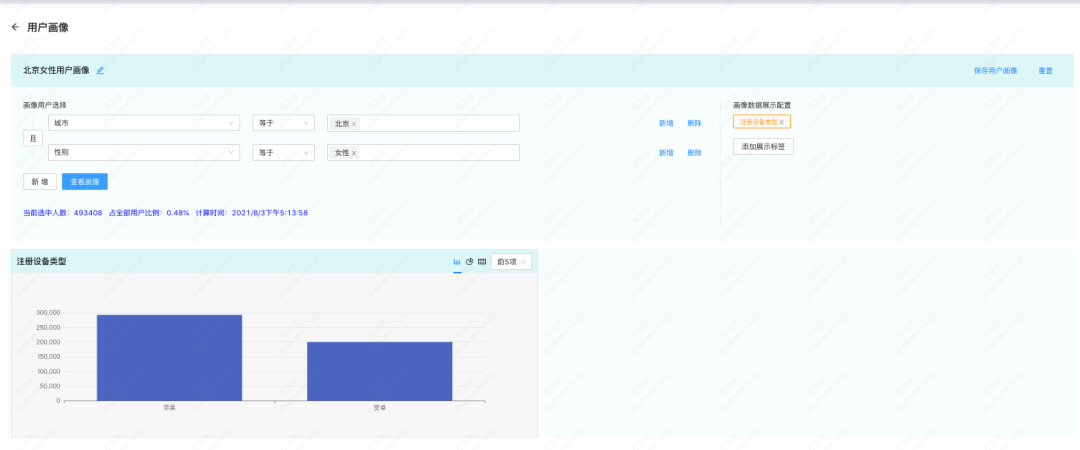 图注:用户画像查询
图注:用户画像查询
这个查询的实现同样是直观的。
我们采用和上一节一样的步骤,得到「北京的女性用户」这一 bitmap。
对人群进行分组,分别得到「设备为苹果的用户」和「设备为安卓的用户」的 bitmap。如果存在除了苹果和安卓之外的设备,我们这一步会得到更多的 bitmap。
将步骤 2 中的每一个 bitmap 与步骤 1 中的 bitmap 进行 AND 操作,就能得到「北京的女性用户」基于「设备类型」的分布情况。
具体的实现见下面的查询。
WITH(SELECT groupBitmapMergeState(users)FROM user_tag_bitmap_allWHERE p_day = '2021_06_01' AND tag = 'city' AND tag_item = 'beijing') AS user_group_1,(SELECT groupBitmapMergeState(users)FROM user_tag_bitmap_allWHERE p_day = '2021_06_01' AND tag = 'gender' AND tag_item = 'female') AS user_group_2,(SELECT bitmapAnd(user_group_1, user_group_2)) AS filter_usersSELECTbitmapCardinality(bitmapAnd(filter_users, group_by_users)) AS count,tag,tag_itemFROM(SELECTgroupBitmapMergeState(users) AS group_by_users,tag,tag_itemFROM user_tag_bitmap_allWHERE tag = "device_type"GROUP BY (tag, tag_item));
上述查询用到了一个没介绍到的函数 bitmapCardinality 。它的作用可以理解为计算 bitmap 中 1 的个数。