
降本提效!注册中心在蚂蚁集团的蜕变之路

文|林育智(花名:源三 )
蚂蚁集团高级专家专注微服务/服务发现相关领域校对|李旭东
本文 8624 字 阅读 18 分钟
|引 言|
服务发现是构建分布式系统的最重要的依赖之一, 在蚂蚁集团承担该职责的是注册中心和 Antvip,其中注册中心提供机房内的服务发现能力,Antvip 提供跨机房的服务发现能力。
本文讨论的重点是注册中心和多集群部署形态(IDC 维度),集群和集群之间不涉及到数据同步。
PART. 1
背 景
回顾注册中心在蚂蚁集团的演进,大概起始于 2007/2008 年,至今演进超过 13 年。时至今日,无论是业务形态还是自身的能力都发生了巨大的变化。
简单回顾一下注册中心的历代发展:
V1:引进淘宝的 configserver
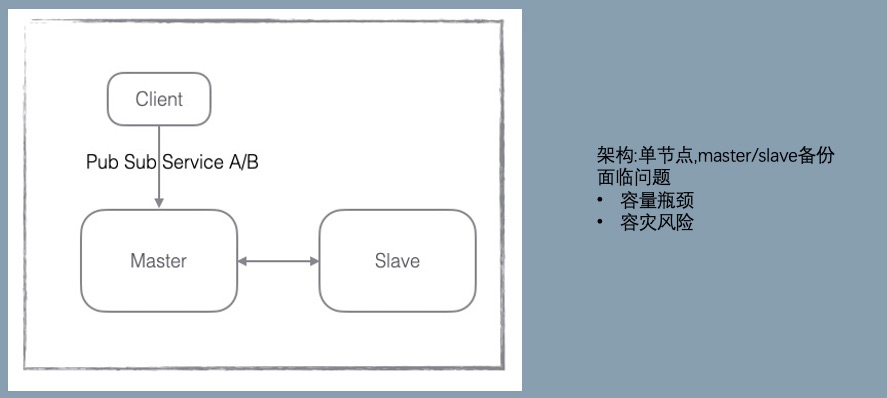
V2:横向扩展
从这个版本开始,蚂蚁和阿里开始独立的演进,最主要的差异点是在数据存储的方向选择上。蚂蚁选择了横向扩展,数据分片存储。阿里选择了纵向扩展,加大 data 节点的内存规格。
这个选择影响到若干年后的 SOFARegistry 和 Nacos 的存储架构。
V3 / V4:LDC 支持和容灾
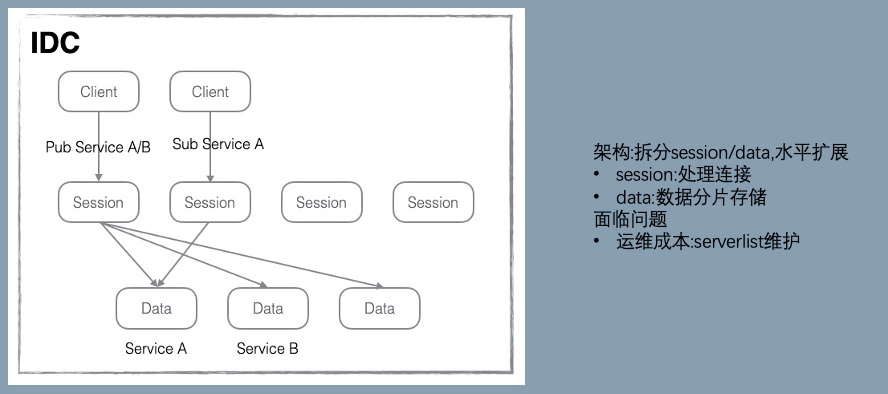
V3 支持 LDC 单元化。
V4 增加了决策机制和运行时列表,解决了单机宕机时需要人工介入处理的问题,一定程度上提升高可用和减少运维成本。
V5:SOFARegistry
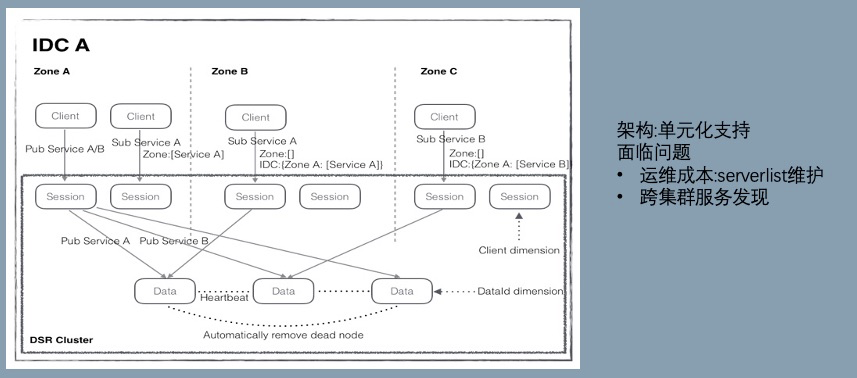
前四个版本是 confreg,17 年启动 V5 项目 SOFARegistry,目标是:
1.代码可维护性:confreg 代码历史包袱较重
- 少量模块使用 guice 做依赖管理,但大部分模块是静态类交互,不容易分离核心模块和扩展模块,不利于产品开源。
- 客户端与服务端的交互模型嵌套复杂,理解成本极高且对多语言不友好。
2.运维痛点:引入 Raft 解决 serverlist 的维护问题,整个集群的运维包括 Raft,通过 operator 来简化。
3.鲁棒性:在一致性 hash 环增加多节点备份机制(默认 3 副本),2 副本宕机业务无感。
4.跨集群服务发现:站内跨集群服务发现额外需要 antvip 支撑,希望可以统一 2 套设施的能力,同时商业化场景也有跨机房数据同步的需求。
这些目标部分实现了,部分实现的还不够好,例如运维痛点还残留一部分,跨集群服务发现在面对主站的大规模数据下稳定性挑战很大。
V6:SOFARegistry 6.0
2020 年 11 月,SOFARegistry 总结和吸收内部/商业化打磨的经验,同时为了应对未来的挑战,启动了 6.0 版本大规模重构计划。
历时 10 个月,完成新版本的开发和升级工作,同时铺开了应用级服务发现。
PART. 2
挑 战
当下面临的问题
集群规模的挑战
下图是该集群历年双十一时的数据对比和切换应用级的优化效果。相比 2019 年双十一,2021 年双十一接口级的 pub 增长 200%,sub 增长 80%。
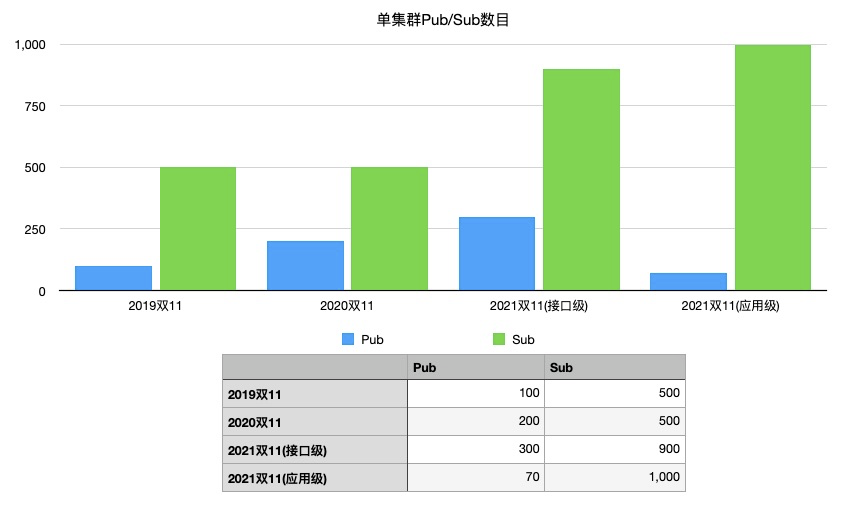
- 故障爆炸半径增长:集群接入的实例越多,故障影响的业务和实例数也就越多,保障业务的稳定是最基础也是优先级最高的要求。
- 考验横向扩展能力:集群达到一定的规模后,是否还具备继续横向扩展的能力,需要集群具备良好的横向扩展能力,从 10 扩到 100 和从 100 扩到 500 是不一样的难度。
- HA 能力:集群实例数多了后,面临的节点总体的硬件故障率也相应增高,各种机器故障集群是否能快速恢复?有运维经验的同学都知道,运维一个小集群和运维一个大集群面临的困难简直是指数级增长。
- 推送性能:大多数服务发现的产品都选择了数据的最终一致性,但是这个最终在不同集群的规模下到底是多久?相关的产品其实都没有给出明确的数据。
但是实际上,我们认为这个指标是服务发现产品的核心指标。这个时长对调用有影响:新加的地址没有流量;删除的地址没有及时摘除等。蚂蚁集团的 PaaS 对注册中心的推送时延是有 SLO 约束的:如果变更推送列表延时超过约定值,业务端的地址列表就是错误的。我们历史上也曾发生过因推送不及时导致的故障。
业务实例规模增加的同时也带来推送的性能压力:发布端 pub 下面的实例数增加;订阅端业务实例数增加;一个简单的估算,pub/sub 增长 2 倍,推送的数据量是 2*2,增长 4 倍,是一个乘积的关系。同时推送的性能也决定了同一时间可以支持的最大运维业务实例数,例如应急场景下,业务大规模重启。如果这个是瓶颈,就会影响故障的恢复时间。
集群规模可以认为是最有挑战性的,核心的架构决定了它的上限,确定后改造成本非常高。而且往往等到发现瓶颈的时候已经是兵临城下了,我们要选择能拉高产品技术天花板的架构。
运维的挑战
SOFARegistry 立项时的一个主要目标是具备比 confreg 更好的运维能力:引入 meta 角色,通过 Raft 选举和存储元信息,提供集群的控制面能力。但是事实证明,我们还是低估了可运维的重要性,正如鲁迅先生说:【程序员的工作只有两件事情,一件是运维,另一件还是运维】。
三年前的目标放到今天已经严重滞后了。
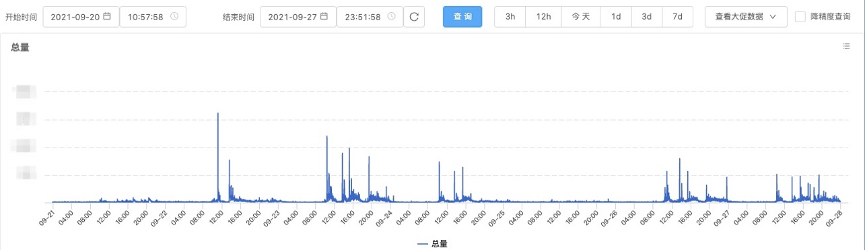
- 业务打扰:业务的运维是全天候 7*24 的,容量自适应/自愈/MOSN 每月一版本把全站应用犁一遍等等。下图是每分钟运维的机器批数,可以看到,就算是周末和深夜,运维任务也是不断的。
云原生时代 naming 的挑战
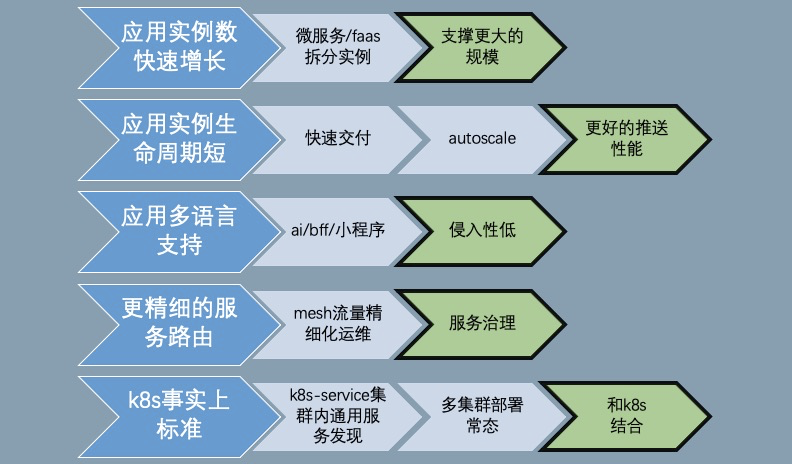
云原生的技术时代下,可以观察到一些趋势:
- 应用实例的生命周期更短:FaaS 按需使用,autoscale 容量自适应等手段导致实例的涨潮退潮更频繁,注册中心的性能主要体现在实例变更的响应速度上
- 多语言支持:在过去,蚂蚁集团主要的开发体系是 Java,非 Java 语言对接基础设施都是二等公民,随着 AI 和创新性业务的需求,非 Java 体系的场景越来越多。如果按照每种语言一个 SDK,维护成本会是个噩梦,当然 sidecar(MOSN)是个解法,但是自身是否能支持低侵入性的接入方式,甚至 sdk-free 的能力?
- 服务路由:在过去绝大部分的场景都可以认为 endpoint 是平等的,注册中心只提供通信的地址列表是可以满足需求的。在 Mesh 的精确路由场景里面,pilot 除了提供 eds(地址列表)也同时提供 rds(routing),注册中心需丰富自身的能力。
- K8s:K8s 当前已经成为事实上的分布式操作系统,K8s-service 如何和注册中心打通?更进一步,是否能解决 K8s-service 跨 multi-cluster 的问题?
「总结」
综上,除了脚踏实地,解决当下的问题,还需要仰望星空。具备解决云原生趋势下的 naming 挑战的可能性,也是 V6 重构的主要目标。
PART. 3
SOFARegistry 6.0:面向效能
SOFARegistry 6.0 不只是一个注册中心引擎,需要和周边的设施配合,提升开发、运维、应急的效能,解决以下的问题。(红色模块是比较有挑战性的领域)
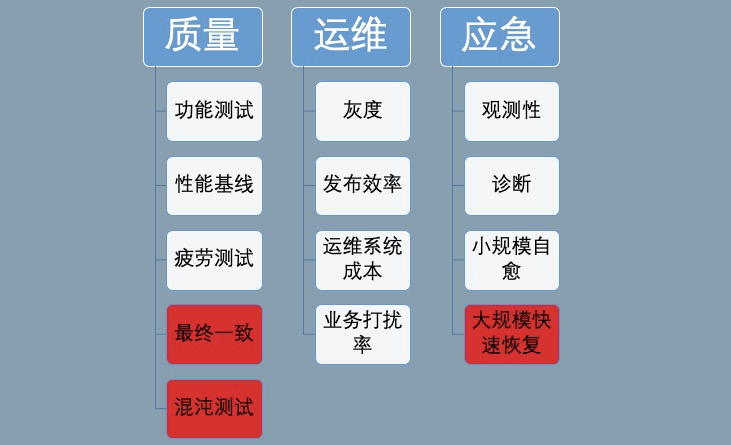
SOFARegistry 6.0 相关的工作包括:

架构优化
架构的改造思路:在保留 V5 的存储分片架构的同时,重点的目标是优化元信息 meta 一致性和确保推送正确的数据。

元信息 meta 一致性
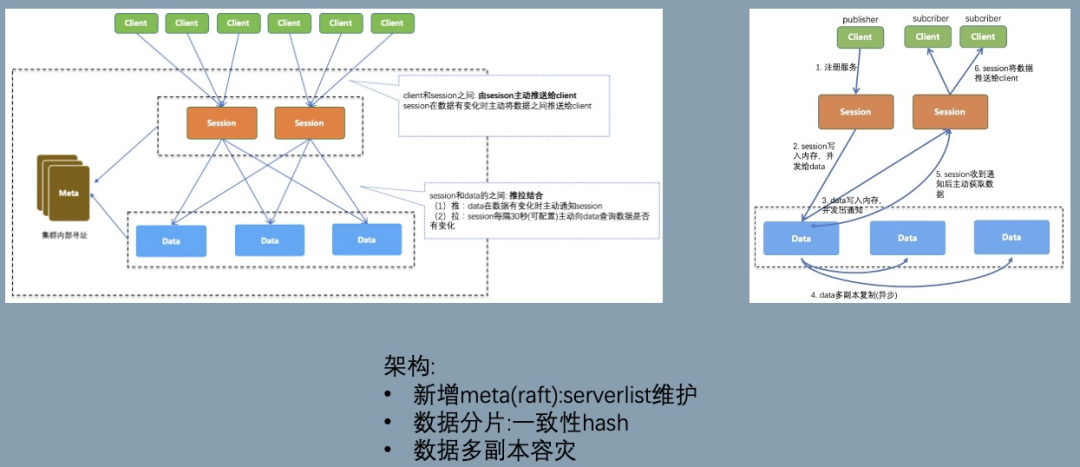
V5 在 meta 角色中引入 Raft 的强一致性进行选举 leader 和存放元信息,其中元信息包括节点列表和配置信息。数据的分片通过获取 meta 的节点列表做一致性 hash,这里面存在两个问题:
- 脆弱的强一致性meta 信息的使用建立在满足强一致性的情况下,如果出现网络问题,例如有 session 网络分区连不上 meta,错误的路由表会导致数据分裂。需要机制确保:即使 meta 信息不一致也能在短时间内维持数据的正确性,留有应急的缓冲时间。
推送正确的数据
当 data 节点大规模运维时,节点列表剧烈变化导致数据不断迁移,推送出去的数据存在完整性/正确性的风险。V5 通过引 3 副本来避免这种情况,只要有一个副本可用,数据就是正确的,但是该限制对运维流程负担很大,我们要确保每次操作少于两个副本或者挑选出满足约束的运维序列。
对于 V5 及之前的版本,运维操作是比较粗糙的,一刀切做停机发布,通过锁 PaaS 禁止业务变更,等 data 节点稳定后,再打开推送能力来确保避免推送错误数据的风险。
此外,预期的运维工作可以这样做,但是对于突发的多 data 节点宕机,这个风险仍然是存在的。
我们需要有机制确保:data 节点列表变化导致数据迁移时,容忍接受额外的轻微推送时延,确保推送数据正确。
「成果」
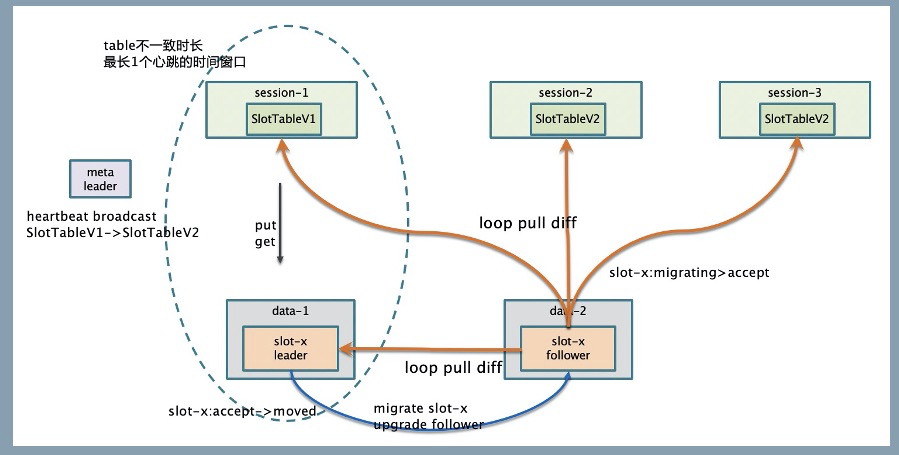
- 数据使用固定 slot 分片,meta 提供调度能力,slot 的调度信息通过 slotTable 保存,session/data 节点可容忍该信息的弱一致性,提升鲁棒性。
- 多副本调度减少 data 节点变动时数据迁移的开销,当前线上的数据量 follower 升级 leader 大概 200ms (follower 持有绝大部分的数据),直接分配 leader 数据同步耗时 2s-5s。
- 优化数据通信/复制链路,提升性能和扩展能力。
- 大规模运维不需要深夜锁 PaaS,减少对业务打扰和保住运维人员头发,提升幸福感。
数据链路和 slot 调度:
- meta 的 leader 节点,通过心跳感知存活的 data 节点列表,尽可能均匀的把 slot 的多副本分配给 data 节点,相关的映射关系保存在 slotTable,有变更后主动通知给 session/data。
- session/data 同时通过心跳获取最新的 slotTable,避免 meta 通知失效的风险。
- slot 在 data 节点上有状态机 Migrating -> Accept -> Moved。迁移时确保 slot 的数据是最新的才进入 Accept 状态,才可以用于推送,确保推送数据的完整性。
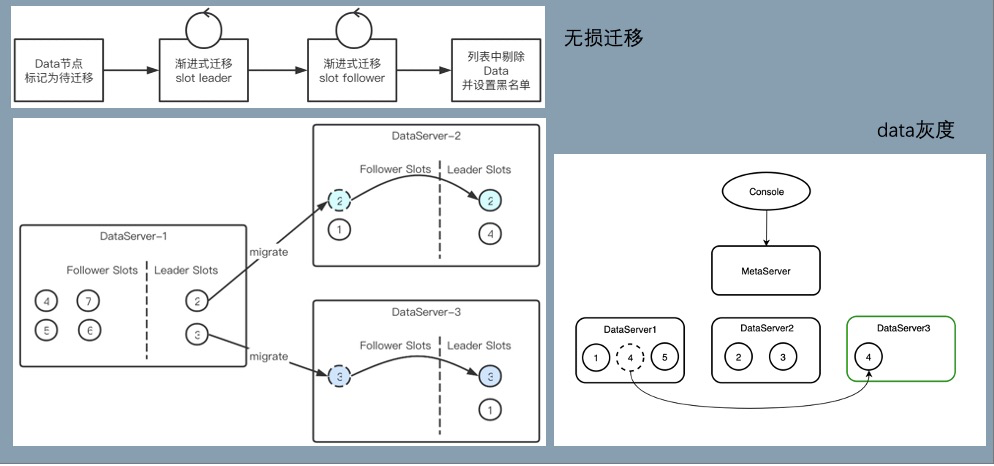
data 节点变动的数据迁移:
对一个接入 10w+ client 的集群进行推送能力压测,分钟级 12M 的推送量,推送延迟 p999 可以保持在 8s 以下。session cpu20%,data cpu10%,物理资源水位较低,还有较大的推送 buffer。
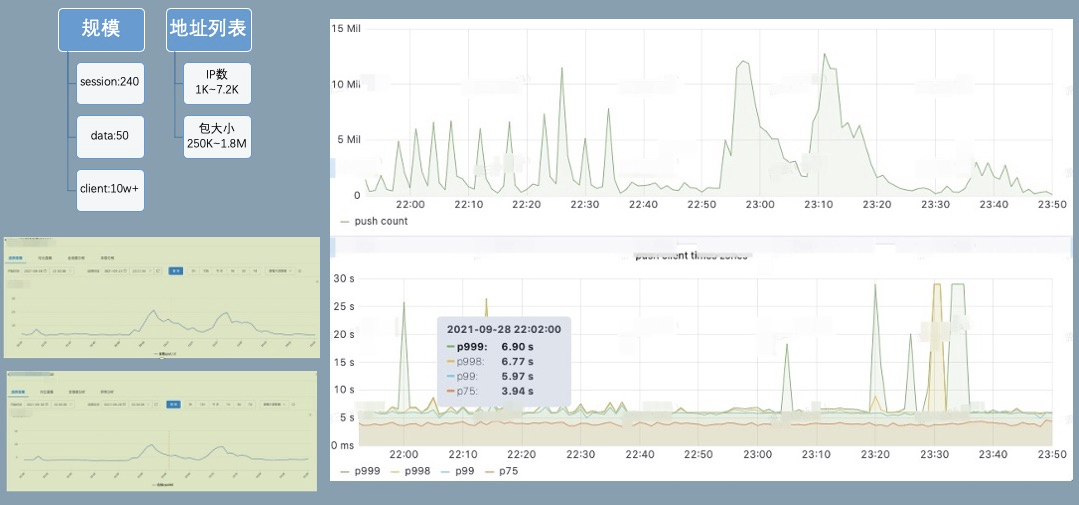
同时我们也在线上验证横向扩展能力,集群尝试最大扩容到 session*370,data*60,meta*3 ;meta 因为要处理所有的节点心跳,CPU 达到 50%,需要 8C 垂直扩容或者进一步优化心跳开销。按照一个 data 节点的安全水位支撑 200w pub,一个 pub 大概 1.5K 开销,考虑容忍 data 节点宕机 1/3 仍然有服务能力,需要保留 pub 上涨的 buffer,该集群可支撑 1.2 亿的 pub,如果配置双副本则可支撑 6kw 的 pub。
应用级服务发现
注册中心对 pub 的格式保留很强的灵活性,部分 RPC 框架实现 RPC 服务发现时,采用一个接口一个 pub 的映射方式,SOFA/HSF/Dubbo2 都是采用这种模式,这种模型比较自然,但是会导致 pub/sub 和推送量膨胀非常厉害。
Dubbo3 提出了应用级服务发现和相关原理【1】。在实现上,SOFARegistry 6.0 参考了 Dubbo3,采用在 session 端集成服务的元数据中心模块的方案,同时在兼容性上做了一些适配。
「应用级服务 pub 数据拆分」
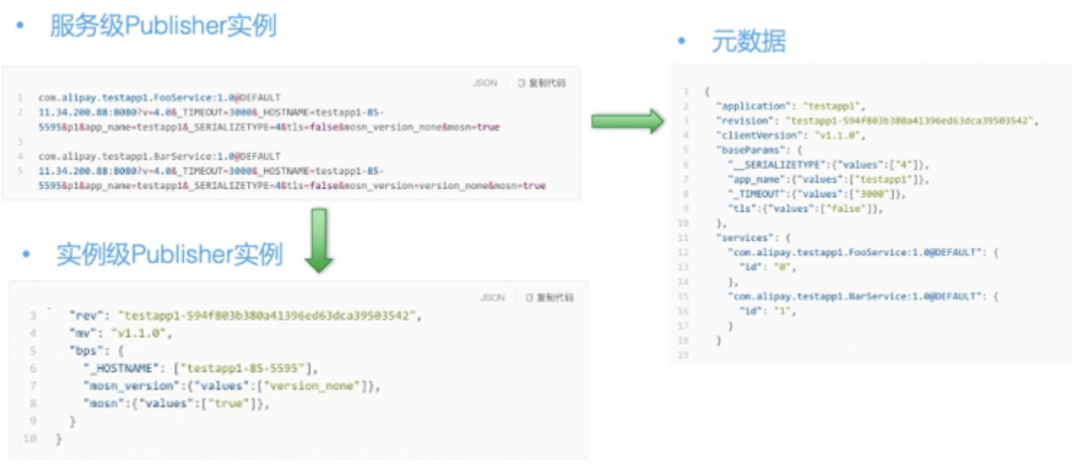
「兼容性」
应用级服务发现的一个难点是如何低成本的兼容接口级/应用级,虽然最后大部分的应用都能升级到应用级,升级过程中会面临以下问题:
我们采用以应用级服务为主,同时兼容接口级的解决方案:
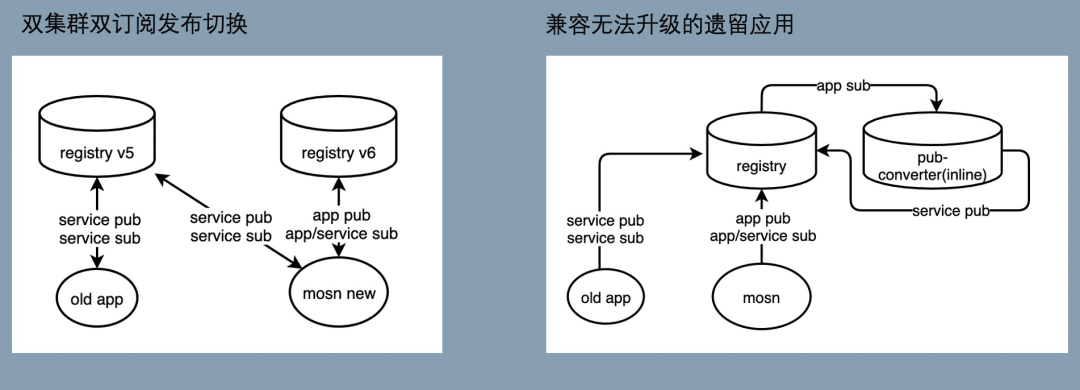
在升级时同时存在新旧版本的两个 SOFARegistry,不同版本的 SOFARegistry 对应到不同的域名。升级后的应用端(图中的 MOSN)采用双订阅双发布的方式逐步灰度切换,确保切换过程中,没有升级接入 MOSN 或者没有打开开关的应用不受影响。
在完成绝大多数应用的应用级迁移后,升级后的应用都已经到了 SOFARegistry 6.0 版本的注册中心上,但仍然存在少量应用因为没有接入 MOSN,这些余留的 old app 也通过域名切换到 SOFARegistry 6.0,继续以接口级订阅发布和注册中心交互。为了确保已升级的和没升级的应用能够互相订阅,做了一些支持:
- 提供应用级 Publisher 转接到口级 Publisher 的能力:接口级订阅端是无法直接订阅应用级发布数据的,针对接口级订阅按需从 AppPublisher 转换出 InterfacePublisher,没有接入 MOSN 的应用可以顺利的订阅到这部分数据,因为只有少量应用没有接入 MOSN,需要转化的应用级 Publisher 很少。
- 应用级订阅端在订阅的时候额外发起一个接口级的订阅,用于订阅没有接入升级的应用发布数据。由于这部分应用非常少,实际绝大多数的服务级订阅都不会有推送任务,因此对推送不会造成压力。
「效果」
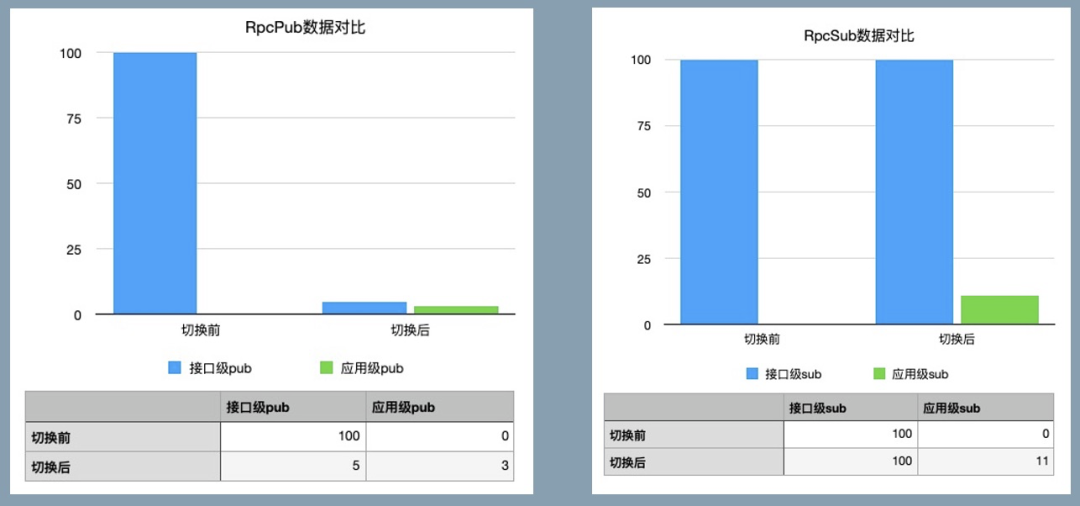
上图是一个集群切换应用级后的效果,其中切换后剩余部分接口级 pub 是为了兼容转换出来的数据,接口级 sub 没减少也是为了兼容接口级发布。如果不考虑兼容性,pub 数据减少高达 97%。极大的减轻了数据规模的对集群的压力。
SOFARegistryChaos:自动化测试
注册中心的最终一致性的模型一直是个测试难题:
针对该系列问题,我们开发了 SOFARegistryChaos,特别针对最终一致性提供完备的测试能力,除此还提供功能/性能/大规模压测/混沌测试等能力。同时,通过插件化的机制,也支持接入测试其他服务发现产品的能力,基于 K8s 的部署能力,能让我们快速的部署测试组件。
具备以上的能力后,不单可以测试自身的产品能力,例如还可以快速的测试 zookeeper 在服务发现方面的相关性能来做产品比较。
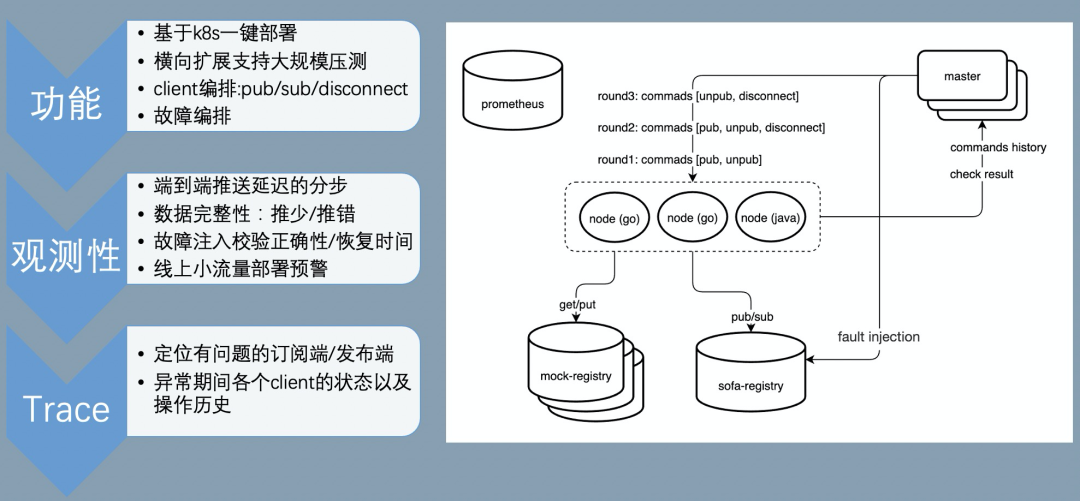
测试观测性
提供的关键数据的观测能力,通过 metrics 透出,对接 Prometheus 即可提供可视化能力:
该能力的测试是一个比较有意思的创新点,通过固化一部分的 client 和对应的 pub,校验每次其他各种变更导致的推送数据,这部分数据都必须是要完整和正确的。- 推送次数
- 推送数据体积
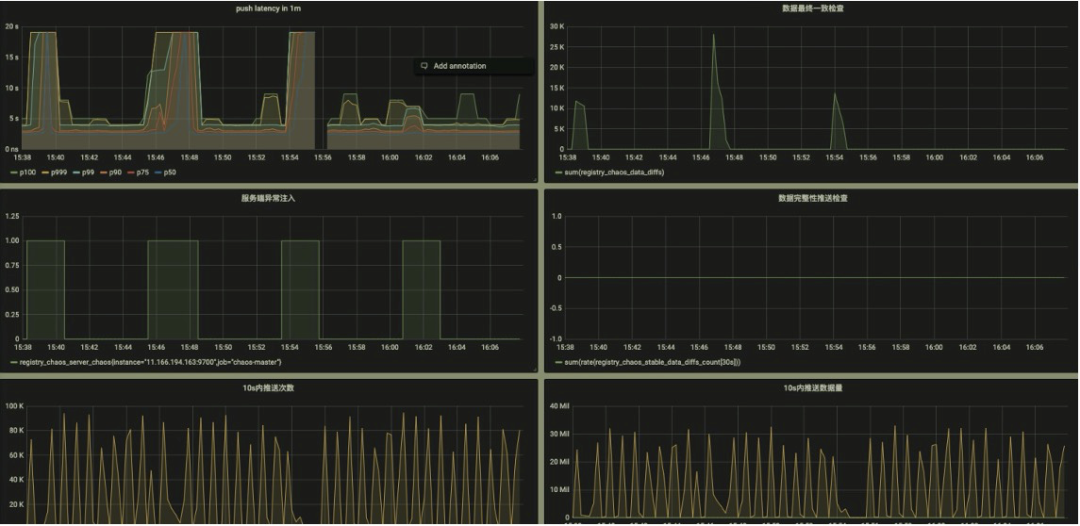
失败 case 的排查
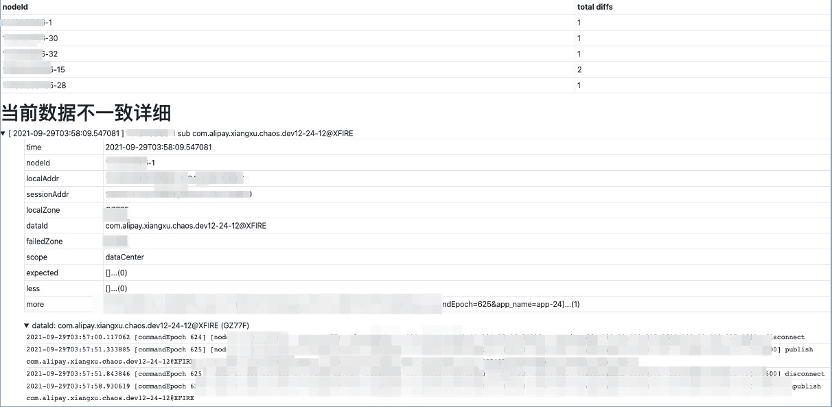
测试场景中,client 操作时序和故障注入都是随机编排的,我们在 SOFARegistryChaos master 端记录和收集了所有的操作命令时序。当 case 失败时,可通过失败的数据明细和各个 client 的 API 调用情况来快速定位问题。
例如下图的失败 case 显示在某个 Node 上的订阅者对某个 dataId 的订阅数据没通过校验,预期是应该要推空, 但是推送了一条数据下来。同时显示了该 dataId 所有相关的 publisher 在测试期间的相关操作轨迹。
黑盒探测
大家是否经历过类似的 case:
注册中心因为本身的特性,对业务的影响往往是滞后的,例如 2K 个 IP 只推送了 1K 个,这种错误不会导致业务马上感知到异常。但是实际本身已经出问题了。对于注册中心,更需要有提前发现治末病的能力。
这里我们引入黑盒探测的方式:模拟广义上的用户行为,探测链路是否正常。
SOFARegistryChaos 实际上就可以作为一个注册中心的用户,并且是加强版的,提供端到端的告警能力。
我们把 SOFARegistryChaos 部署到线上,开启小流量作为一个监控项。当注册中心异常但还没对业务造成可感知的影响时,我们有机会及时介入,减少风险事件升级成大故障的风险。
磨刀不误砍柴工
通过 SOFARegistryChaos,核心能力的验证效率极大提升,质量得到保障的同时,开发同学写代码也轻松了许多。从 7 月份到 10 月中的 3 个半月时间里,我们迭代并发布了 5 个版本,接近 3 周 1 个版本。这个开发效率在以前是不敢想象的,同时也获得完善的端到端告警能力。
运维自动化
nightly build
虽然我们集群数目非常多,但是因为是区分了多环境,部分环境对于稳定性的要求相对生产流量要求稍微低一些,例如灰度以下的环境。这些环境的集群是否可以在新版本保证质量的情况下,快速低成本的 apply 。结合 SOFARegistryChaos,我们和质量/SRE 的同学正在建设 nightly build 设施。
SOFARegistryChaos 作为变更门禁,新版本自动化的部署,接受 SOFARegistryChaos 的测试通过后,自动化部署到灰度以下的集群,仅在生产发布时候人工介入。
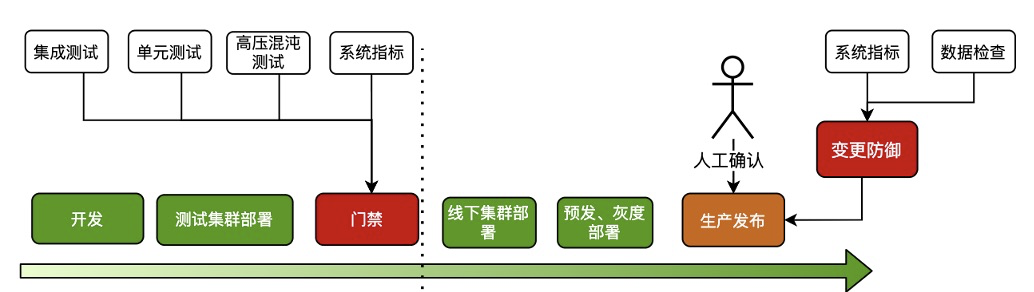
通过 nightly build,极大的减轻非生产环境的发布成本,同时新版本能尽早接受业务流量的检验。
故障演练
虽然我们做了大量的质量相关的工作,但是在线上面对各种故障时究竟表现如何?是骡子还是马,还是要拉出来溜一溜。
我们和 SRE 的同学在线上会定期做故障容灾演练,包括但不限于网络故障;大规模机器宕机等。另外演练不能是一锤子买卖的事情,没有保鲜的容灾能力其实等于 0。在仿真/灰度集群,进行容灾常态化,演练-迭代循环。
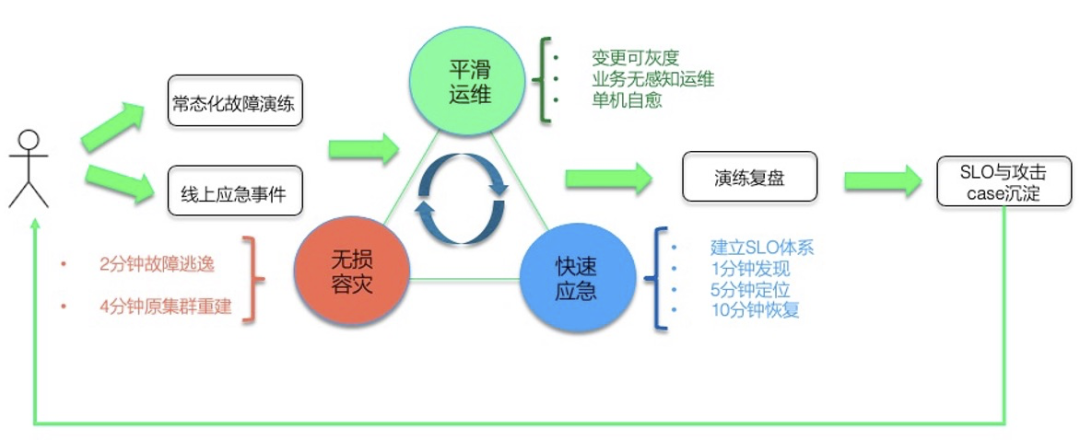
定位诊断
故障容灾演练常态化后,如何快速的定位到故障源成了摆在桌子上的一个问题,否则每次演练都鸡飞狗跳的,效率太低了。
SOFARegistry 各个节点做了大量的可观测性的改进,提供丰富的可观测能力,SRE 的诊断系统通过相关数据做实时诊断,例如这个 case 里就是一个 session 节点故障导致 SLO 破线。有了定位能力后,自愈系统也可以发挥作用,例如某个 session 节点被诊断出网络故障,自愈系统可以触发故障节点的自动化替换。
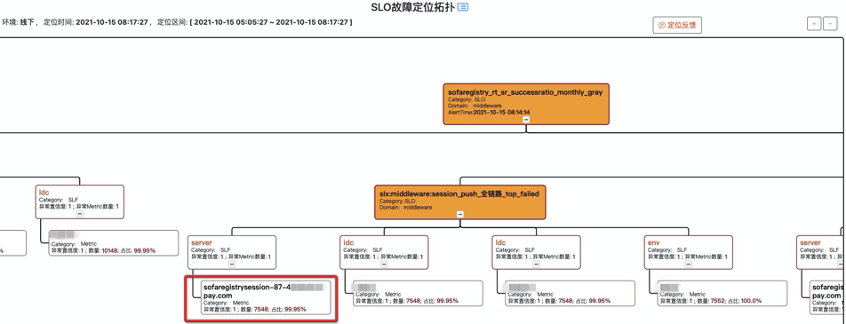
目前,我们的容灾演练应急绝大部分 case 已经不需要人肉介入,也只有这样低成本的演练才能常态化。
「收益」
通过不断的演练暴露问题和快速迭代修复,SOFARegistry 的稳定性逐步提升。
「总结」
SOFARegistry 6.0 除了自身的优化,在测试/运维/应急方面做了大量的工作,目标是提升研发/质量/运维人员的效能,让相关同学摆脱低效的人肉工作,提升幸福感。
PART. 4
开源:一个人可以走得很快,
但一群人可以走的更远
SOFARegistry 是一个开源项目,也是开源社区 SOFAStack 重要的一环,我们希望用社区的力量推动 SOFARegistry 的前进,而不是只有蚂蚁集团的工程师去开发。
在过去一年,SOFARegistry 因为重心在 6.0 重构上,社区几乎处于停滞状态,这个是我们做得不够好的地方。
我们制定了未来半年的社区计划,在 12 月份会基于内部版本开源 6.0,开源的代码包含内部版本的所有核心能力,唯一区别是内部版本多了对 confreg-client 的兼容性支持。

另外从 6.1 后,我们希望后继的方案设计/讨论也是基于社区来开展,整个研发进程更透明和开放。
PART. 5
我们仍在路上
2021 年是 SOFARegistry 审视过去,全面夯实基础,提升效能的一年。
当然,我们当前还仍然处在初级阶段,前面还有很长的路要走。例如今年双十一的规模面临一系列非常棘手的问题:
还有其他的挑战:
「参 考」
【1】Dubbo3 提出了应用级服务发现和相关原理:
https://dubbo.apache.org/zh/blog/2021/06/02/dubbo3-%E5%BA%94%E7%94%A8%E7%BA%A7%E6%9C%8D%E5%8A%A1%E5%8F%91%E7%8E%B0/
关于我们:
蚂蚁应用服务团队是服务于整个蚂蚁集团的核心技术团队,打造了世界领先的金融级分布式架构的基础设施平台,是 Service Mesh 等云原生领域的领先者,开发运维着全球最大的 Service Mesh 集群,蚂蚁集团的消息中间件每天支撑上万亿的消息流转。
欢迎对 Service Mesh/微服务/服务发现 等领域感兴趣的同学加入我们。
联系邮箱: yuzhi.lyz@antgroup.com
本周推荐阅读

稳定性大幅度提升:SOFARegistry v6 新特性介绍


