
(抛砖引玉)TensorRT的FP16不得劲?怎么办?在线支招!

极市导读
本文讲述了作者在使用TensorRT转换FP16模型时出现了动态范围和精度不够,导致某个op节点的计算值溢出了。后续作者通过二分查找op层的方法找到了问题所在并给出了详细的步骤代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
问题的开始
前些天尝试使用TensorRT转换一个模型,模型用TensorFlow训练,包含LSTM+Transform+CNN,是一个典型的时序结构模型,包含编码解码结构,暂称为debug.onnx吧。
这个debug.onnx使用tf2onnx[1]导出,导出后tf2onnx会自动对这个onnx做一些优化,例如常量折叠、算子融合等等一些常规操作,一般来说这些操作不会影响网络结构(也会出现影响的情况!之后老潘会说),而且有助于模型的优化。
然后导出来之后使用onnxruntime简单测试一下导出模型是否正确,是否与TensorFlow的结果一致。如果正确我们再进行下一步。
模型体积不大(30MB左右),但是op节点很多,以至于使用Netron打开前会提示:
嗯?不就是个警告么,Yes就行!
然后等了N久(1个小时),还是提示打不开,节点太多了-_-||。
实在打不开咋办,可以通过onnx的python接口读取onnx模型,然后将网络结构打印出来:
import onnxmodel_path = '/home/oldpan/code/models/debug.onnx'onnx_model = onnx.load(model_path)onnx.checker.check_model(onnx_model)f = open('net.txt', 'w+')print(onnx_model, file=f)f.close()
这里将onnx_model的网络结构输出为net.txt,好了,打开这个txt慢慢看吧。
(fun) oldpan@oldpan-fun:~/code$ cat net.txt | headir_version: 4producer_name: "tf2onnx"producer_version: "1.6"graph {node {input: "input.1"input: "conv1.weight"output: "340"op_type: "Conv"attribute {
老潘这里提一句,并不是模型体积大才代表模型复杂,模型大小只会影响这个模型占用内存或者显存的量,整个模型执行的时间与其中的OP计算量也是有关系的。
PS:还是检测类的模型好一些,没有错综复杂的op,全是卷积一块一块的,简单粗暴。
FP32与FP16的代沟
好了!有这个debug.onnx模型,使用TensorRT自带的trtexec转换一下吧。
这里使用的TensorRT是最新的TensorRT-7.2.3.4版本,使用的显卡为RTX2080Ti。
转换过程中没有任何问题,除了是有一些int64截断和Type的警告,但是一般来说这种警告对结果是没有影响的(如果有有影响的例子,请告诉我~):

转化好之后,简单测试下FP32的结果是正确的,看起来不错,对比了下FP32与TensorFlow原生推理的精度,精度相差不多(万分之一的差距),还是有使用价值的。
简单测一下速度,嗯...相较TensorFlow原来差不多500Q的速度,FP32也才550Q,提升10%不到啊。
还咩有具体看每个层的耗时,老潘初步推断,整个模型中的op比较多也比较复杂,不是那种像VGG、unet这个一大块一大块卷积相连的,更多的是一些细小的op,TensorRT优化起来作用并不大。怎么形容,一个resnet50转化为onnx的node节点数也就150左右,而我们的这个debug.onnx模型足足有3000多个node节点,转化为TensorRT格式的时候使用trt_network->getNbLayers();看了下,debug.trt足足有9000多个节点。
哦mygodholyshit。

好了不纠结那么多,能转过来就好。
让我试试FP16的速度咋样吧,嗯,1000Q,差不多500q的两倍,还是有收益的。以上实验是在RTX2080TI上做的,20系列有FP16计算单元,所以模型转化为FP16是有速度收益的。如果我们用的是1080TI,那么模型转化为FP16只有模型体积的缩小,模型运行速度并不会提升,反而会有下降。
测试一下FP16的结果
铺垫那么多...FP16的提速固然是可喜的,但是结果完全不对。

输出的置信度和标签完全不对。
正确的结果[24,23,4,5,2],[1.000,0.99,0.99,0.99,1.0]。
错误的结果[5,5,5,5,7],[0.768,0.65,0.5,0.5,0.3]。
肿么办,肿么办,完全没有头绪,感觉FP16和FP32的代沟还挺大的。
想要弄清楚原因,首先要明白什么是FP16。
关于FP16
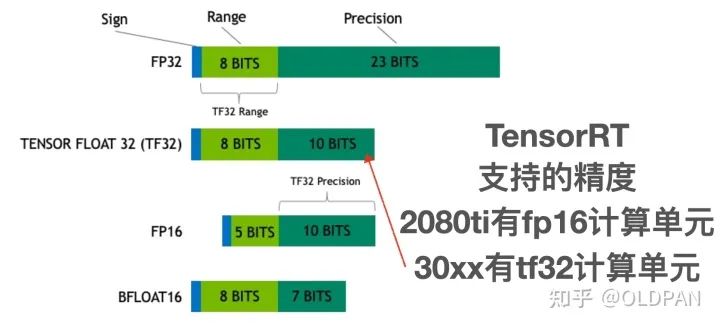
FP16之所以计算那么快,最重要的原因是因为FP16只占两个字节,相比FP32所占的内存更小,实现的指令也比FP32更快。有专门FP16计算单元的显卡,相比FP32,FP16的flops往往都很高。
比如RTX2080TI。Peak Fp16 Tflops为26.9而Peak Fp32 Tflops为13.4,几乎两倍多的差距。很显然使用FP16不论是推理还是训练都会比FP32快一些。
不过FP16快是快,但因为指数位和尾数位都比FP32要小,其动态范围和精度也大大减小了,如果一个数超出了FP16的动态范围,那么显然是会溢出的。
寻找结果错误原因
由上所述,问题的原因应该比较明了了,大概率是模型中某一层的计算FP16因为动态范围和精度不够,导致某个op节点的计算值溢出了。然后牵一发而动全身,整个模型后面的所有层都崩了。
而这种情况最直接最简单寻找问题op的方法就是逐层打印输出观察,然后从输入到输出每一层对比输出结果观察哪一层出问题了。
但是对于转化后的TensorRT模型我们并不能做到这一点,呃 。
为啥,因为TensorRT会对构建好的模型进行一些fuse模型算子融合操作,以及一些我们不清楚的优化,但仅仅是算子融合操作,就有可能让原先的层结构面目全非。
举个例子,我们常见的模型优化有CONV+BN+RELU优化,在推理的时候提前将BN层学习到的两个参数融到卷积操作中,而激活层的操作也可以融入到前面那一层中,减少数据在每个层之间传输导致时间的消耗,从而提升网络推理的时间。
TensorRT的介绍中也举过例子:
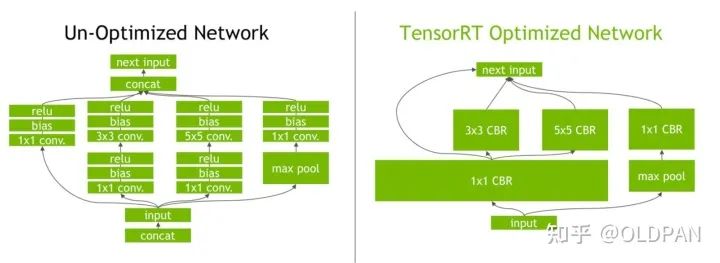
比如上图左面的3x3Conv+bias+relu原本是三个层,但是到了右边就被TensorRT合并为一个层3x3 CBR了,原先的层已经不是之前的那个层了,"他们合体了"。
其实算子op融合已经是比较常见和常用的优化了,很多推理框架都做了类似的事情,不止TensorRT,TVM、OpenVino、NCNN等推理框架都做了相关算子优化。下面是NCNN中对算子op做优化的一些函数。感兴趣的可以去NCNN的github仓库看看。
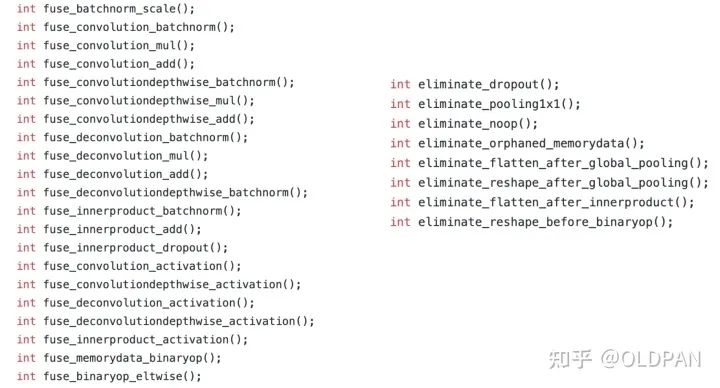
而TensorRT类似于一个黑盒子,最重要的infer没有开源,只开源了解释器。我们只能通过debug信息得知它对哪些层做了哪些优化,但这对寻找FP16问题并没有什么帮助。
阻止TensorRT的优化
有没有阻止TensorRT对某些层进行优化,并且打印这个层输出信息的方法?
有,这个问题不止老潘遇到,github官方issue中已经回答过:
Disabling Layer Fusion It turns out there is a workaround to disable layer fusion for debugging purposes. When you mark a layer as a network output (network.mark_output(layer)), we must keep the results after that layer is executed, so it will disable the layer fusion optimizations that involve that layer fusing with the layer afterwards. It's a very useful way of debugging a network. When trying to figure out if a certain layer is causing probems, you can do a binary search of marking layers as outputs to find it.
单纯阻止TensorRT优化是关不掉的,官方没有暴露这个API出来(可能就没有写)。但是我们可以通过_importer_ctx.network()->markOutput(*new_output_tensor_ptr);这个函数来手动设置模型输出(模型输出默认是通过graph.output()来设定)。
这个函数在哪儿,在onnx-tensorrt这个前端解释器中。
TensorRT虽然没有开源infer,但是parser,也就是解释器是开源的。解释器是干嘛的,解释器就是将你提供的模型转化为符合TensorRT网络结构的模型。
也就是将上文debug.onnx这个模型转换为debug.trt,当然解释器只负责读取debug.onnx的权重以及节点信息,然后将转换好的模型给infer,最终的优化还是TensorRT的infer做的。
举个例子,比如MatMul这个op,TensorRT的解释器遇到这个op会将其转化为TensorRT的网络结构,看到这个函数了么,ctx->network()->addMatrixMultiply(),解释器会根据导入模型的节点按图拓扑顺序搭建TensorRT的网络节点。
DEFINE_BUILTIN_OP_IMPORTER(MatMul){nvinfer1::ITensor* inputA = &convertToTensor(inputs.at(0), ctx);nvinfer1::ITensor* inputB = &convertToTensor(inputs.at(1), ctx);// TRT does not support INT32 input types for this nodeASSERT(inputA->getType() == inputB->getType() && inputA->getType() != nvinfer1::DataType::kINT32, ErrorCode::kUNSUPPORTED_NODE);broadcastTensors(ctx, inputA, inputB);auto getMatrixOp = [](const nvinfer1::ITensor& input "") {return (input.getDimensions().nbDims == 1) ? nvinfer1::MatrixOperation::kVECTOR: nvinfer1::MatrixOperation::kNONE;};nvinfer1::MatrixOperation opA = getMatrixOp(*inputA);nvinfer1::MatrixOperation opB = getMatrixOp(*inputB);nvinfer1::IMatrixMultiplyLayer* matmul = ctx->network()->addMatrixMultiply(*inputA, opA, *inputB, opB);return {{matmul->getOutput(0)}};}
好了回到问题,我们在ONNX-TensorRT的ModelImporter.cpp中的这个函数中
Status ModelImporter::importModel(::ONNX_NAMESPACE::ModelProto const& model, uint32_t weight_count, onnxTensorDescriptorV1 const* weight_descriptors)
加入这些代码:
//======= dump all nodes' output ============int node_size = graph.node_size();cout << "ModelImporter::importModel : graph.node_size() = " << node_size << " *******" << endl;for (int i = 0; i < graph.node_size(); i++) {::ONNX_NAMESPACE::NodeProto const& node = graph.node(i);if( node.output().size() > 0 ) {cout << "node[" << i << "] = "<< node.output(0) << ":"<< node.op_type() << endl;}}//=========================================
然后跑一遍onnx-tensorrt先观察看我们这个模型有多少个node节点以及名字,然后挑出我们感觉容易溢出的层把它们设为输出。
但是老潘太懒了,也不想猜哪个层有问题,于是干脆:
// 每隔10个node 设置该node为outputfor (int i = 0; i < graph.node_size(); i += 10){::ONNX_NAMESPACE::NodeProto const& node = graph.node(i);if( node.output().size() > 0) {nvinfer1::ITensor* new_output_tensor_ptr = &_importer_ctx.tensors().at(node.output(0)).tensor();new_output_tensor_ptr->setName(node.output(0).c_str());_importer_ctx.network()->markOutput(*new_output_tensor_ptr);}}
整个网络所有层,每隔10个node将其设置为输出,然后导出模型。
这样做相当于将标记markOutput的这些node作为输出,为了保证这个输出的正确性,TensorRT不会对这些标记的node做任何优化,也就是说原本会将这些node与前后其他node融合的优化也会被取消。
这个模型同样被标记为FP16格式,导出后发现大小比一开始的FP16要大一些。简单测试了一下,结果果然是对的,wocao~

据此判断,FP16结果不正确的原因可能是FP16精度前提下,TensorRT对某些层的优化导致网络节点计算中某一个地方突然爆炸溢出导致结果异常。
老潘逐步对层范围进行缩小(针对特定范围内的层做输出标记),定位出问题的node节点范围在第200-300中,导出了一个结果正确的模型,姑且将它称为debug_200_300.trt吧。
将问题层设置为FP32
即使定位到了问题op范围在200-300之间,但是我将这些200-300之间的node设为输出没有任何意义,虽然这个模型速度相比原生的FP16有所降低(但比FP32还是有所提升的),但因为这个模型输出节点很多(除了模型默认的输出节点我又加了10个),有些地方用起来不是很方便,或许也存在一些隐患(输出内容的拷贝)。
PS:老潘也不清楚TensorRT模型中一些输出节点不想要怎么办,
总之这是一个不优雅的办法,不能这么搞。
之前不是说FP32的模型没有问题嘛,而通过上述方法也确定了问题op的范围,那么我将这些范围内的问题op都换成FP32不就可以么?
说干就干,在onnx-tensorrt的main.cpp中填下以下代码,将200-500范围内的layer(这里的范围与之前不同,因为onnx的node转化为TensorRT的layer,并不是一一对应的),除了不能变FP32的,其余都强制设置精度为FP32。而除了200-500范围内网络中其余layer精度保持FP16不变。
int begin = 200;int end = 500;for(int i = begin; i < end; i ++){auto layer = trt_network->getLayer(i);std::string layerName = layer->getName();cout << "process " << layerName << endl;auto layer_type = layer->getType();auto layer_precision = layer->getPrecision();// 跳过一些固定的无法设置为fp16的层if(layer_type == nvinfer1::LayerType::kSHAPE || layer_type == nvinfer1::LayerType::kIDENTITY ||layer_type == nvinfer1::LayerType::kSHUFFLE || layer_type == nvinfer1::LayerType::kSLICE || layer_type == nvinfer1::LayerType::kCONCATENATION){continue;}if(layer_precision == nvinfer1::DataType::kINT32){continue;}if(layerName == "Tile"){continue;}// 将这个范围内所有op的精度手动设置为FP32layer->setPrecision(nvinfer1::DataType::kFLOAT);cout << "Set " << layerName << " to FP32 mode " << endl;}
如果想要再详细点去判断到底是哪个层的问题,可以通过根据layer类型依次设置是否转化为FP16来判断到底是哪个类型层的问题:
// 以下这些层设置为fp16if( layer_type == nvinfer1::LayerType::kCONVOLUTION || layer_type == nvinfer1::LayerType::kFULLY_CONNECTED ||layer_type == nvinfer1::LayerType::kMATRIX_MULTIPLY || layer_type == nvinfer1::LayerType::kELEMENTWISE){cout << "skip " << layerName << " to FP16 mode " << endl;continue;}
TensorRT中层类型示例:
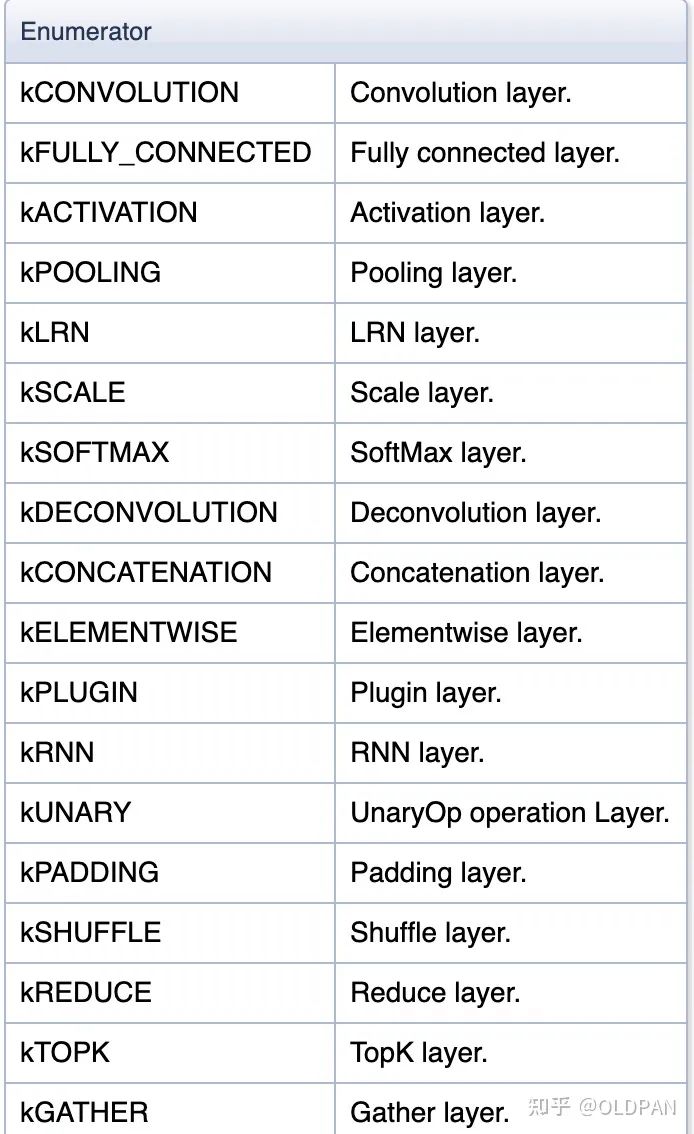
通过这个方式,老潘导出一个部分层FP32精度,其余层FP16,结果正确的模型,测了下QPS为800(相较1000Q差了些,仍然有优化空间)。这个模型理论上速度无限接近于全FP16模型,精度也无限接近于全FP32模型,就看怎么尝试了。
计算FP32和FP16结果的相似性
当我们尝试导出不同的FP16模型时,除了测试这个模型的速度,还需要判断导出的这个debug_fp16.trt是否符合精度要求,关于比较方式,这里参考:
OpenCV中Histogram Comparison的计算方式[2]
我们可以通过compare_layer函数,传入output_fp16和output_fp32的Tensor结果,这里我将Tensor结果通过flatten的方式打成一维的向量,两者长度是一样的,传入然后进行比较。
def compare_layer(output_fp16, output_fp32, metric=0, threshold=0.1):'''0: Euclidean Distance1: Cosine Similarity2: Relative Difference'''assert(len(output_fp16) == len(output_fp32))src1 = output_fp16src2 = output_fp32similarity = .0if metric == 0:# Euclidean distance and normlizationeuclidean = np.linalg.norm(src1 - src2)similarity = 1.0 / (1.0 + euclidean)elif metric == 1:# Cosine similarity and normalizationnum = np.dot(src1, src2)denom = np.linalg.norm(src1) * np.linalg.norm(src2)cos = num / denomsimilarity = 0.5 + 0.5 * coselif metric == 2:# Relative Differencesrc2_ = np.where(src2 == 0, np.finfo('f').resolution, src2)diff = np.absolute(src1 - src2_)rd = diff / np.absolute(src2_)similarity = float(rd[np.where(rd < threshold)].size) / rd.sizeelse:print("ERROR: Unkown metric for similarity analysis!")exit(-1)return "{:16.4f}%".format(similarity * 100), similarity*100
准备一批图片,然后挨个测试相似度统计一下即可。通过这种方式,挑选出一个FP16精度和速度trade-off的模型,也就是时间问题。
呼,长吐一口气。
后话
限于TensorRT的黑盒机制,虽然通过二分查找op层的方法找到了问题所在,但感觉这个解决方法还不是很完美。老潘在这里也抛砖引玉下,大家或许有更好的方法或者技巧可以解决这个问题,如果有的话及时留言交流~
本文提到的FP16错误属于隐式错误(转模型时候没有任何报错,但是执行的时候结果错误),也有一种直接在转模型的时候会遇到FP16权重范围越界的问题:
WARNING: onnx2trt_utils.cpp:198: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.setFp16ModeERROR: ../builder/cudnnBuilderWeightConverters.cpp (555) - Misc Error in operator(): 1 (Weights are outside of fp16 range. A possible fix is to retrain the model with regularization to bring the magnitude of the weights down.)ERROR: ../builder/cudnnBuilderWeightConverters.cpp (555) - Misc Error in operator(): 1 (Weights are outside of fp16 range. A possible fix is to retrain the model with regularization to bring the magnitude of the weights down.)
这种问题姑且称为显式错误吧,遇到这种问题,官方的建议是绕过这个op或者重新训练一个FP16权重版的模型。
其他方法
FP16精度错误的问题大部分与权重或者层输出值超出范围有关,鉴于此,想了想还有一些方法或许也可以避免类似的问题:
确定输入Tensor是否可以控制到一定范围(0-255或者0-1) 多加一些BN、GN类似于可以标注化数值范围的层 直接使用FP16精度训练模型
有时间可以尝试尝试。
相关issue问题:
https://github.com/NVIDIA/TensorRT/issues/420
https://github.com/NVIDIA/TensorRT/issues/380
部分代码参考了How2debug TensorRT:
https://elinux.org/TensorRT/How2Debug https://elinux.org/TensorRT/LayerDumpAndAnalyze https://elinux.org/TensorRT/LayerDumpAndAnalyzeForINT8
推荐阅读
2021-02-28

2021-01-25

2021-03-15
2021-01-10

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
