
最全的GC学习文章
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
需要有jvm内存模型的概念
什么是GC
GC就是垃圾回收,不是java独有的,甚至比java出现的还早
为什么要GC
像C语言是程序员自己管理内存的,很麻烦,java中自动GC,避免了OOM这种异常的出现,方便管理内存空间
GC的对象是什么
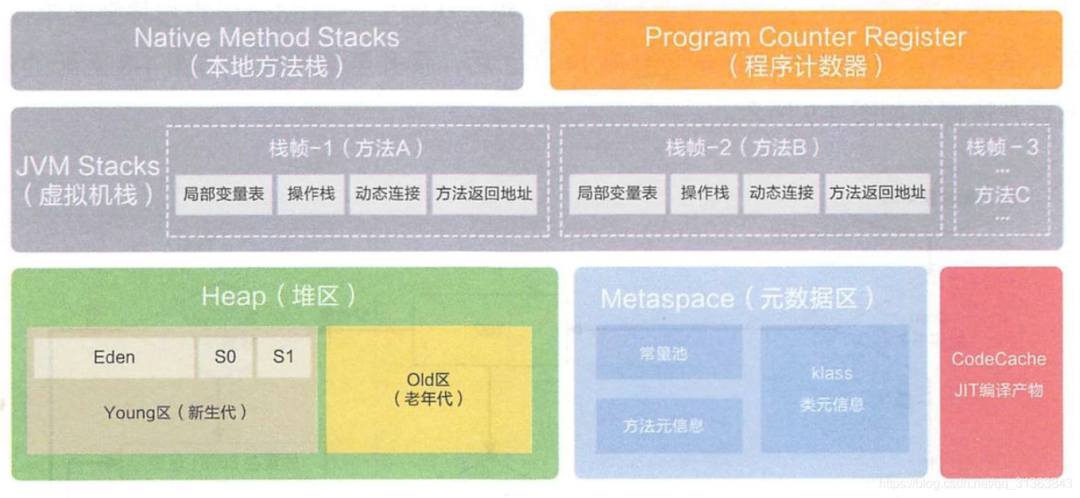
GC既然是管理内存的,也就和JVM挂了钩。而JVM中,并不是每一块空间都需要做GC的,不然太大了,而且也失去了瓜分内存模型的一大必要性。
GC的对象主要是JVM中的堆,部分虚拟机也对方法区中的废弃类废弃常量做回收,但主要还是堆。
因为本地方法栈、虚拟机栈、程序计数器等的内存要么是会随着线程进行,方法的入栈出栈等自动做回收的,要么就不需要回收。
而方法区的内存都是相对固定,因为存储的都是类或者方法的元数据信息,是一开始就定好的不会在运行中发生变化。
唯有堆里面是线程共享的对象,而且很动态,需要一套合理的GC规则来管理。
我们讨论的主要就是这个
GC线程
GC线程和业务线程显然是不能并行的,不然容易造成内存回收混乱
所以有了Stop-The-World–全局停顿的概念,也就是串行化,所有Java代码停止,native代码可以执行,但不能和JVM交互
如何确定一个对象为垃圾
引用计数法 Reference Counting
很好理解的一种算法,初衷就是,一个堆中的对象,没人引用就回收,有人引用就不回收。
具体的实现如下:

每当堆中的对象有一个引用的时候,引用就+1.当引用为0的时候,判断该对象为可回收的垃圾。
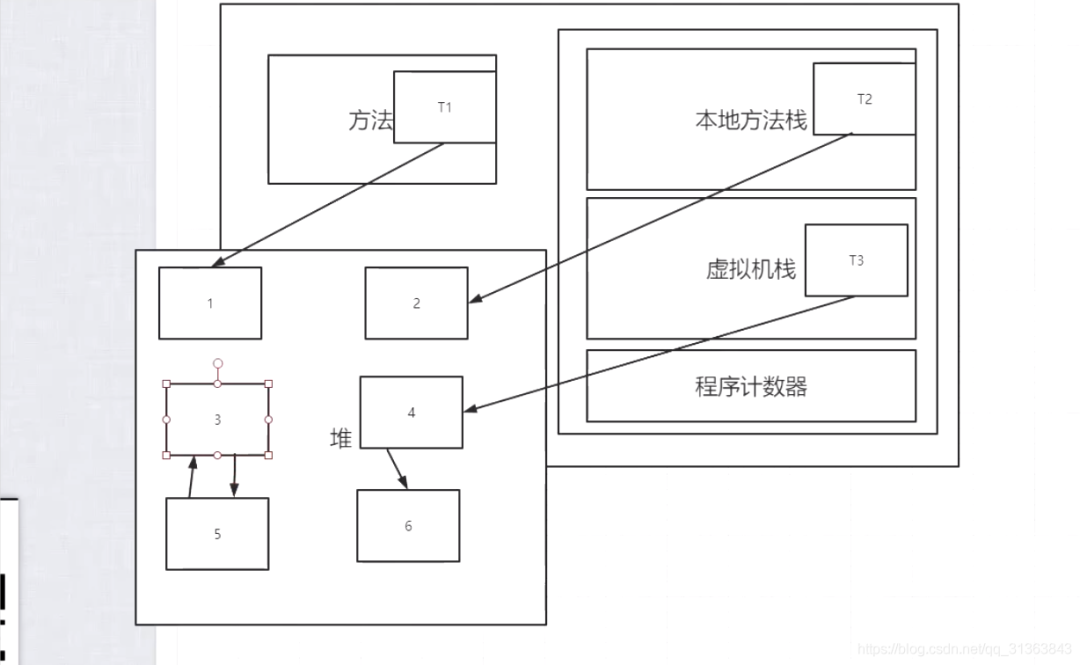
但是如果两个对象循环引用,比如下图中的实例1和实例2,这两个对象是无效的,但计数不为0无法回收,会发生内存泄漏
可达性分析算法/根搜索算法 GC Roots Tracing
吸取引用计数法的教训,不能做简单的引用数+1-1的操作
以一系列叫“GC Roots”的对象为起点开始向下搜索,走过的路径称为引用链(Reference Chain),当一个对象没有和任何引用链相连时,证明此对象是不可用的,用图论的说法是不可达的。那么它就会被判定为是可回收的对象。
如下图所示,这种算法下,只有1246这种直接被‘根’所引用的对象会判断为可达,35这种是不可达,可以被回收。
在Java语言中,可作为 GC Roots 的对象包括下面几种:
a. 虚拟机栈(栈帧中的本地变量表)中引用的对象。
b. 方法区中类静态属性引用的对象。
c. 方法区中常量引用的对象。
d. 本地方法栈中 JNI(Native方法)引用的对象
显然,堆中的引用是不具备这个资格的,解决了循环引用的隐患
java中的四种引用
既然判断一个对象是否该被回收是通过引用判断的,那么了解一下java中的引用
强引用,最常用的引用,只要这类引用还在,垃圾回收器就不会回收它指向的对象
软引用,如果快溢出了,先回收这部分引用指向的对象
弱引用,只要垃圾回收器工作,就会回收它
虚引用,无法通过这种引用获取对象实例,它的唯一作用就是,它指向的对象被回收的话,会收到一个通知。
当然,上述的引用计数法、可达性分析算法都是基于强引用的。
怎么回收一个对象
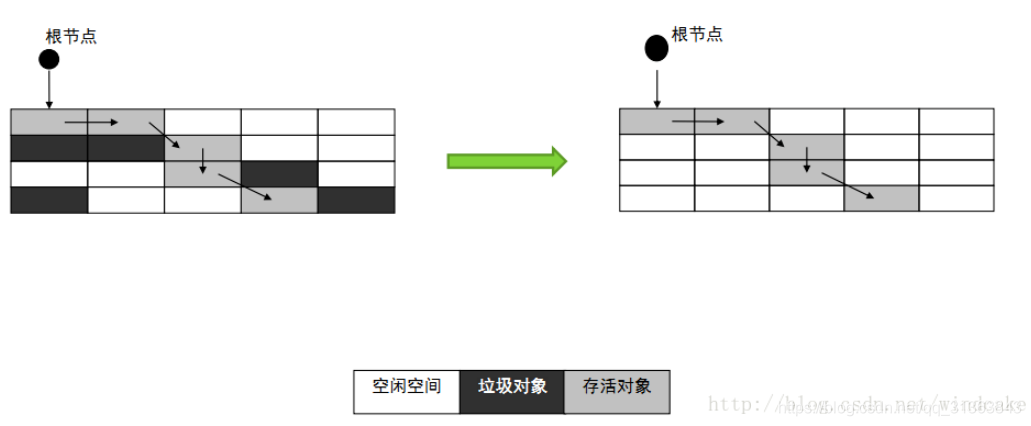
标记/清除算法 Mark-Sweep
这是一个最基本的GC算法。他根据根搜索算法,将所有可达对象都标记出来,然后对剩下的不可达对象做清楚。
但是有两个缺点,一个是标记和清除的效率都比较低,另一个是这样清除出来的空间过于碎片化,之后要分配一些比如数组之类的对象,可能会有影响。
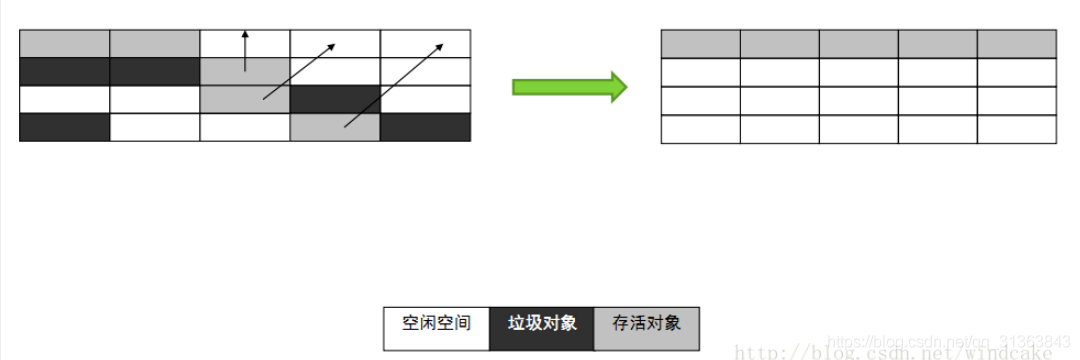
复制算法 Copying
复制算法是将内存分为等大的两块,每次用一块A,空一块B,在GC时,将存活的可达对象都挪到B,对A做一个整体的GC。
这种做法解决了内存碎片化的问题,但是造成了一半的内存浪费,而且复制的时候效率也不高。不适用于存活对象较多的内存

标记整理算法 Mark-Compact
标记整理算法可以看作结合了标记/清除算法和复制算法的思想,它的标记阶段和标记清除算法一样,但是标记完不做直接清除,而是将可达对象挪到内存的一侧,避免碎片化,然后再做GC。
或者叫标记-移动-清除算法也行
分代收集算法
分代算法是现在的JVM厂商使用的主流算法,它结合了上述的算法思想,扬长避短
对象刚创建出来是在新生代,年龄达到15(默认)后到老年代,这样根据对象的存活时间设置到不同区域,不同区域采用不同算法
对于新生代,对象刚创建基本都是在这里(除了某些内存特别大的,会直接到老年代),这些对象在每次GC的时候(新生代的GC又叫做YoungGC、MinorGC、YGC),只有少量存活,所以对存活的对象使用复制算法即可,成本较低。
新生代内又分三个区:一个 Eden 区,两个 Survivor 区(S0、S1,又称From Survivor、To Survivor),大部分对象在 Eden 区中生成。
具体复制,对象刚创建基本都在新生代的Eden区,当 Eden 区满时会进行一次YCG,YGC后还存活的对象将被复制到两个 Survivor 区(中的一个);当这个 Survivor 区满时,此区的存活且不满足晋升到老年代条件的对象将被复制到另外一个 Survivor 区。
对象每经历一次复制,年龄加 1,达到晋升年龄阈值后,转移到老年代。
在新生代中经历了 N 次垃圾回收后仍然存活的对象,就会被放到老年代,该区域中对象存活率高。老年代的垃圾回收通常使用“标记-整理”算法。
还有一点就是,新生代和Eden和s0、s1的大小一般是8:1:1,比如以一个大小为9的对象创建,是直接担保进入老年代的。

GC事件
根据垃圾收集回收的区域不同,垃圾收集主要分为:
Young GC
Old GC
Full GC
Mixed GC
Young GC
新生代内存的垃圾收集事件称为 Young GC(又称 Minor GC),当 JVM 无法为新对象分配在新生代内存空间时总会触发 Young GC。
比如 Eden 区占满时,新对象分配频率越高,Young GC 的频率就越高。
Young GC 每次都会引起全线停顿(Stop-The-World),暂停所有的应用线程,停顿时间相对老年代 GC 造成的停顿,几乎可以忽略不计。而且触发频繁,需要一种高效的回收算法。
Old GC 、Full GC、Mixed GC
Old GC:只清理老年代空间的 GC 事件,只有 CMS 的并发收集是这个模式。
Full GC:清理整个堆的 GC 事件,包括新生代、老年代、元空间等 。当老年代或者持久带满了,或者System.gc被显式的调用都会触发Full GC。
Mixed GC:清理整个新生代以及部分老年代的 GC,只有 G1 有这个模式
垃圾收集器
收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现

先说左边的
serial、parNew、Parallel Scavenage是年轻代收集器
下面的so、cms、po(简称)是老年代收集器
当然是可以组合使用的
比如JDK1.8用的就是PS+PO,这是一个吞吐量优先的组合
pn+cms则是响应时间优先的组合
serial和so都是单线程串行的,回收的时候要stop-the-world,基本被淘汰了
至于右边的
G1是包含了年轻代和老年代的收集器
ZGC是一个jdk11的试验品
Epsilon是一个调试工具
GC日志
GC日志是替换的不是追加的
通过以下的命令参数来设置GC日志的输出:
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:…/logs/gc.log 日志文件的输出路径
IDEA中查看GC日志
比如,拿2021版的最新的idea举例
新建一个demo:
/**
* @Author: luhui
* @Date: 2021/4/25 20:35
*/
public class GcDemo {
public static void main(String[] args) {
int _1m = 1024 * 1024;
byte[] data = new byte[_1m];
// data成为垃圾
data = null;
// 调用一次full gc
System.gc();
}
}
然后设置参数
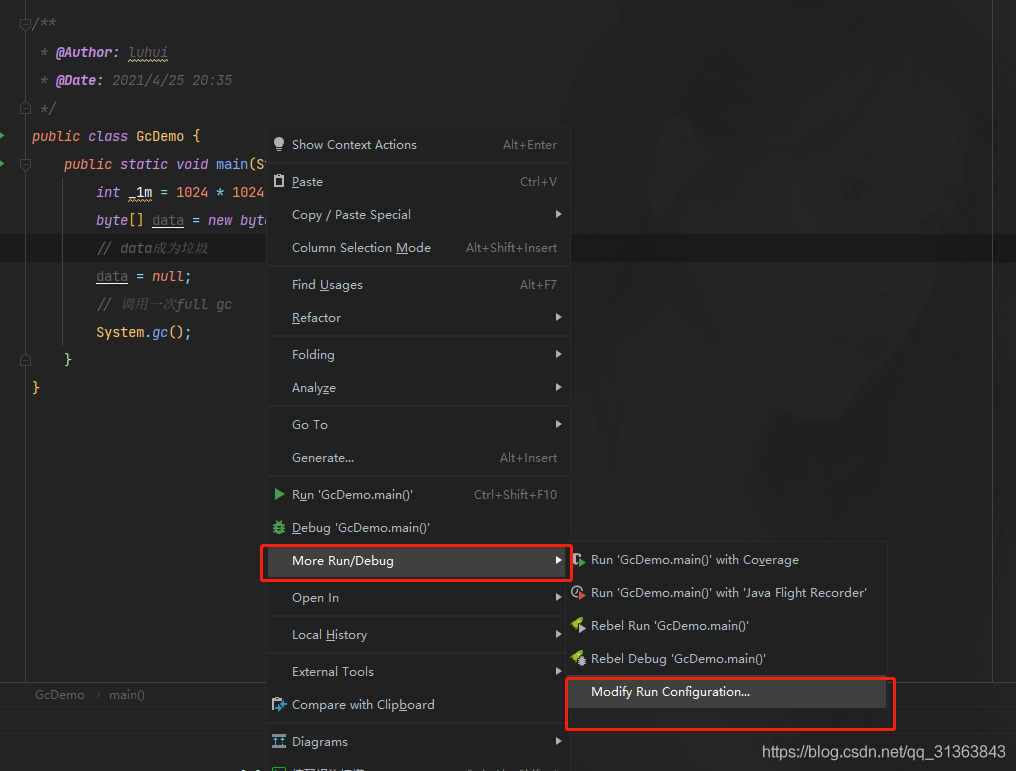

一开始没有填写VM参数的地方
点击左上角modify options,然后选择add VM options


就出现了。
之后我们运行demo,就会看到GC日志了

分析GC日志
[GC (System.gc()) [PSYoungGen: 6232K->960K(75776K)] 6232K->968K(249344K), 0.0013575 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 960K->0K(75776K)] [ParOldGen: 8K->747K(173568K)] 968K->747K(249344K), [Metaspace: 3074K->3074K(1056768K)], 0.0061529 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
=
[GC (System.gc())【发生了一次young gc】 [PSYoungGen: 【PS说明使用的收集器是Parallel Scavenage】 6232K->952K(75776K)]【年轻代内存从6232回收成952,总共75776】 6232K->960K(249344K),【这里是堆内存】 0.0675951 secs] [Times: user=0.00 sys=0.00, real=0.08 secs]
[Full GC (System.gc())【发生了一次full gc】 [PSYoungGen: 952K->0K(75776K)] [ParOldGen: 8K->753K(173568K)]【老年代】 960K->753K(249344K), [Metaspace: 3156K->3156K(1056768K)]【元空间,也就是方法区,jdk1.8前的永久代】, 0.0042467 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
这是系统最后的内存快照:
可以看到eden、from、to区域的大小和使用率等
Heap
PSYoungGen total 75776K, used 1951K [0x000000076ba00000, 0x0000000770e80000, 0x00000007c0000000)
eden space 65024K, 3% used [0x000000076ba00000,0x000000076bbe7c68,0x000000076f980000)
from space 10752K, 0% used [0x000000076f980000,0x000000076f980000,0x0000000770400000)
to space 10752K, 0% used [0x0000000770400000,0x0000000770400000,0x0000000770e80000)
ParOldGen total 173568K, used 753K [0x00000006c2e00000, 0x00000006cd780000, 0x000000076ba00000)
object space 173568K, 0% used [0x00000006c2e00000,0x00000006c2ebc400,0x00000006cd780000)
Metaspace used 3176K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 344K, capacity 388K, committed 512K, reserved 1048576K
GC日志分析工具
GC easy
http://gceasy.io/
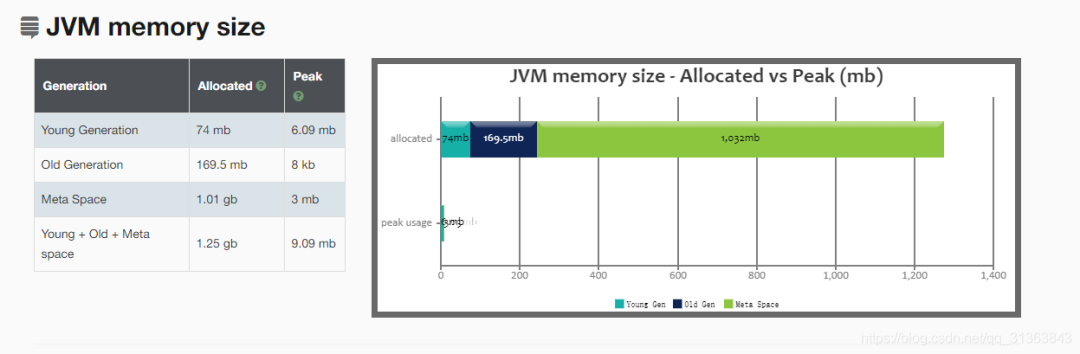
当然网页可以翻译成中文
GCViewer
github上有,自己下载启动
推荐GCEasy,毕竟在线的嘛,内存能省一点是一点
————————————————
版权声明:本文为CSDN博主「一袋米呦扛几楼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/qq_31363843/article/details/116136676
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 