
【小白学习PyTorch教程】二、动态计算图和GPU支持操作
「@Author:Runsen」
动态计算图
在深度学习中使用 PyTorch 的主要原因之一,是我们可以自动获得定义的函数的梯度/导数。
当我们操作我们的输入时,会自动创建一个计算图。该图显示了如何从输入到输出的动态计算过程。
为了熟悉计算图的概念,下面将为以下函数创建一个:
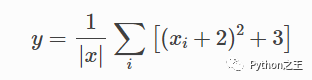
这里的 是我们的参数,我们想要优化(最大化或最小化)输出 . 为此,我们想要获得梯度.
在下面的代码中,我将使用[1,2,3]作输入。
# 只有浮动张量有梯度
x = torch.arange(1,4, dtype=torch.float32, requires_grad=True)
print("X", x)
# X tensor([1., 2., 3.], requires_grad=True)
现在让我来一步一步地构建计算图,了解每个操作是到底是如何添加到计算图中的。
a = x + 2
b = a ** 2
c = b + 3
y = c.mean()
print("Y", y)
# Y tensor(19.6667, grad_fn=<MeanBackward0>)
使用上面的语句,我们创建了一个类似于下图的计算图(通过tensorboard )查看:
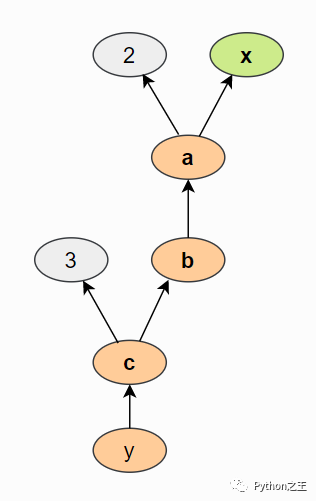 我们计算
我们计算 a 基于输入x 和常数2, b是 a平方等等操作。计算图通常以相反的方向可视化(箭头从结果指向输入)。
我们可以通过backward()在最后一个输出上调用函数来对计算图执行反向传播,这样可以,计算了每个具有属性的张量的梯度requires_grad=True:
y.backward()
最后打印x.grad就可以查看对应梯度。

GPU支持操作
在Pytorch中GPU 可以并行执行数以千计的小运算,因此非常适合在神经网络中执行大型矩阵运算。
「CPU 与 GPU的区别」
| CPU | GPU |
|---|---|
| 中央处理器 | 图形处理单元 |
| 几个核心 | 多核 |
| 低延迟 | 高吞吐量 |
| 适合串行处理 | 适合并行处理 |
| 可以一次做一些操作 | 可以同时进行数千次操作 |
PyTorch 使用GPU,需要搭建NVIDIA 的CUDA和cuDNN。
下面代码,检查是否有可用的 GPU:
gpu_avail = torch.cuda.is_available()
print("Is the GPU available? %s" % str(gpu_avail))
 现在创建一个张量并将其推送到GPU设备:
现在创建一个张量并将其推送到GPU设备:
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print("Device", device)
x = x.to(device)
print("X", x)
# Device cuda
# X tensor([1., 1., 1.], device='cuda:0')
cuda 旁边的零表示这是计算机上的第0个 GPU 设备。因此,PyTorch 还支持多 GPU 系统,
下面将CPU 上的大型矩阵乘法的运行时间与 GPU 上的运算进行比较:
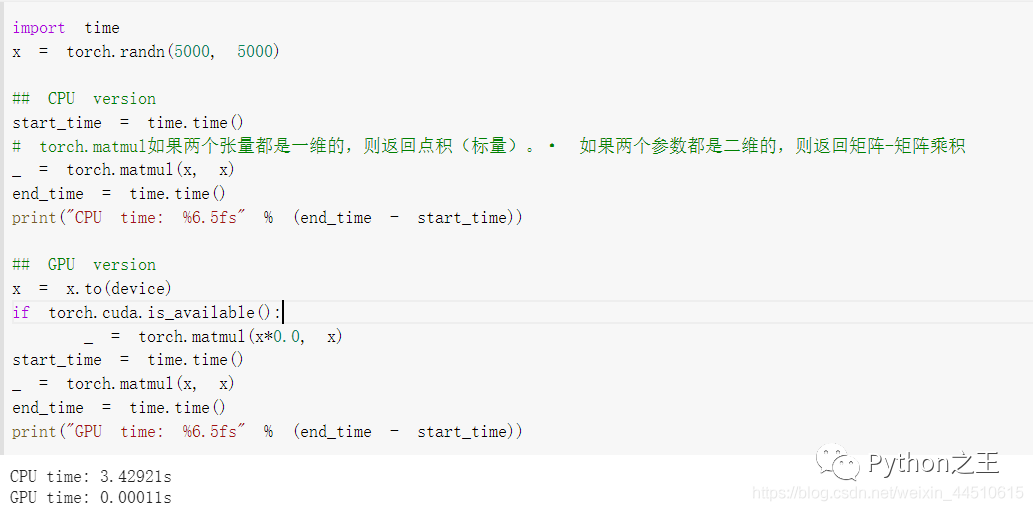
根据系统中的配置而定,GPU加速提高模型的训练速度。
往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论