
蚂蚁集团分布式注册中心建设分享

- 前言 -
这篇文章是基于 SOFA Meetup 合肥站的分享总结,主要针对于注册中心的定位以及功能介绍,通过对蚂蚁注册中心发展史的分析,带领大家了解,蚂蚁的注册中心是如何一步一步演变为现在的规模和特性的。
- 注册中心是什么 -

服务发现可以有一个中心化的组件或者说是存储,它承载了所有服务的地址,同时提供出来一个可供查询和订阅的能力,服务的消费方可以通过和这个中心化的存储交互,获取服务提供方的地址列表。 服务注册:同样是上文中中心化的组件,但是,这个时候的服务信息可以有两种措施:
服务连接注册中心,同时上报自身的服务以及元数据(也是今天本文讲述的重点) 有一个集中的控制面(control plane)将用户定义的服务和 IP 的映射写入注册中心,例如 AWS 的 CloudMap。
- 调用流程 -
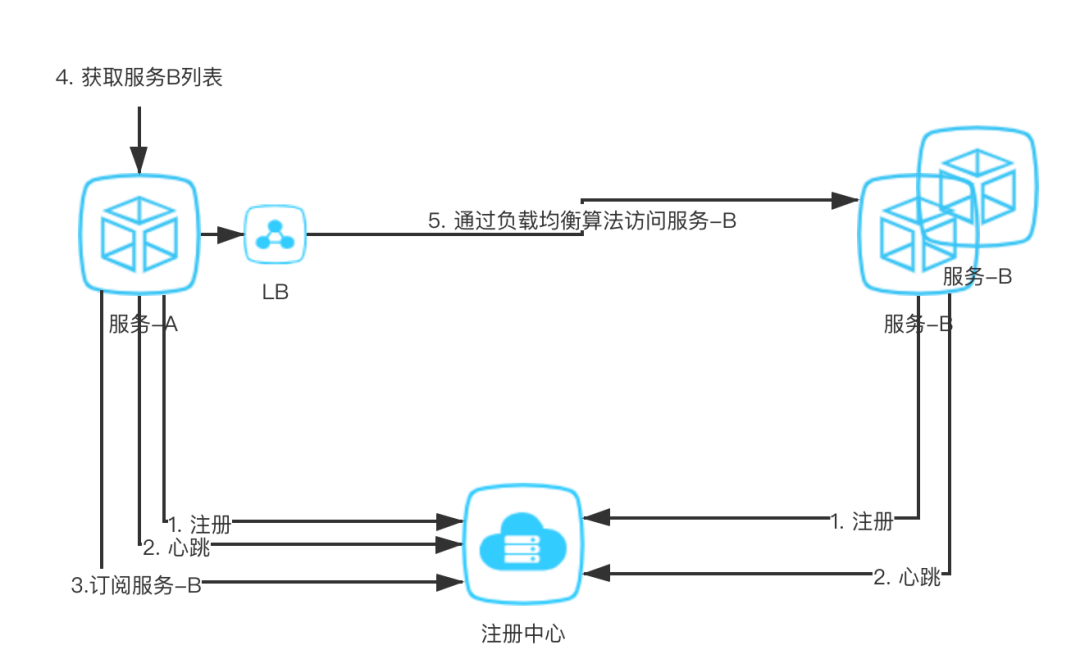
服务 A,服务 B 通过 SDK 或者 REST 将自身的服务信息上报给注册中心; 服务 A 需要调用服务 B 的时候,就对注册中心发起请求,拉取和服务 B 相关的服务 IP 列表以及信息; 在获取到服务 B 的列表之后,就可以通过自身定义的负载均衡算法访问服务 B。
- 心跳 -
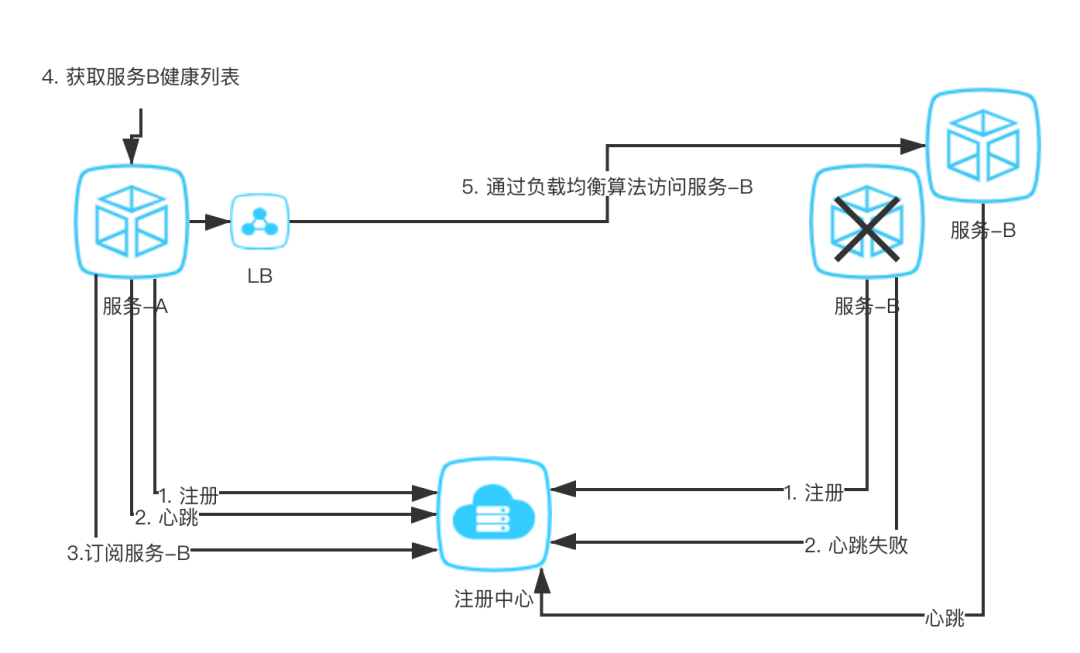
服务 B 的一个节点断网或是 hang 住,引发心跳超时;或是宕机、断链直接引发心跳失败; 注册中心把问题节点从自身的存储中拉出(这里拉出根据具体实现:有的是直接删除,有的是标记为不健康); 服务 A 收到注册中心的通知,获取到服务 B 最新的列表。
- Dubbo 注册中心 -
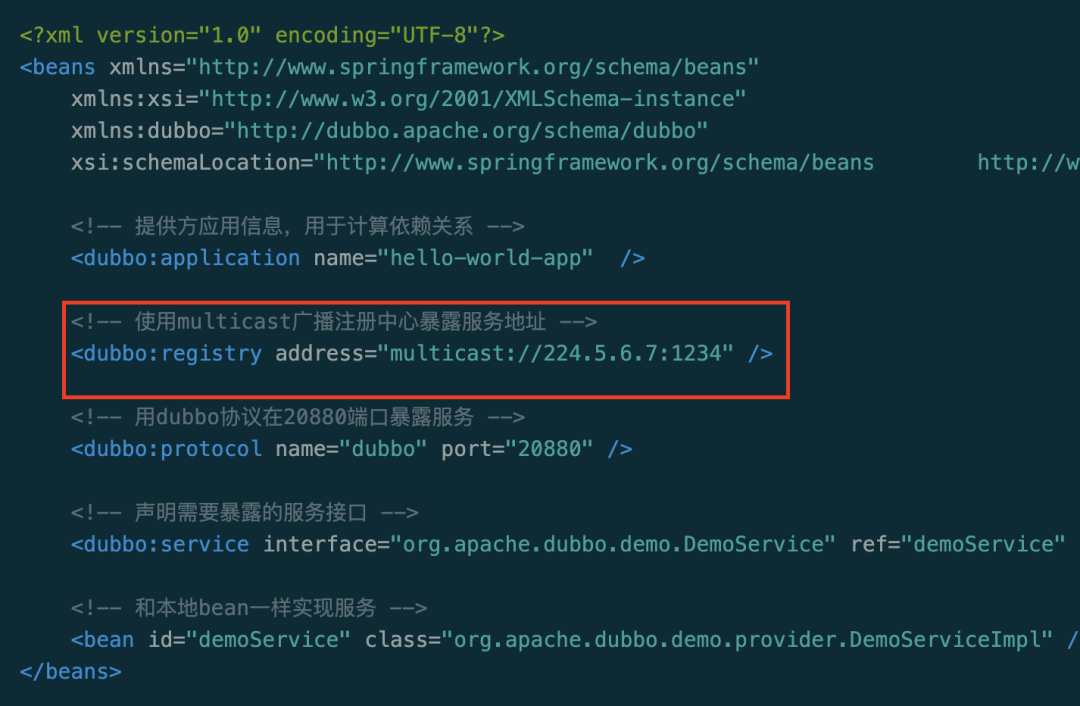
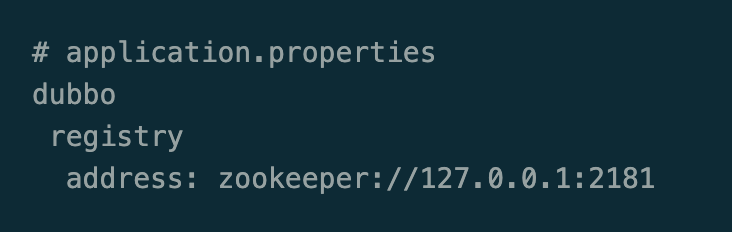
protocol(协议类型)比如,zookeeper; host; port。
服务的生产方通过 Dubbo 客户端向注册中心(Registry)发起注册行为(register); 服务的消费方通过 Dubbo 客户端订阅信息(subscribe); 注册中心通过通知的方式,下发服务列表给服务消费方。
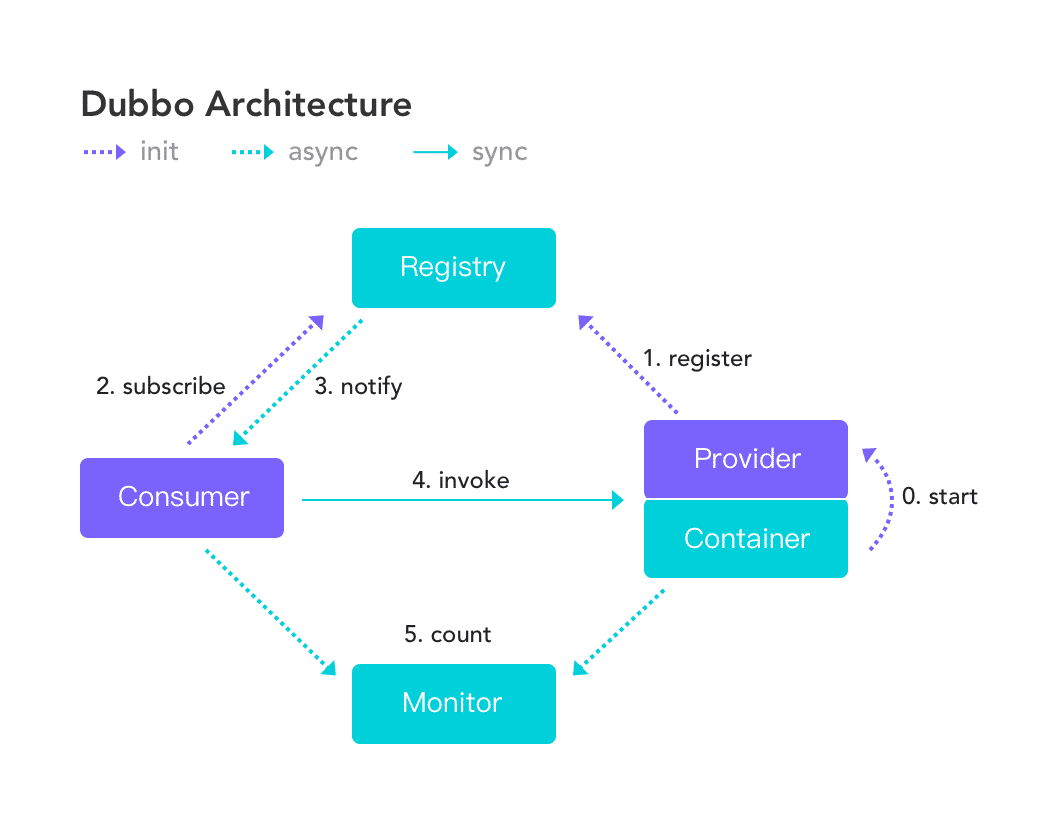
- 注册中心的本质 -
一方面,注册中心需要存储能力去记录服务的信息,比如应用列表; 另一方面,注册中心在实践过程中,需要提供必需的运维手段,比如关闭某一服务流量。

- 蚂蚁注册中心编年史 -
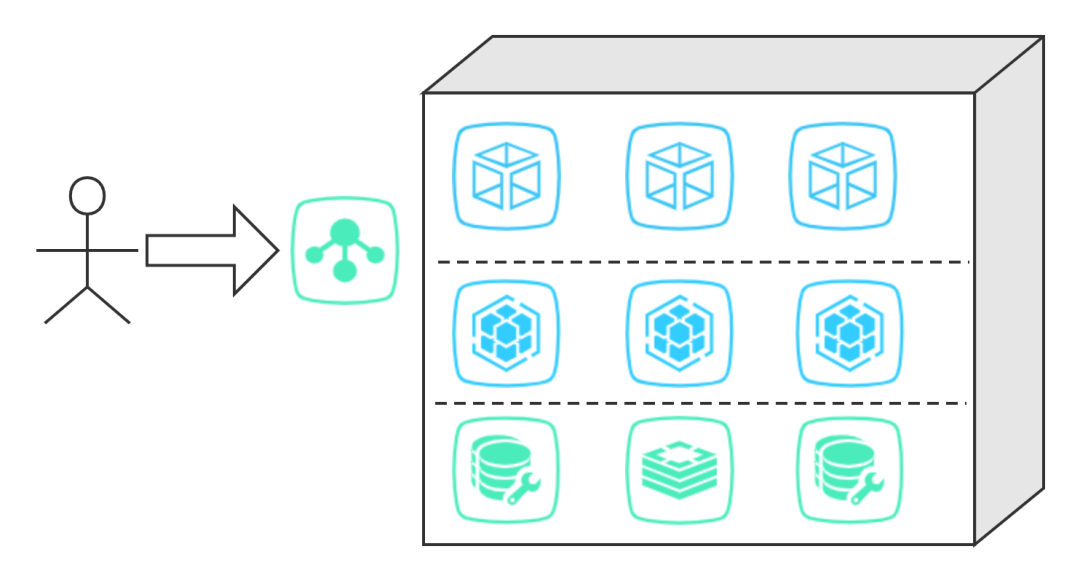
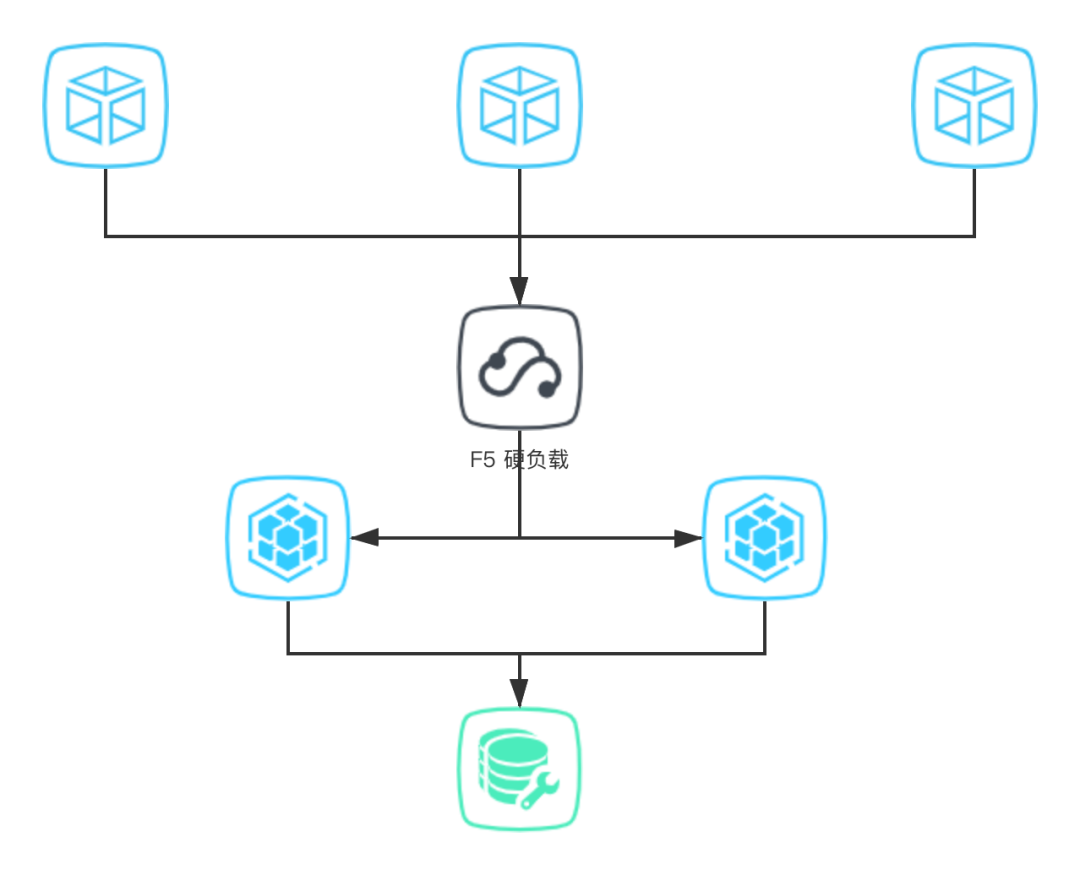
单点的问题(所有调用都走 F5 的话,F5 一旦挂了,很多服务会不可用); 容量问题(F5 承载的流量太高,本身会到一个性能瓶颈)。
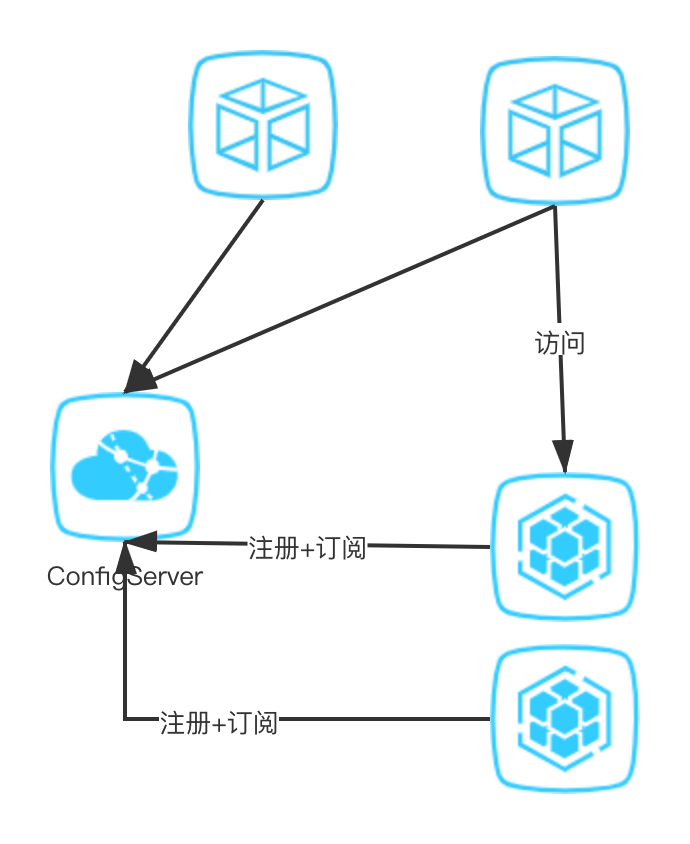
单点风险(注册中心本身是单机应用); 容量瓶颈(单台注册中心的连接数和存储数据的容量是有限的)。
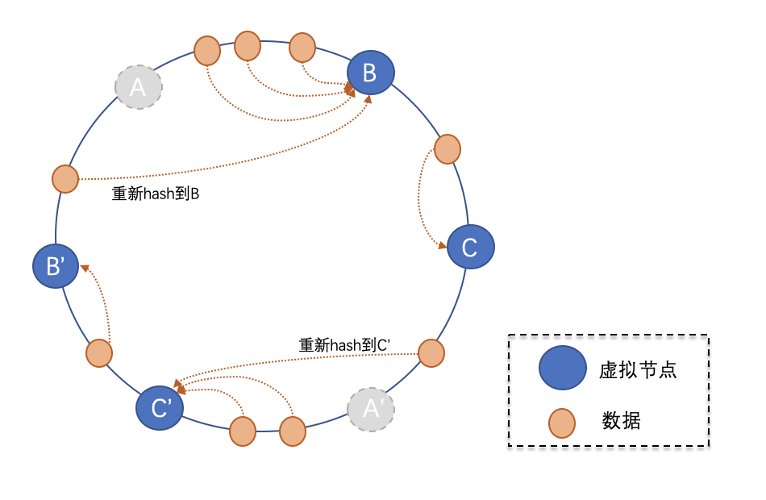
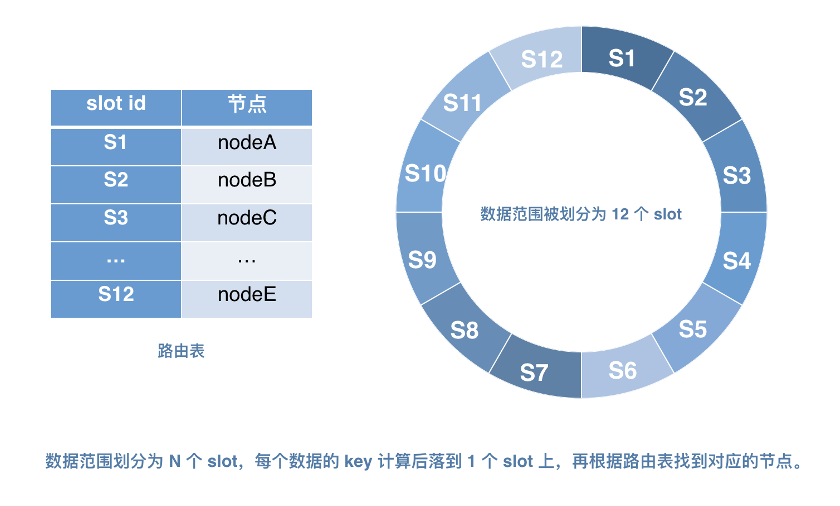
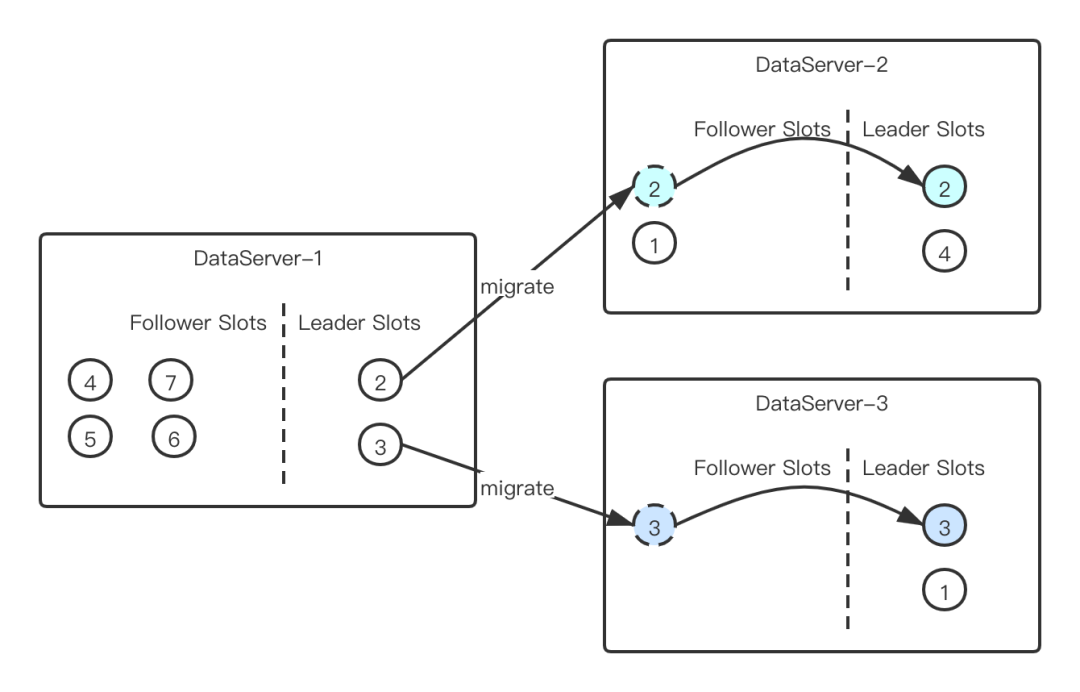
scale-up(淘宝):通过增加机器的配置,来增强容量以及扛链接能力;同时,通过主-备这样的架构,来保障可用性; scale-out(蚂蚁):通过分片机制,将数据和链接均匀分布在多个节点上,做到水平拓展;通过分片之后的备份,做到高可用。
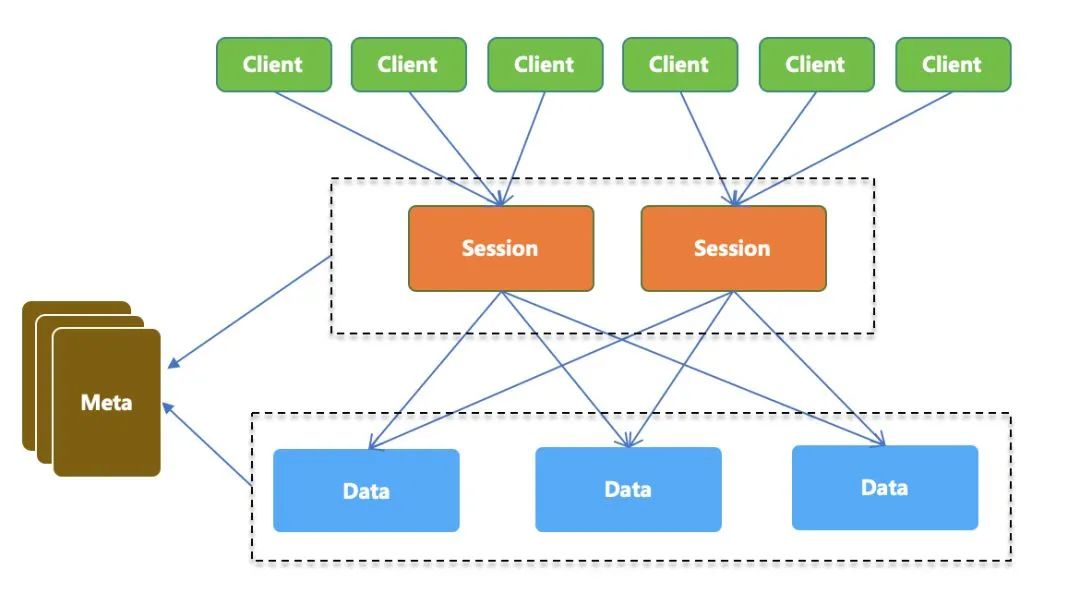
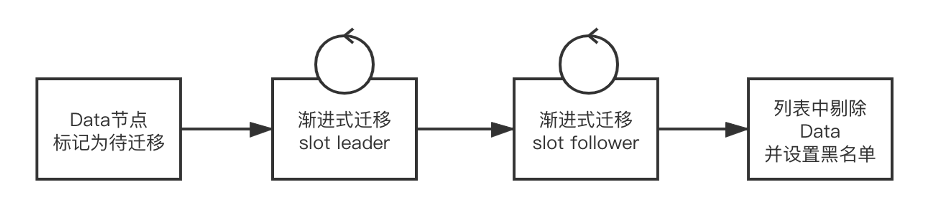
Session 节点,专门用来抗链接使用,本身无状态可以快速扩展,单机对资源的占用很小; Data 节点,专门用来存储数据,通过分片的方式降低单个节点的存储量,控制资源占用。
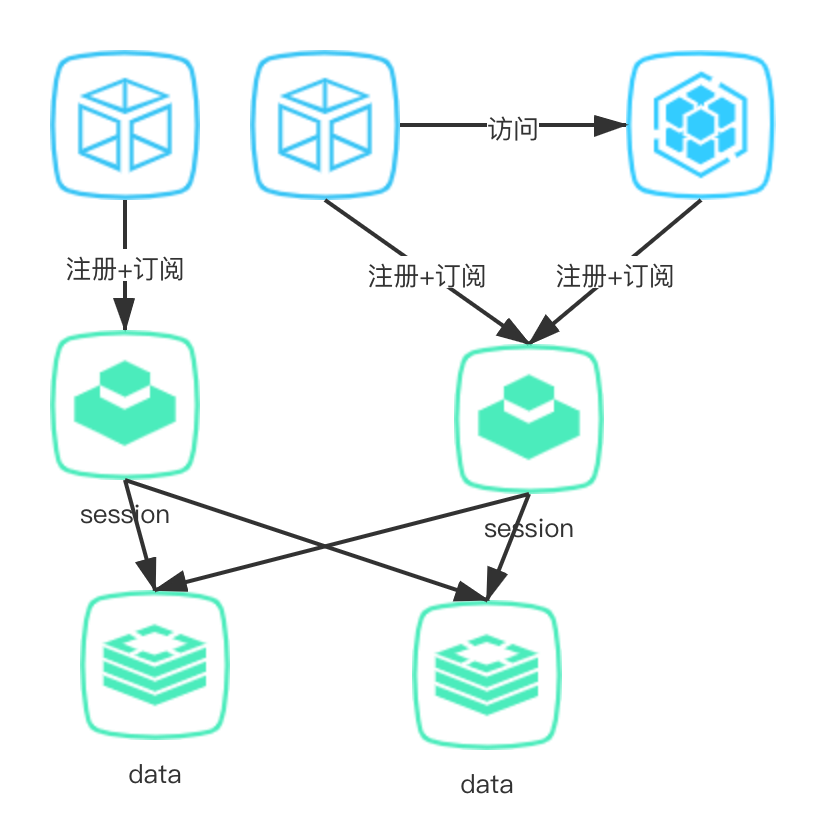
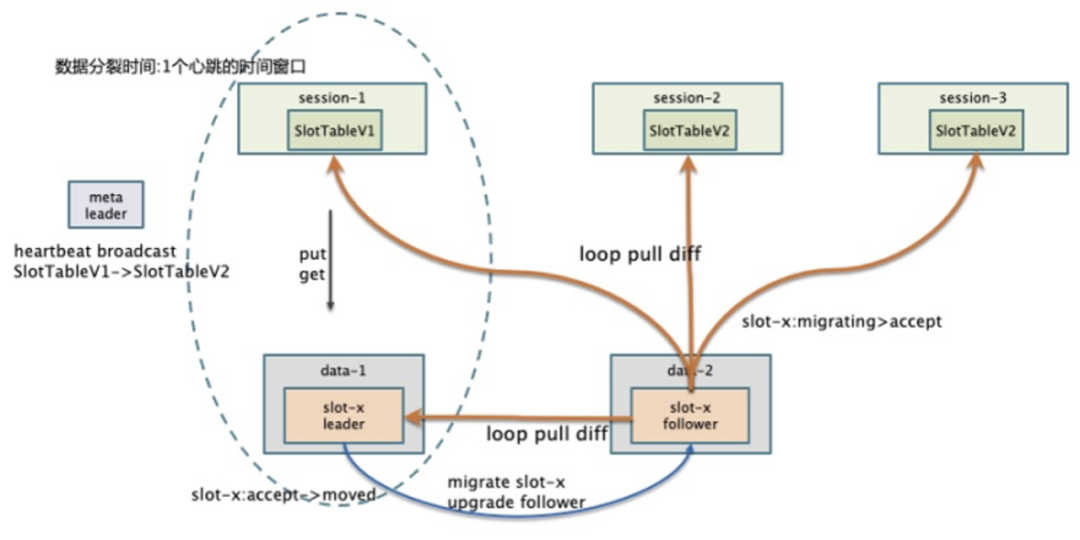
所有 Data 都是分布式的,Data 之间的服务发现需要通过启动时给定一个配置文件,这样就和标准运维脱钩; Data 节点的上下线需要去及时修改配置文件,否则集群重启会受到影响; 分布式存储一致性问题,每次迭代发布,需要锁定 paas 平台,防止节点变动带来的不一致。
- 开源 -
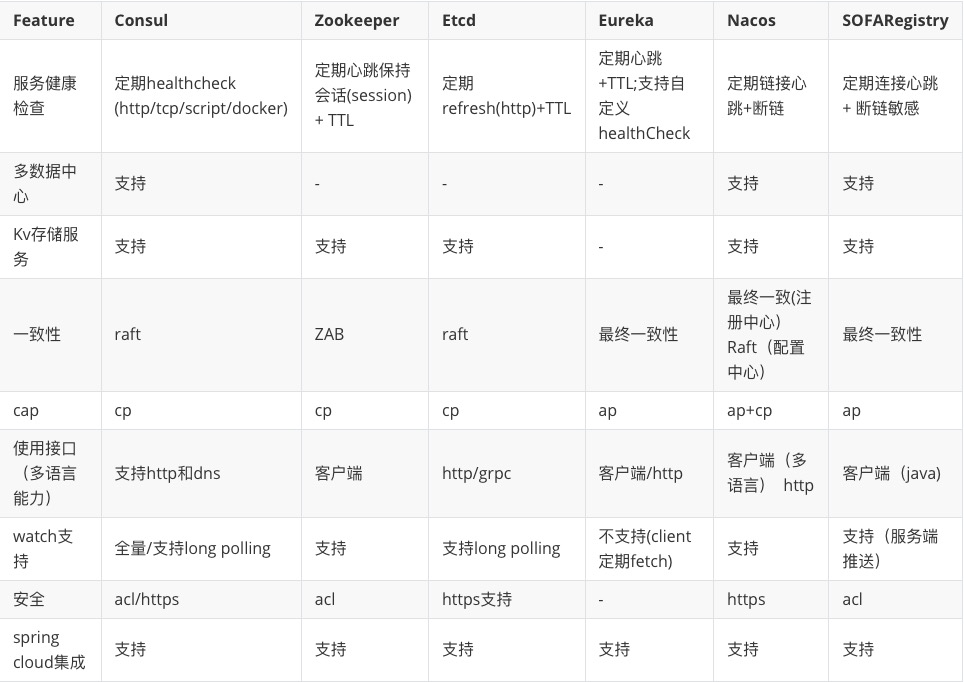
- 共同建设 -
SOFARegistry 是一个开源项目,也是开源社区 SOFA 重要的一环,我们希望用社区的力量推动 SOFARegistry 的前进,而不是只有蚂蚁的工程师去开发。我们在今年也启动了两个项目,用于支持更多的开发者参与进来:
Trun-Key Project (开箱即用计划):
https://github.com/sofastack/sofa-registry/projects/5
Deep-Dive Project(深入浅出计划):
https://github.com/sofastack/sofa-registry/projects/4
计划目前还处在初期阶段,欢迎大家加入进来,可以帮助我们解决一个 issue,或是写一篇文档,都可以更好地帮助社区,帮助自己去成长。

评论