
苹果A15芯片评测:CPU和GPU提升惊人
来源:本文由半导体行业观察(ID:icbank)编译自[anandtech],谢谢。
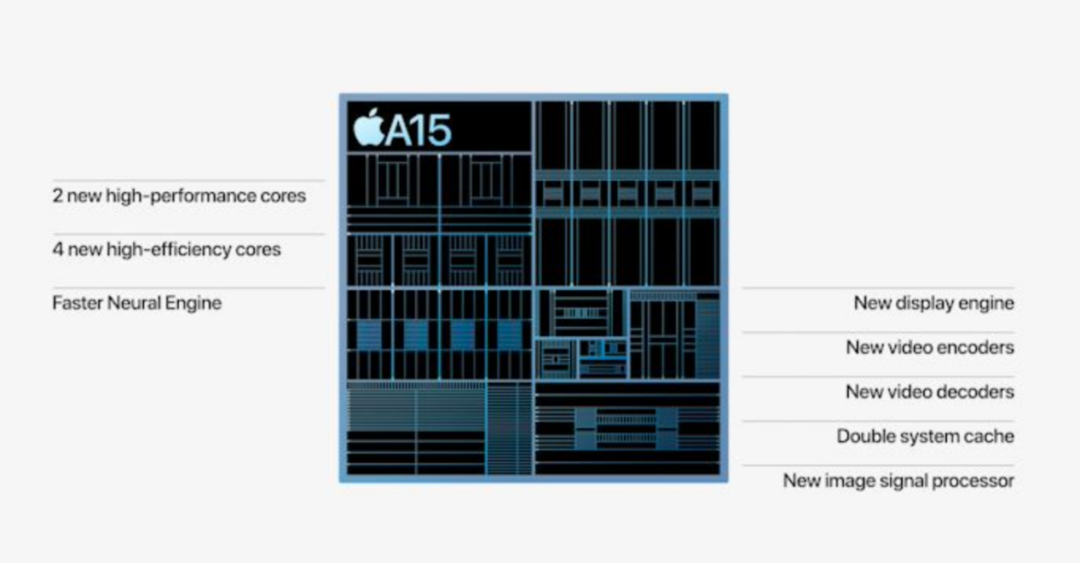
频率提升:3.24GHz 性能核和 2.0GHz的效率内核

巨型缓存:性能 CPU的 L2 增加到 12MB,SLC 增加到 32MB

CPU 微架构变化:缓慢的一年?
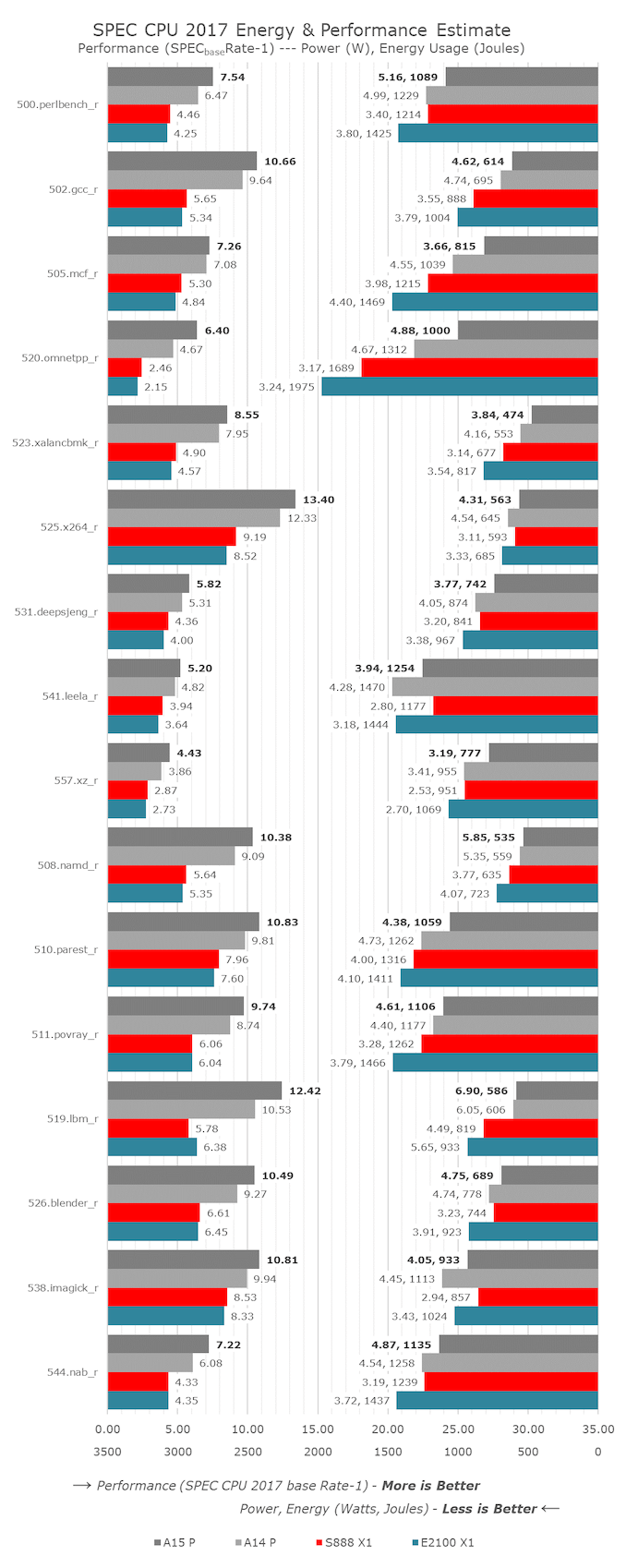
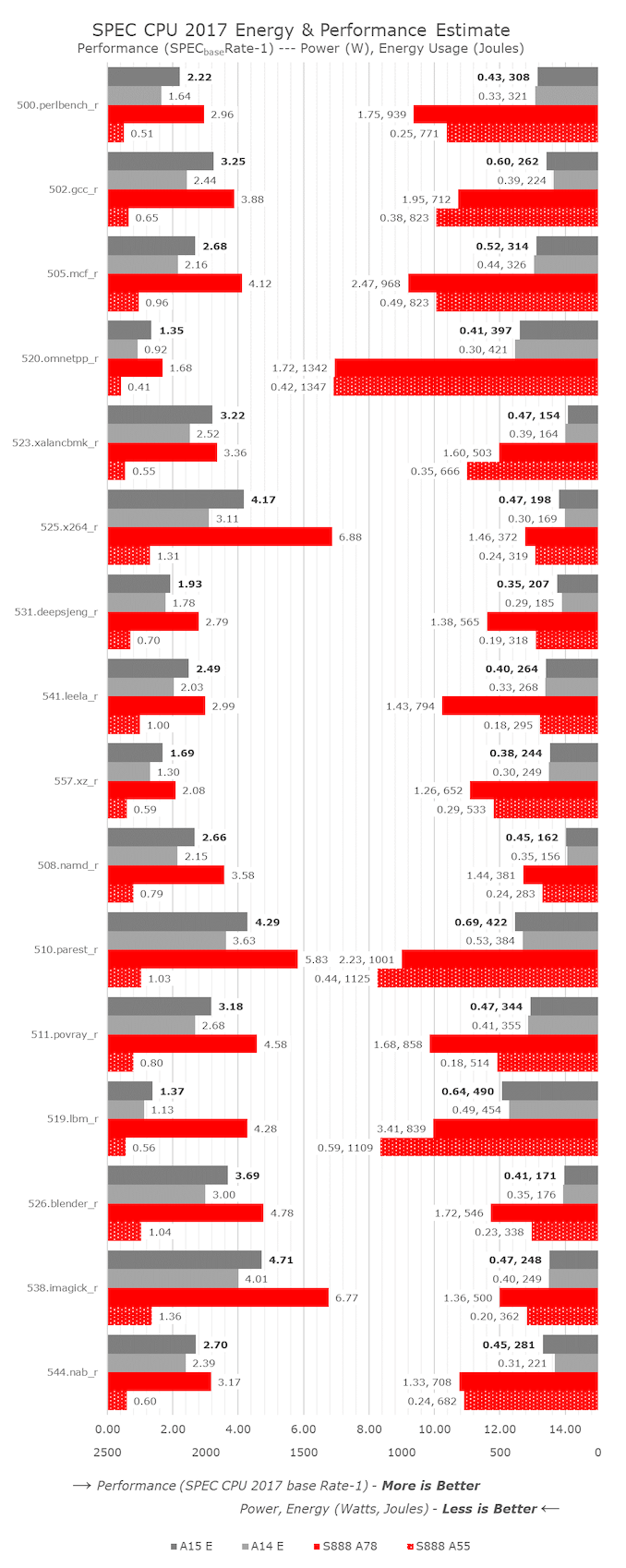
CPU ST 性能:更快、更高效

GPU 性能:出色的 GPU,一般般的散热设计
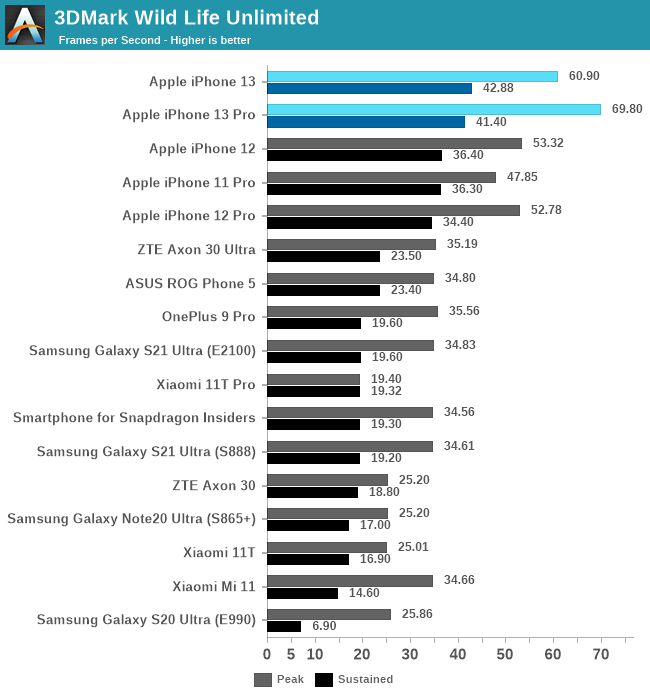
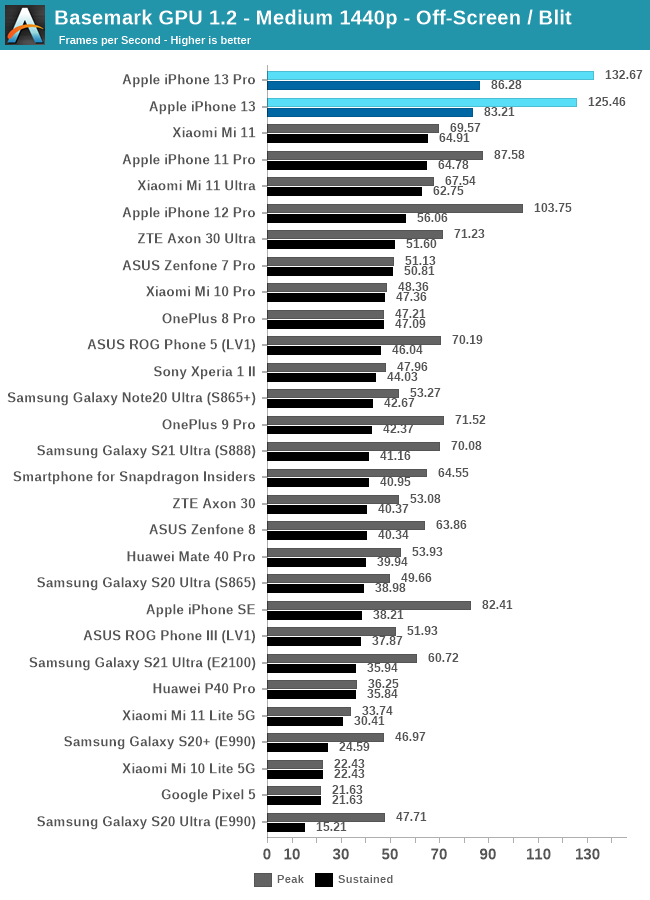
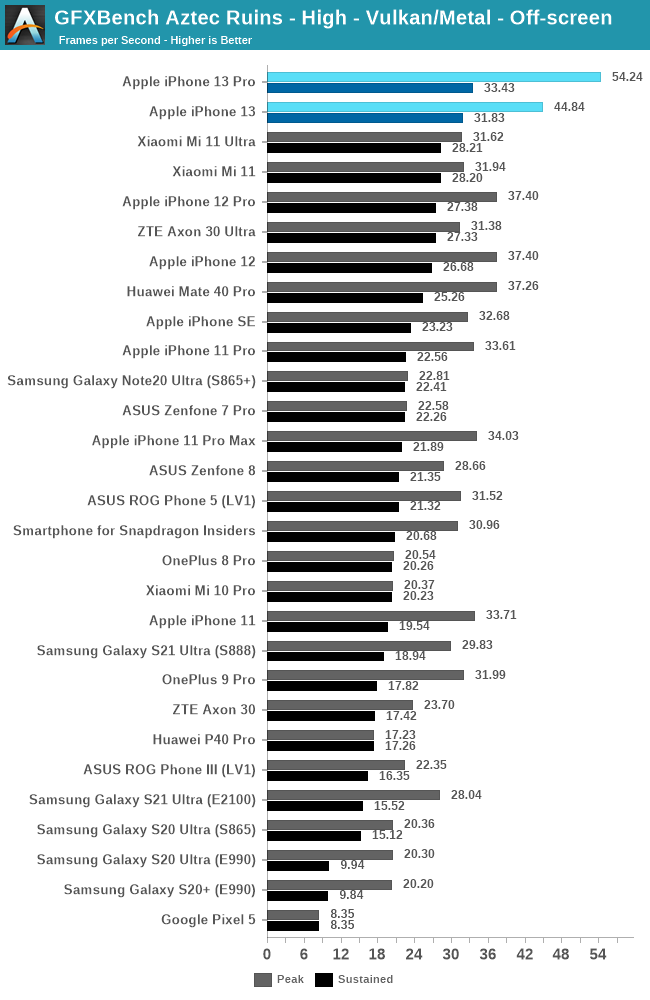
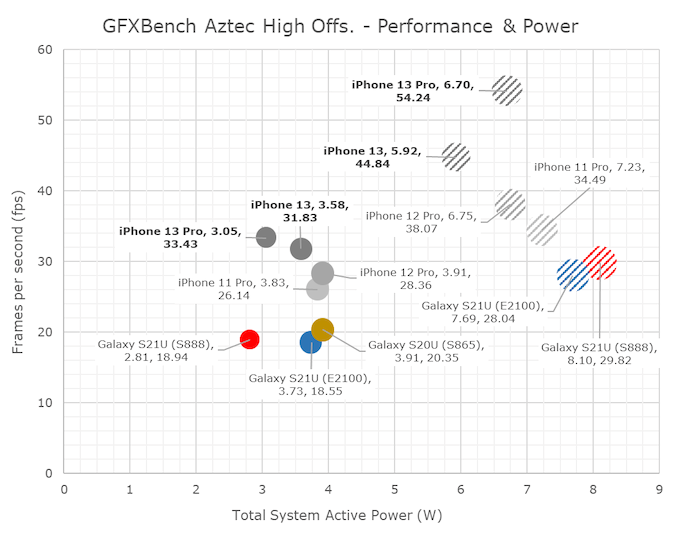
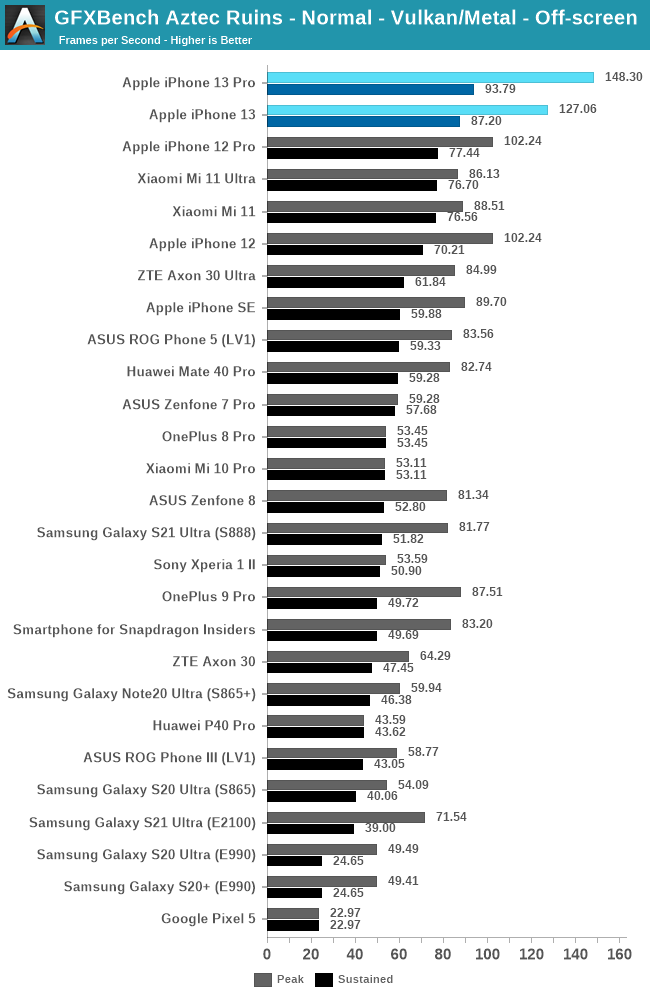
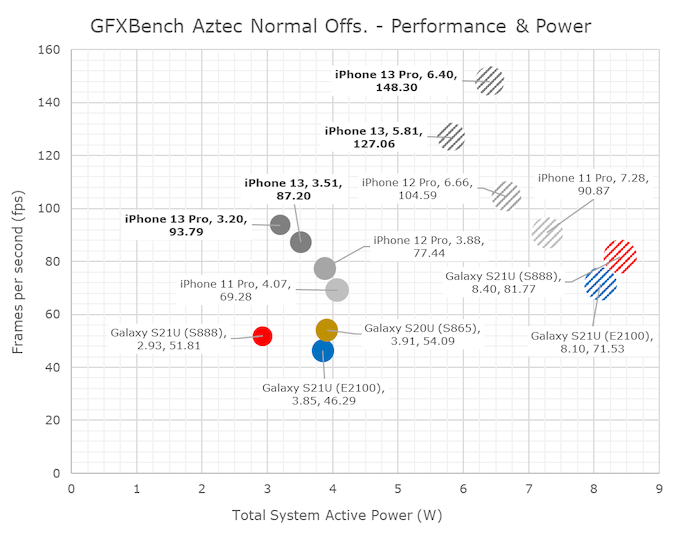
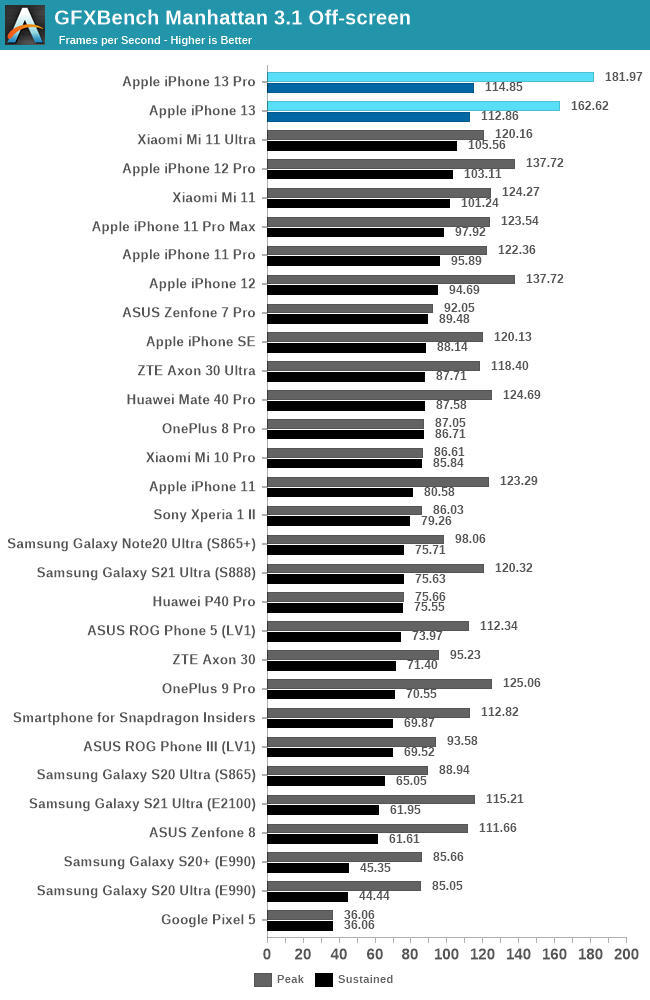
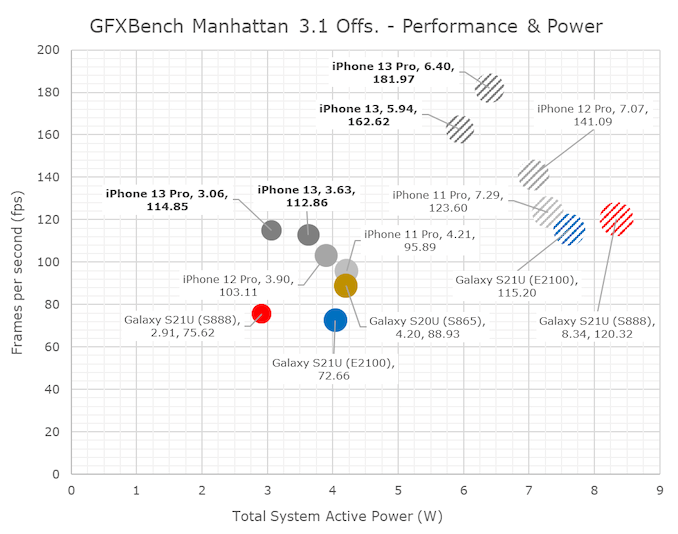
令人印象深刻的 GPU 性能,但散热非常有限

游戏中没有直接对比

结论

*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2819内容,欢迎关注。
评论