
Kyuubi 实践 | 放弃 Spark Thrift Server 吧,你需要的是 Apache Kyuubi!
饱受诟病的Spark Thrift Server
关于Kyuubi
编译Kyuubi For Spark 3.1 & Hadoop 3.2
下载Kyuubi源码包
安装scala编译环境
编译
构建发行版
在YARN上部署Kyuubi引擎
上传解压Kyuubi安装包
创建快捷方式
测试Hadoop/Spark环境
配置Kyuubi环境
配置环境变量
配置Spark参数
启动Kyuubi
解决端口冲突问题
配置Kyuubi HA
重新启动
测试Kyuubi
配置spark用户代理权限
重新使用beeline测试
饱受诟病的Spark Thrift Server
Spark用户大都知道有个组件叫Spark Thrift Server,它可以让Spark应用启动在YARN上,并对外提供JDBC服务。
如果有一些数据服务、或者BI查询,
使用Thrift Server是比较快的。
但实际我们在生产上几乎没法用Thrift Server做一些重要的应用。
因为它并不可靠,在较高的并发负载下,容易会出现莫名的卡死、泄漏,
而且也没法实现用户资源的隔离,
支持的数据源也有限,
之前我们也测试过,踩了不少坑。
所以迫于无奈,
我们选择了基于Livy来做一些即席查询的工作。
但Livy的限制非常明显,它是以HTTP REST方式来提交要执行的代码。
通过Livy,我们可以实现用户之间的资源隔离。
但每次在查询时,使用Livy体验并不是很好。
每次申请资源,都需要等待一段时间来启动Spark Driver,并申请资源。
而且,没法对外提供Thrift或者JDBC服务。
针对同一用户也无法实现资源的共用,
一个用户可能会创建很多的应用。
而今天给大家带来的是Apache Kyuubi。

关于Kyuubi
Kyuubi 是一个分布式多租户 Thrift JDBC/ODBC 服务器,用于大规模数据管理、处理和分析,构建在 Apache Spark 之上。
这一句话就把Kyuubi介绍清楚了。
注意关键字:基于Spark、多租户、Thrift JDBC/ODBC服务器。
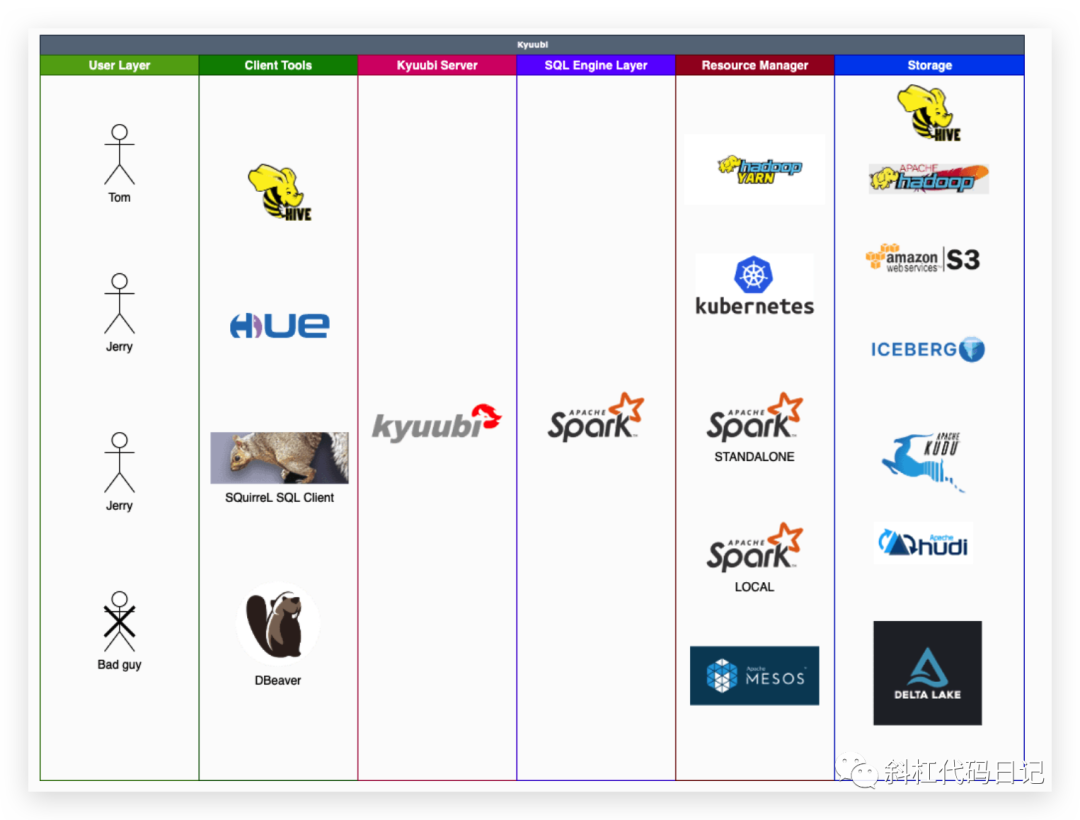
大家可以看到,Kyuubi支持的存储、客户端工具是比较丰富的。尤其是对数据湖组件支持比较好。赞赞赞!
其他介绍大家可以去看下官网:https://kyuubi.apache.org/docs/latest/index.html。
这里,不多说了。直接开始作业吧。
编译Kyuubi For Spark 3.1 & Hadoop 3.2
下载Kyuubi源码包
https://github.com/apache/incubator-kyuubi/archive/refs/tags/v1.3.0-incubating.zip
安装scala编译环境
因为Kyuubi是用scala。如果没有scala 2.12.14就会自动下载。这个过程会比较慢,建议还是提前下载scala-2.12.14,然后放入到kyuubi的build目录。scala 2.12.14下载地址为:https://downloads.lightbend.com/scala/2.12.14/scala-2.12.14.tgz
编译
./build/mvn clean package -DskipTests -P mirror-cn -P spark-3.1 -P spark-hadoop-3.2
大家可以查看下pom.xml中的Profile来编译指定组件版本对应的Kyuubi。
期间,Maven会下载一些依赖的包。成功编译会提示如下:
[INFO] Kyuubi Project Parent .............................. SUCCESS [ 41.108 s]
[INFO] Kyuubi Project Common .............................. SUCCESS [06:22 min]
[INFO] Kyuubi Project Embedded Zookeeper .................. SUCCESS [ 7.426 s]
[INFO] Kyuubi Project High Availability ................... SUCCESS [ 10.869 s]
[INFO] Kyuubi Project Control ............................. SUCCESS [ 13.458 s]
[INFO] Kyuubi Project Metrics ............................. SUCCESS [ 16.678 s]
[INFO] Kyuubi Project Download Externals .................. SUCCESS [ 26.663 s]
[INFO] Kyuubi Project Spark Monitor ....................... SUCCESS [ 11.792 s]
[INFO] Kyuubi Project Engine Spark SQL .................... SUCCESS [ 30.331 s]
[INFO] Kyuubi Project Server .............................. SUCCESS [ 23.617 s]
[INFO] Kyuubi Project Dev Code Coverage ................... SUCCESS [ 0.228 s]
[INFO] Kyuubi Project Assembly ............................ SUCCESS [ 0.334 s]
[INFO] Kyuubi Project Hive JDBC Client .................... SUCCESS [ 7.173 s]
构建发行版
./build/dist --tgz --spark-provided
构建完后,会在目录下生成一个tgz包。
[root@compile incubator-kyuubi-1.3.0-incubating]# ll -l | grep kyuubi
-rw-r--r--. 1 root root 60369276 9月 24 11:57 apache-kyuubi-1.3.0-incubating-bin.tgz
在YARN上部署Kyuubi引擎
部署的前提是我们提前整合好 spark on yarn。
此处省略,因为我们的Spark已经整合好了Hive、以及Hudi,并做好了基本的配置。
大家如果不熟悉这一块,可以自行参考Spark官网来配置整合。
上传解压Kyuubi安装包
tar -xvzf apache-kyuubi-1.3.0-incubating-bin.tgz -C /opt/
创建快捷方式
n -s /opt/apache-kyuubi-1.3.0-incubating-bin/ /opt/kyuubi
测试Hadoop/Spark环境
spark-submit \
--master yarn \
--queue root.p1 \
--class org.apache.spark.examples.SparkPi \
/opt/spark/examples/jars/spark-examples_2.12-3.1.1.jar \
10
如果程序能够成功输出以下:
Pi is roughly 3.1420391420391423
表示环境测试成功,可以开始正常部署Kyuubi。
配置Kyuubi环境
kyuubi-env.sh
cd /opt/kyuubi/conf
cp kyuubi-env.sh.template kyuubi-env.sh
vim kyuubi-env.sh
export JAVA_HOME=/opt/jdk1.8.0_181/
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export KYUUBI_JAVA_OPTS="-Xmx10g -XX:+UnlockDiagnosticVMOptions -XX:ParGCCardsPerStrideChunk=4096 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseCondCardMark -XX:MaxDirectMemorySize=1024m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./logs -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -Xloggc:./logs/kyuubi-server-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=5M -XX:NewRatio=3 -XX:MetaspaceSize=512m"
下面的这个是JVM的配置。我注意到了它配置了堆内存最大为10G、Metaspace是512M、使用的是CMS GC、直接内存是1GB。这个配置比较符合我们的测试集群。大家可以按照自己的测试环境来调整。
kyuubi-defaults.conf
cp kyuubi-defaults.conf.template kyuubi-defaults.conf
vim kyuubi-defaults.conf
kyuubi.frontend.bind.host hadoop1
kyuubi.frontend.bind.port 10009
配置环境变量
vim ~/.bashrc
export KYUUBI_HOME=/opt/kyuubi
export PATH=$KYUUBI_HOME/bin:$PATH
source ~/.bashrc
配置Spark参数
Kyuubi应用其实就是启动在YARN上的Spark应用,它也需要使用spark-submit提交应用到YARN。
而提交Spark应用的参数,我们可以配置对应的默认参数。
有以下几种配置方式:
使用JDBC URL配置
jdbc:hive2://localhost:10009/;#spark.master=yarn;spark.yarn.queue=thequeue在kyuubi-default.conf中配置
在spark-defaults.conf中配置
Kyuubi推荐我们使用Spark的动态资源分配方式,避免资源一直占用。
大家可以看下我之前写的Spark动态资源分配文章。
优化点:可以配置spark.yarn.archive或者spark.yarn.jars指向HDFS上的地址,这样不需要在启动应用时每次都分发JAR包。
启动Kyuubi
# 启动
bin/kyuubi start
# 关闭
bin/kyuubi stop
解决端口冲突问题
执行start启动后,报错如下:
Exception in thread "main" java.net.BindException: Address already in use
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:67)
at org.apache.zookeeper.server.NIOServerCnxnFactory.configure(NIOServerCnxnFactory.java:90)
at org.apache.kyuubi.zookeeper.EmbeddedZookeeper.initialize(EmbeddedZookeeper.scala:53)
at org.apache.kyuubi.server.KyuubiServer$.startServer(KyuubiServer.scala:38)
at org.apache.kyuubi.server.KyuubiServer$.main(KyuubiServer.scala:76)
at org.apache.kyuubi.server.KyuubiServer.main(KyuubiServer.scala)
发现KyuubiServer报错端口占用,但不知道占用的是哪个端口。看先源码,
private val zkServer = new EmbeddedZookeeper()
def startServer(conf: KyuubiConf): KyuubiServer = {
if (!ServiceDiscovery.supportServiceDiscovery(conf)) {
zkServer.initialize(conf)
zkServer.start()
conf.set(HA_ZK_QUORUM, zkServer.getConnectString)
conf.set(HA_ZK_ACL_ENABLED, false)
}
val server = new KyuubiServer()
server.initialize(conf)
server.start()
Utils.addShutdownHook(new Runnable {
override def run(): Unit = server.stop()
}, Utils.SERVER_SHUTDOWN_PRIORITY)
server
}
看下源码,如果检测到没有配置服务发现,就会默认使用的是内嵌的ZooKeeper。当前,我们并没有开启HA模式。所以,会启动一个本地的ZK,而我们当前测试环境已经部署了ZK。所以,基于此,我们还是配置好HA。这样,也可以让我们Kyuubi服务更加可靠。
配置Kyuubi HA
vim /opt/kyuubi/conf/kyuubi-defaults.conf
kyuubi.ha.enabled true
kyuubi.ha.zookeeper.quorum hadoop1,hadoop2,hadoop3,hadoop4,hadoop5
kyuubi.ha.zookeeper.client.port 2181
kyuubi.ha.zookeeper.session.timeout 600000
重新启动
配置好HA后,重新启动即可。这里,我们先启动一个Kyuubi Server。如果启动多个,Kyuubi是实现了负载均衡的。
Welcome to
__ __ __
/\ \/\ \ /\ \ __
\ \ \/'/' __ __ __ __ __ __\ \ \____/\_\
\ \ , < /\ \/\ \/\ \/\ \/\ \/\ \\ \ '__`\/\ \
\ \ \\`\\ \ \_\ \ \ \_\ \ \ \_\ \\ \ \L\ \ \ \
\ \_\ \_\/`____ \ \____/\ \____/ \ \_,__/\ \_\
\/_/\/_/`/___/> \/___/ \/___/ \/___/ \/_/
/\___/
\/__/
检查Kyuubi启动情况:
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 10.94.158.51:10009 0.0.0.0:* LISTEN 25803/java
我们看了下yarn集群,当前没有启动任何的应用。
接下来,我们使用Hive的beeline来连接下Kyuubi。
测试Kyuubi
注意:使用Spark中的beeline,Hive的beeline有可能客户端比较老,连接Kyuubi会报错。
/opt/spark/bin/beeline
!connect jdbc:hive2://hadoop1:10009/;#spark.yarn.queue=root.p1
我们发现连接报错:
Caused by: org.apache.kyuubi.KyuubiSQLException: 21/09/24 15:38:12 INFO org.apache.hadoop.io.retry.RetryInvocationHandler: org.apache.hadoop.security.authorize.AuthorizationException: User: spark is not allowed to impersonate hive, while invoking ApplicationClientProtocolPBClientImpl.getClusterMetrics over rm1 after 2 failover attempts. Trying to failover after sleeping for 24076ms.
这个问题是hadoop抛出来的,意思是Spark用户不允许扮演hive用户的。我们需要给Spark用户配置开启Hadoop代理。
配置spark用户代理权限
vim core-site.xml
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
分发配置文件到所有Hadoop节点,重启HADOOP集群。
重新使用beeline测试
/opt/spark/bin/beeline
!connect jdbc:hive2://hadoop1:10009/;#spark.yarn.queue=root.p1
第一次启动比较慢,当我们在YARN中可以看到以下应用展示表示配置成功:

在Spark的Web UI我们能看到:
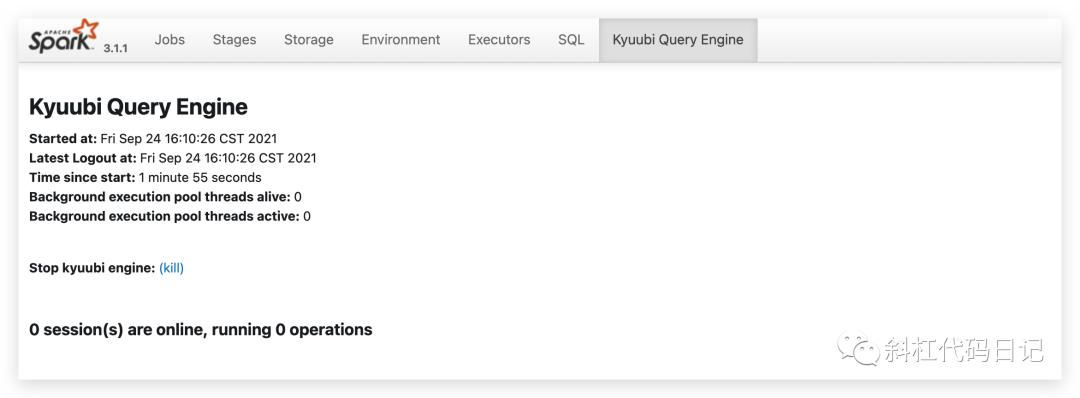
在beeline中,显示如下:
beeline> !connect jdbc:hive2://hadoop1:10009/;#spark.yarn.queue=root.p1
Connecting to jdbc:hive2://hadoop1:10009/;#spark.yarn.queue=root.p1
Enter username for jdbc:hive2://hadoop1:10009/: spark
Enter password for jdbc:hive2://hadoop1:10009/:
Connected to: Spark SQL (version 1.3.0-incubating)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop1:10009/>
执行几条SQL测试下。
再试下hive用户:
/opt/spark/bin/beeline
!connect jdbc:hive2://hadoop1:10009/;#spark.yarn.queue=root.p1
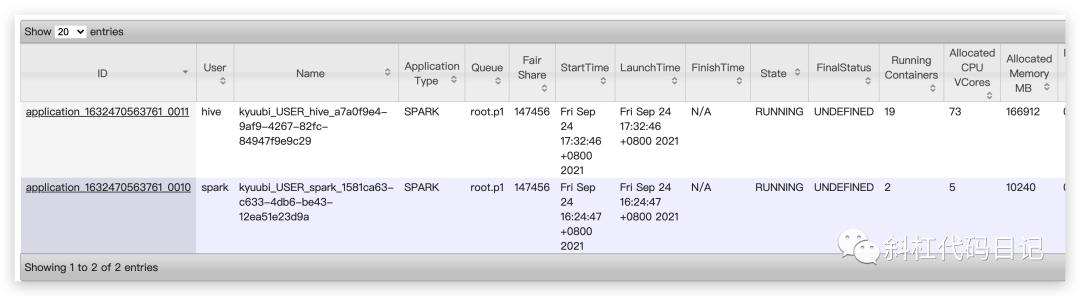
多个用户是相互隔离的。通过用户来隔离不同的Thrift Server。厉害厉害!
Enjoy!
参考文献:
[1] https://kyuubi.apache.org/
作者|斜杠代码日记
关注我
分享Java、大数据技术干货