
【小白学习PyTorch教程】七、基于乳腺癌数据集构建Logistic 二分类模型
「@Author:Runsen」
在逻辑回归中预测的目标变量不是连续的,而是离散的。可以应用逻辑回归的一个示例是电子邮件分类:标识为垃圾邮件或非垃圾邮件。图片分类、文字分类都属于这一类。
在这篇博客中,将学习如何在 PyTorch 中实现逻辑回归。
1. 数据集加载
在这里,我将使用来自 sklearn 库的乳腺癌数据集。这是一个简单的二元类分类数据集。从 sklearn.datasets 模块加载。接下来,可以使用内置函数从数据集中提取 X 和 Y,代码如下所示。
from sklearn import datasets
breast_cancer=datasets.load_breast_cancer()
x,y=breast_cancer.data,breast_cancer.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size=0.2)
在上面的代码中,测试大小表示要用作测试数据集的数据的比例。因此,80% 用于训练,20% 用于测试。
2. 预处理
由于这是一个分类问题,一个好的预处理步骤是应用标准的缩放器变换。
scaler=sklearn.preprocessing.StandardScaler()
x_train=scaler.fit_transform(x_train)
x_test=scaler.fit_transform(x_test)
现在,在使用Logistic 模型之前,还有最后一个关键的数据处理步骤。在Pytorch 需要使用张量。因此,我们使用“torch.from_numpy()”方法将所有四个数据转换为张量。
在此之前将数据类型转换为 float32很重要。可以使用“astype()”函数来做到这一点。
import numpy as np
import torch
x_train=torch.from_numpy(x_train.astype(np.float32))
x_test=torch.from_numpy(x_test.astype(np.float32))
y_train=torch.from_numpy(y_train.astype(np.float32))
y_test=torch.from_numpy(y_test.astype(np.float32))
我们知道 y 必须采用列张量而不是行张量的形式。因此,使用代码中所示的view操作执行此更改。对 y_test 也做同样的操作。
y_train=y_train.view(y_train.shape[0],1)
y_test=y_test.view(y_test.shape[0],1)
预处理步骤完成,您可以继续进行模型构建。
3. 模型搭建
现在,我们已准备好输入数据。让我们看看如何在 PyTorch 中编写用于逻辑回归的自定义模型。第一步是用模型名称定义一个类。这个类应该派生torch.nn.Module。
在类内部,我们有__init__ 函数和 forward函数。
class Logistic_Reg_model(torch.nn.Module):
def __init__(self,no_input_features):
super(Logistic_Reg_model,self).__init__()
self.layer1=torch.nn.Linear(no_input_features,20)
self.layer2=torch.nn.Linear(20,1)
def forward(self,x):
y_predicted=self.layer1(x)
y_predicted=torch.sigmoid(self.layer2(y_predicted))
return y_predicted
在__init__方法中,必须在模型中定义所需的层。在这里,使用线性层,可以从 torch.nn 模块声明。需要为图层指定任何名称,例如本例中的“layer1”。所以,我已经声明了 2 个线性层。
语法为:torch.nn.Linear(in_features, out_features, bias=True)接下来,也要有“forward()”函数,负责执行前向传递/传播。输入通过之前定义的 2 个层。此外,第二层的输出通过一个称为 sigmoid的激活函数。
激活函数用于捕捉线性数据中的复杂关系。在这种情况下,我们使用 sigmoid 激活函数。
在这种情况下,我们选择 sigmoid 函数的原因是它会将值限制为(0 到 1)。下面是 sigmoid 函数的图形及其公式
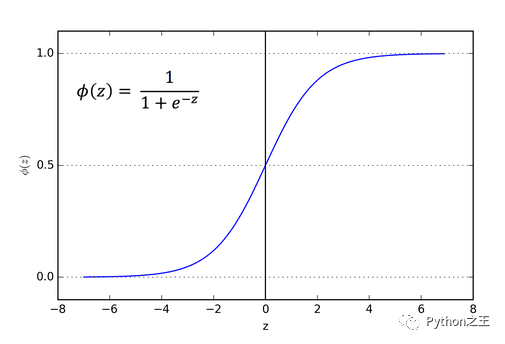
4. 训练和优化
定义类后,初始化模型。
model=Logistic_Reg_model(n_features)
现在,需要定义损失函数和优化算法。在 Pytorch 中,可以通过简单的步骤选择并导入所需的损失函数和优化算法。在这里,选择 BCE 作为我们的损失标准。
BCE代表二元交叉熵损失。它通常用于二元分类示例。值得注意的一点是,当使用 BCE 损失函数时,节点的输出应该在(0-1)之间。我们需要为此使用适当的激活函数。
对于优化器,选择 SGD 或随机梯度下降。SGD 算法,通常用作优化器。还有其他优化器,如 Adam、lars 等。
优化算法有一个称为学习率的参数。这基本上决定了算法接近局部最小值的速率,此时损失最小。这个值很关键。
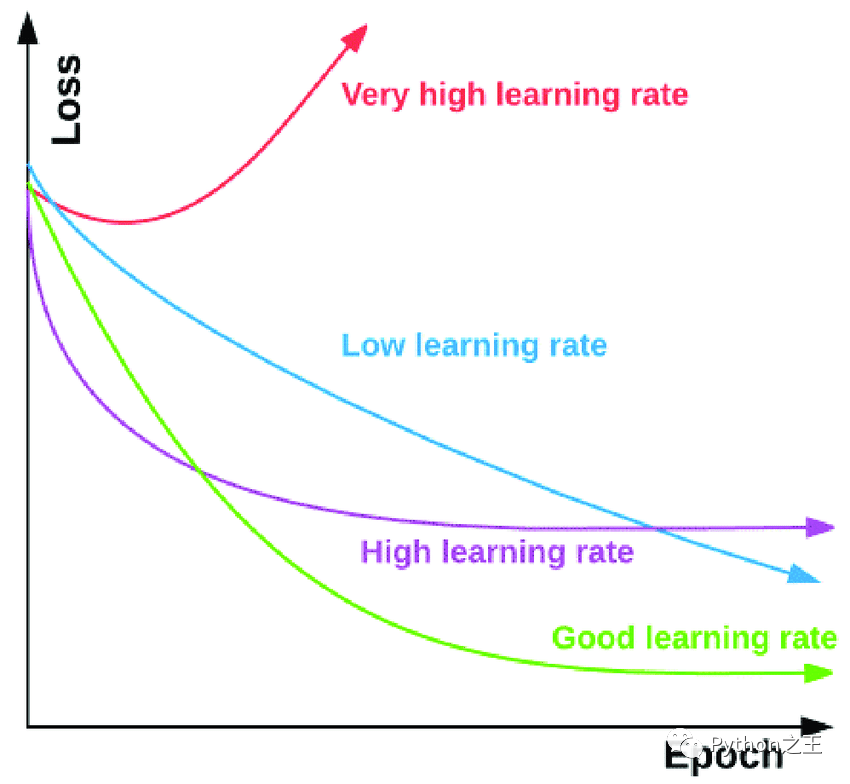
因为如果学习率值太高,算法可能会突然出现并错过局部最小值。如果它太小,则会花费大量时间并且可能无法收敛。因此,学习率“lr”是一个超参数,应该微调到最佳值。
criterion=torch.nn.BCELoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
接下来,决定 epoch 的数量,然后编写训练循环。
number_of_epochs=100
for epoch in range(number_of_epochs):
y_prediction=model(x_train)
loss=criterion(y_prediction,y_train)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if (epoch+1)%10 == 0:
print('epoch:', epoch+1,',loss=',loss.item())
如果发生了第一次前向传播。接下来,计算损失。当loss.backward()被调用时,它计算损失相对于(层的)权重的梯度。然后通过调用optimizer.step()更新权重。之后,必须为下一次迭代清空权重。因此调用 zero_grad()方法。
 计算准确度
计算准确度
with torch.no_grad():
y_pred=model(x_test)
y_pred_class=y_pred.round()
accuracy=(y_pred_class.eq(y_test).sum())/float(y_test.shape[0])
print(accuracy.item())
# 0.92105
使用torch.no_grad(),目的是基跳过权重的梯度计算。所以,我在这个循环中写的任何内容都不会导致权重发生变化,因此不会干扰反向传播过程。