
【Python】30个Pandas高频使用技巧
公众号:尤而小屋
作者:Peter
编辑:Peter
本文主要是介绍的自己在平时使用Pandas处理数据过程中接触到的高频技巧。以前的Pandas文章有对不同知识点的拆解,欢迎阅读。

Pandas连载文章
图解Pandas数据合并:concat、join、append
高频技巧
使用的技巧主要是下图涉及到的:

import pandas as pd
import numpy as np
导入文件
Pandas能够读取很多文件:Excel、CSV、数据库、TXT,甚至是在线的文件都是OK的

创建DataFrame
在以前的文章中介绍过10种DataFrame的方法

查看头尾数据
头尾都是默认5行数据,可以指定行数
# df2.head() 默认头部5行
df2.head(3) # 指定3行
# df2.tail() 默认尾部5行
df2.tail(2) # 指定尾部2行
显示全部列名

显示索引

查看列的数据类型

查看行列数

查看数据大小
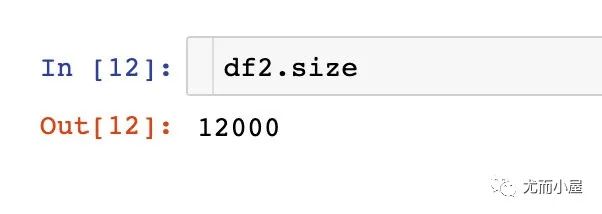
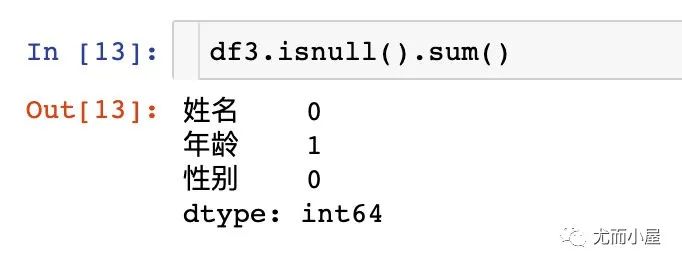
查看缺失值
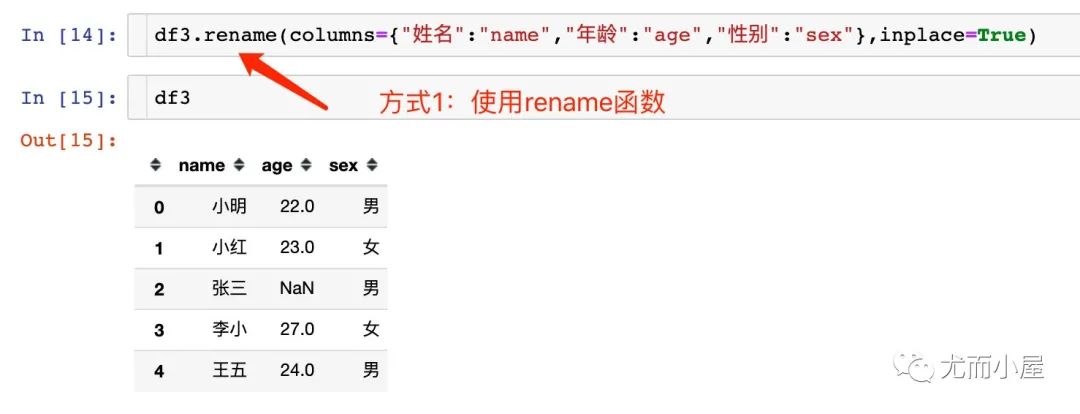
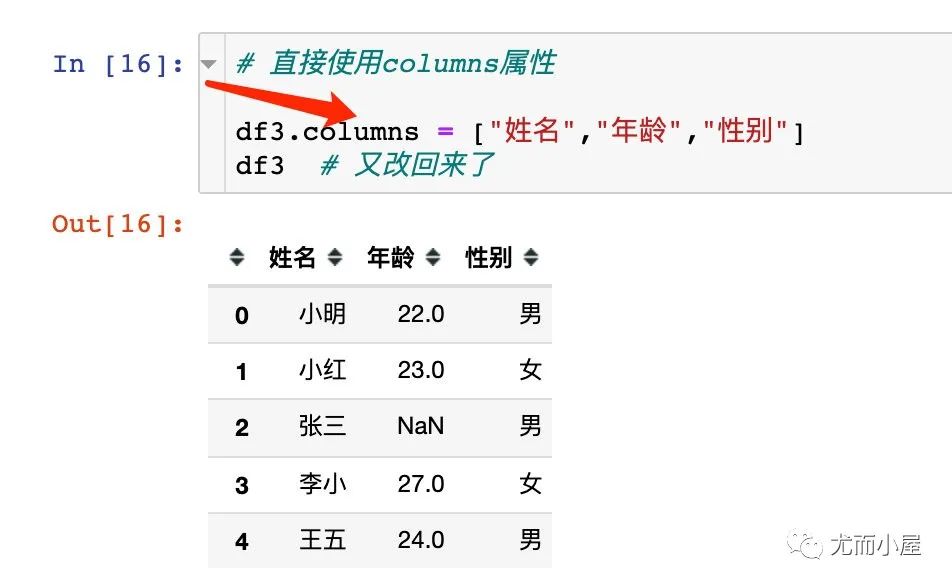
修改列名
两种方式:使用rename函数和直接使用columns属性
统计元素
统计每个元素的个数

转成列表数据

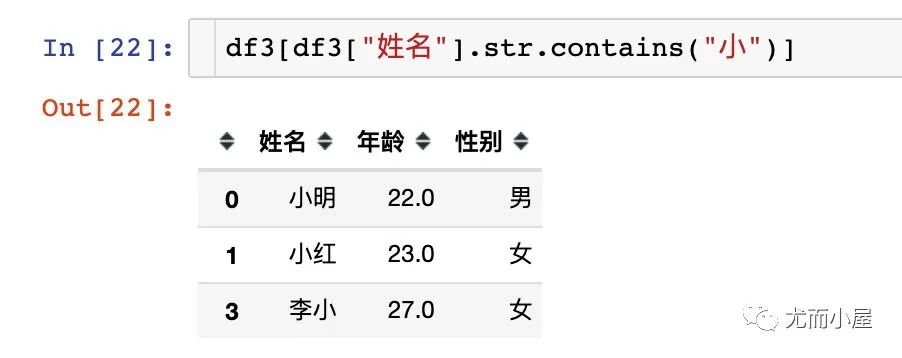
提取列中数据
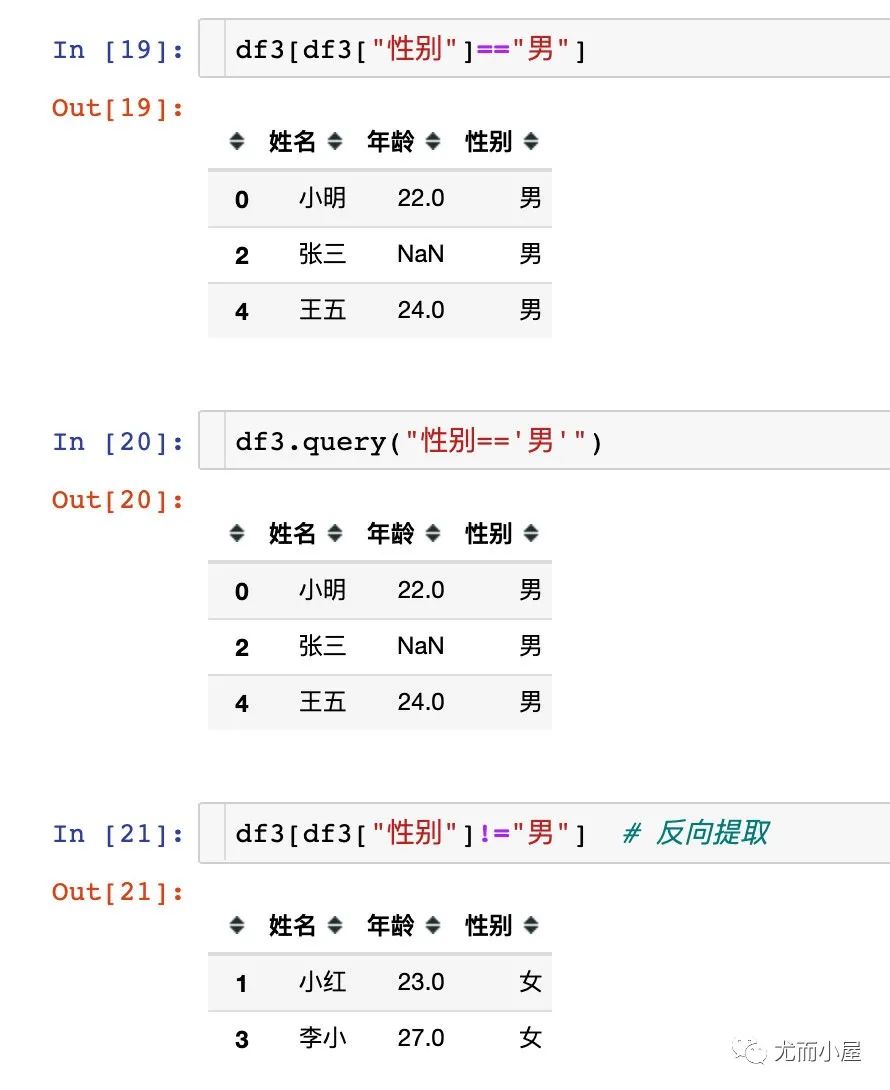
提取文本数据
数值范围数据提取

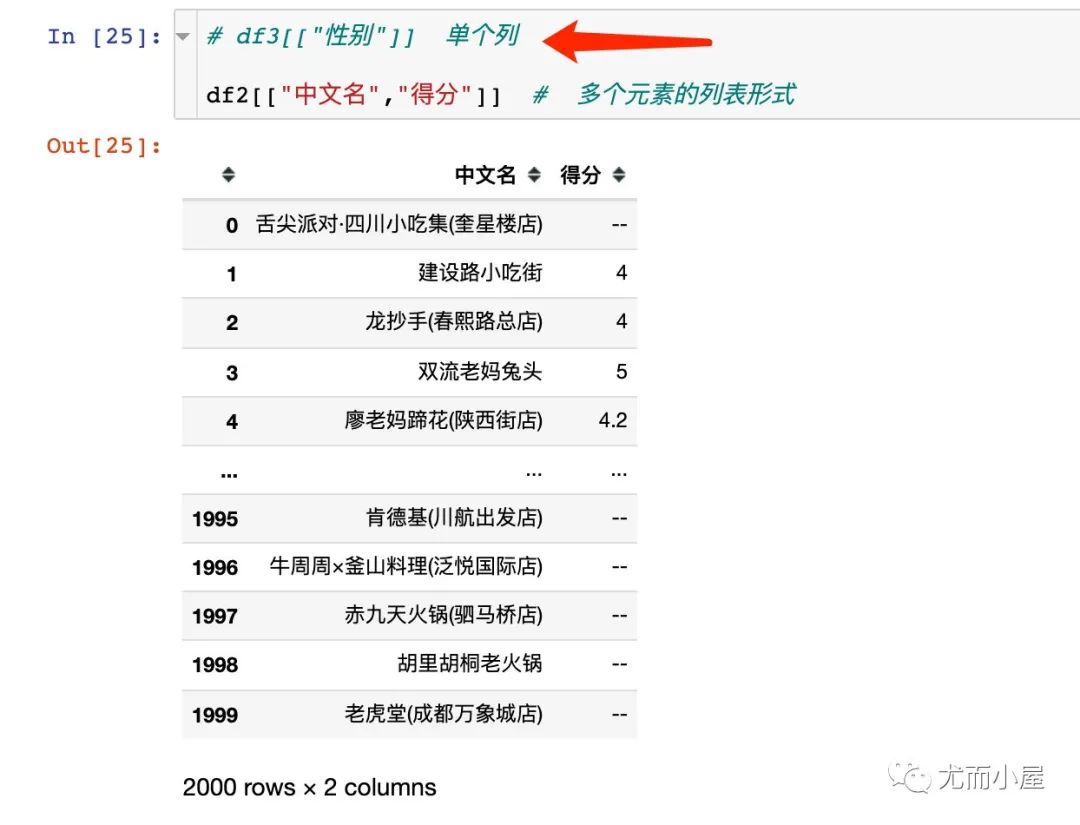
提取整列数据
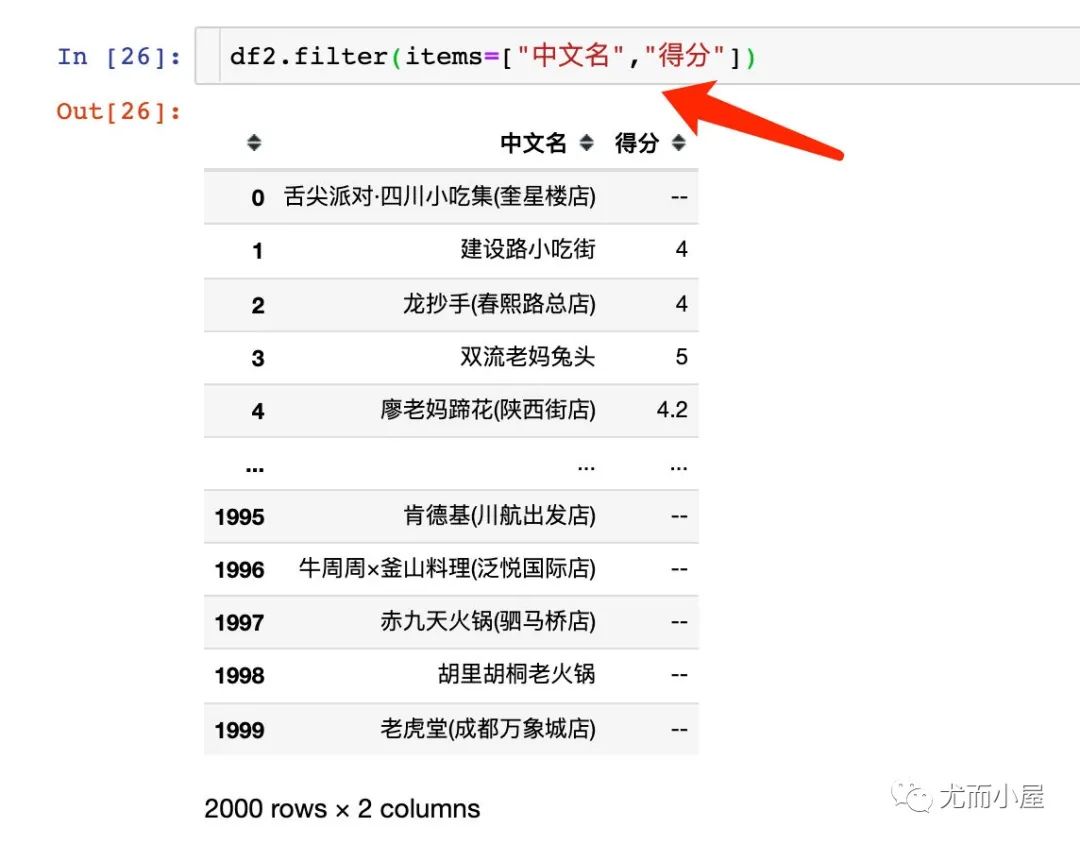
缺失值填充
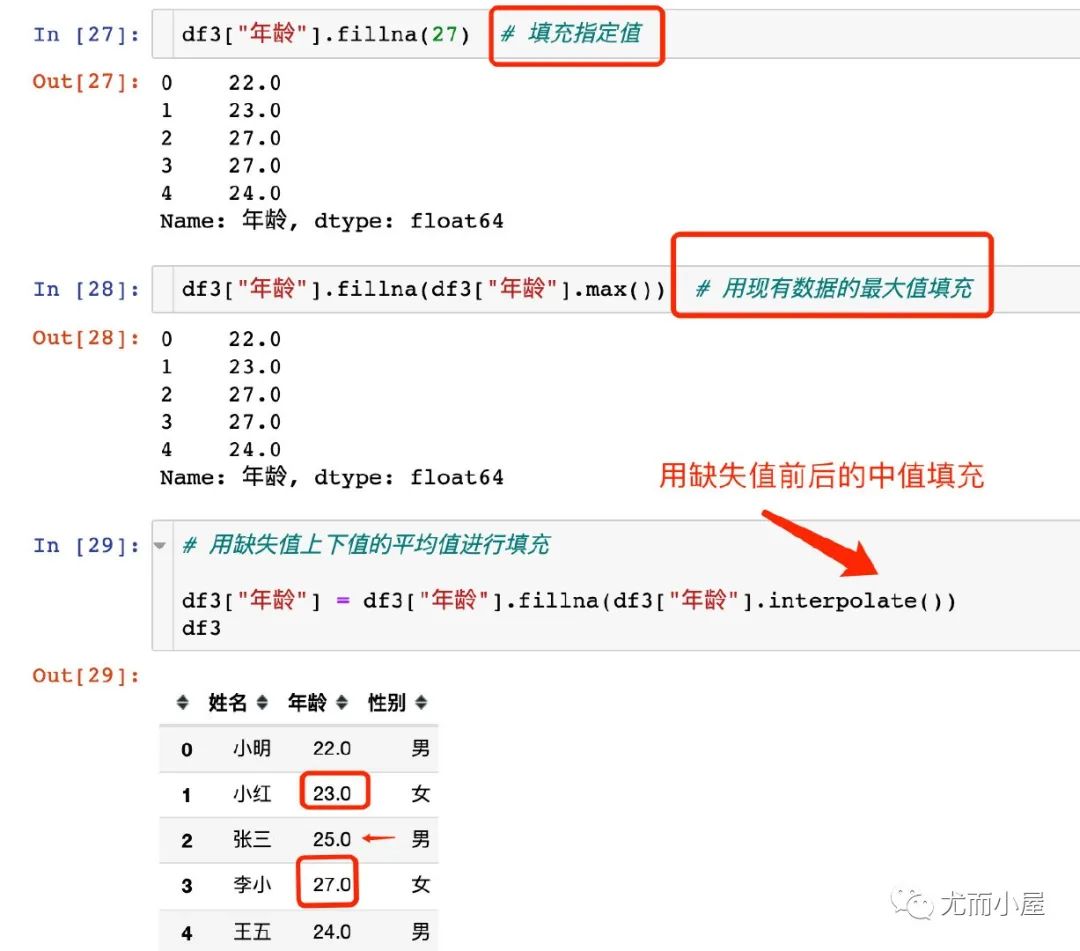
指定填充的值 用计算值 用其他值
数据去重

计算统计值
计算统计值,比如最值和均值等

计算中位数

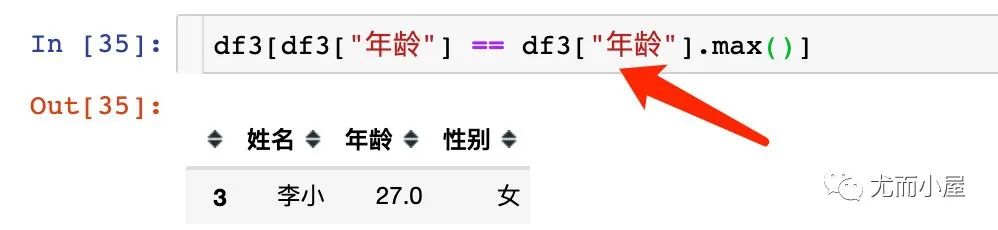
提取最值所在的行
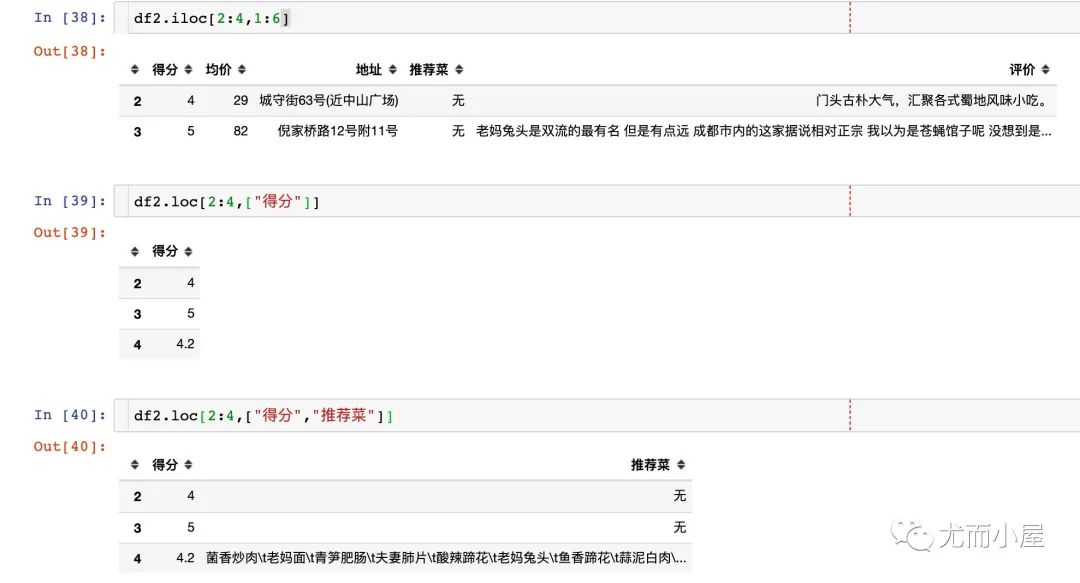
Pandas切片
df2.iloc[22] # 提取某个行的数据
df2.iloc[:,1:6] # 行和列上的切片
大小排序
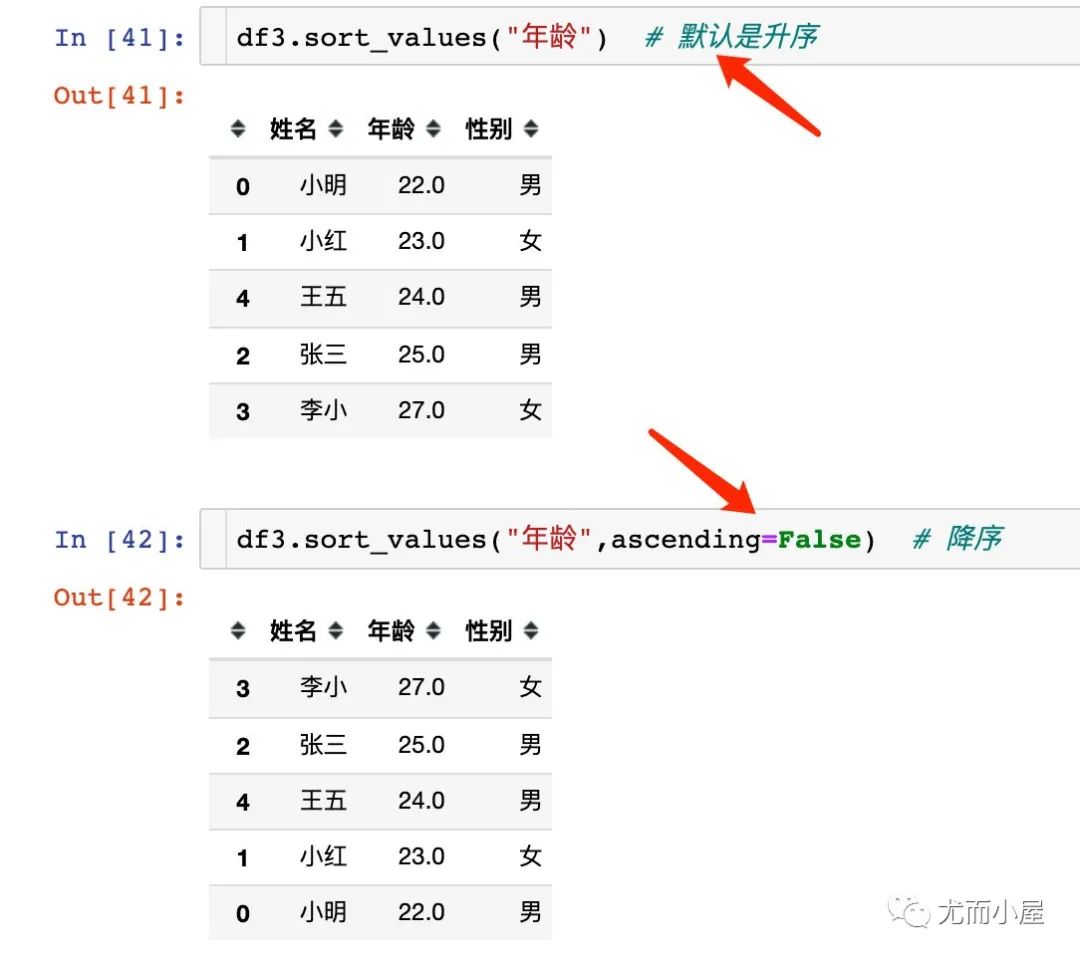
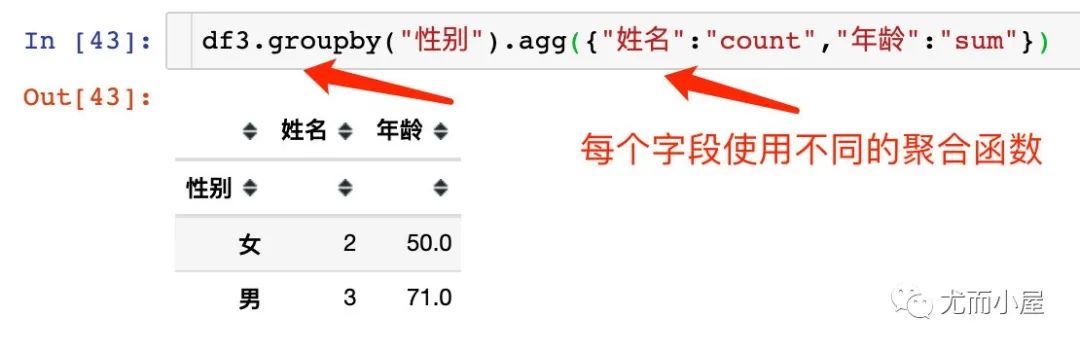
分组聚合
使用groupby分组之后,对不同的字段可以使用不同的聚合函数
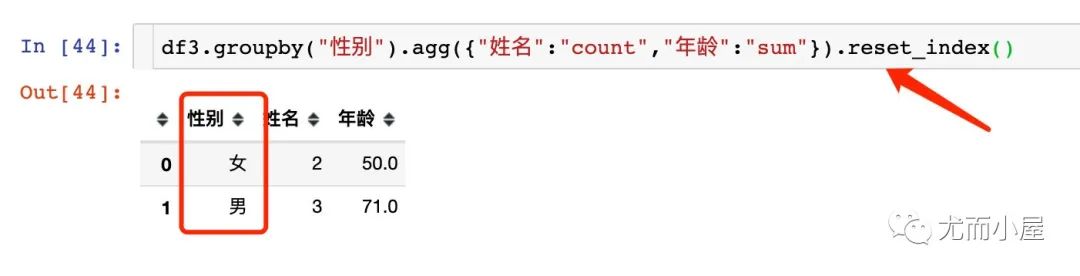
索引重排
注意和上面例子的比较。使用的是reset_index函数
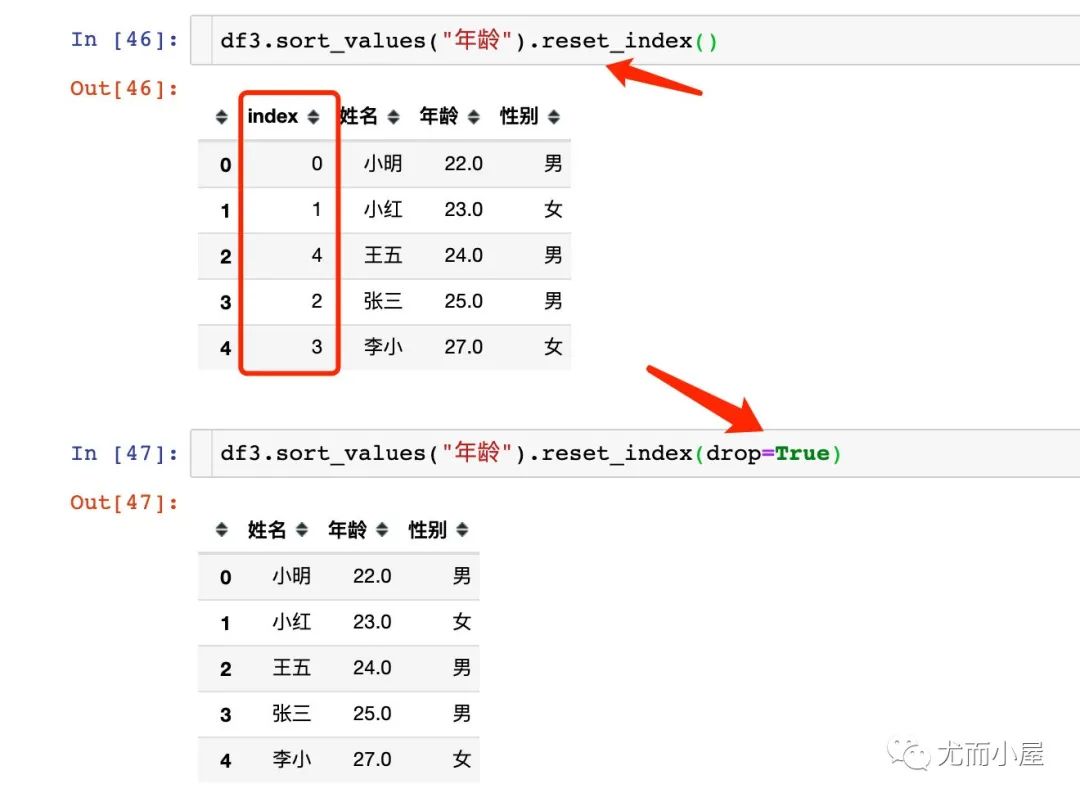
去掉原索引
使用索引重排之后我们需要去掉原来的索引;比较上下两个结果的区别。通过drop=True来实现
apply函数
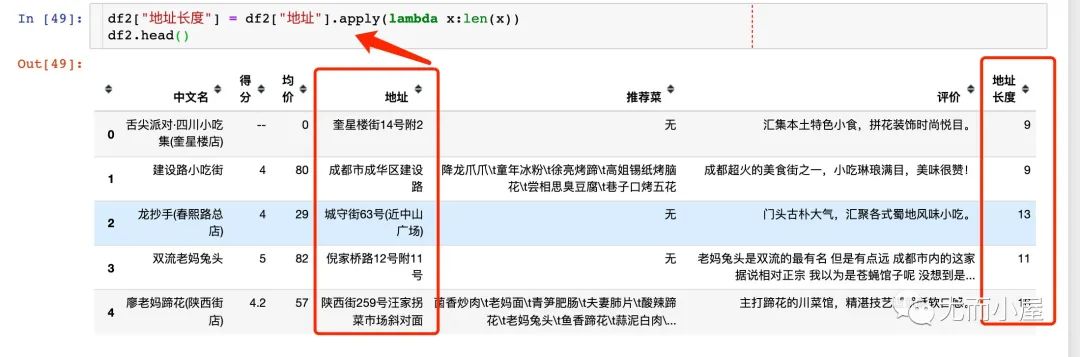
两个列相加
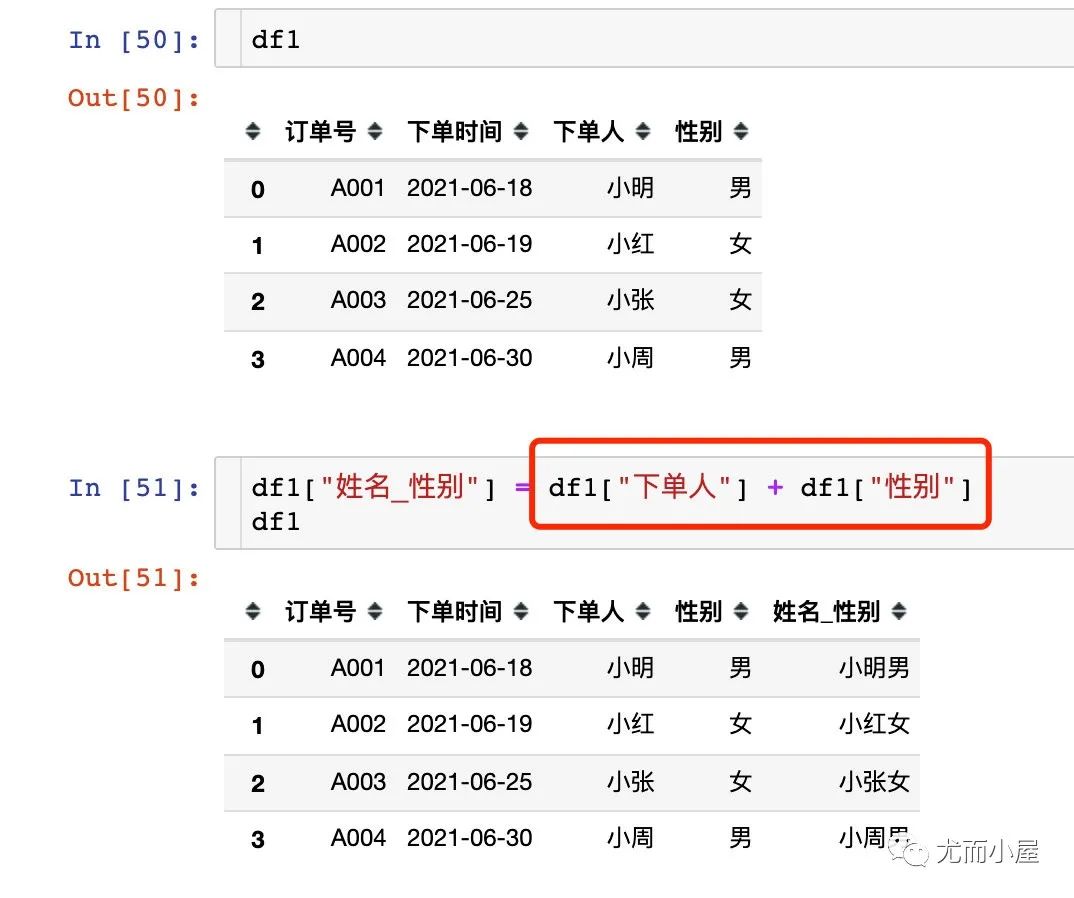

DataFrame合并
1、先看看两个原始数据
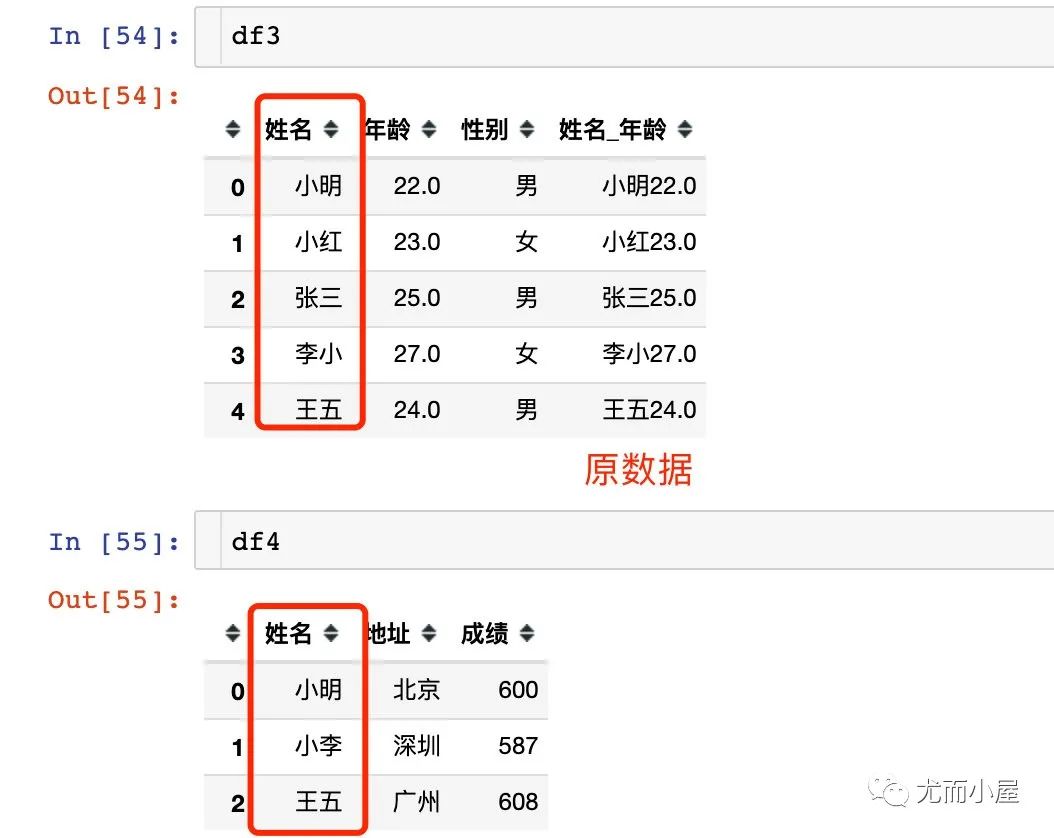
2、默认情况:求的两个DF的交集

3、保留左边全部数据

4、保留右边全部数据
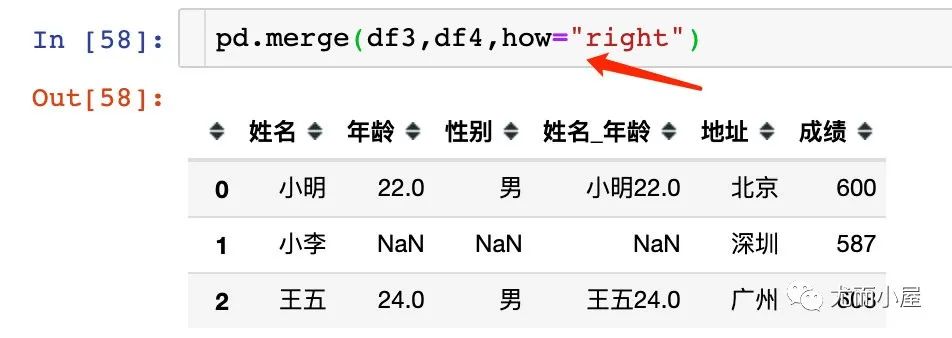
how="inner"其实就是默认情况:

导出数据
导出数据的时候通常是不需要索引的

往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论