
(附代码)干货 | 几十行代码就能实现关键点检测
关键点检测有哪些运用?
判断姿态是否标准
比如健身软件,Keep就可以根据关键点信息,判断你健身时的姿态正确与否。体育运动同样可以实时跟踪你的姿态,如乒乓球等,可以帮你改善你的动作。
安全领域
如摔倒检测,摔倒检测这一个任务有实际意义有价值吗?那肯定是十分有用的,老人摔倒这一问题,就是老年人的最大杀手之一。
袁隆平院士也是今年在三亚摔了一跤,身体开始变差。我在读研期间,就被分配到了一个摔倒检测的任务。场景是运用在电梯口。当检测到摔倒之后,需要立马救援。因为老年人如果摔倒之后,不采取立刻救援,极易发生二次摔倒伤害。
那么怎么判断摔倒呢?当时我调研了一些方案,最终采用的是基于关键点检测的方案来做。
表盘,人脸等关键点信息的识别
表盘与人脸上等具有明显关键点信息的任务,可以将关键点定位,再提取其特征,再使用相对应的特征来进行计算。与设备之间进行交互
未来,使用手势来作为交互手段,会是一大趋势~ 我说的!

关键点检测简单原理介绍
在我实际任务中,我用的最好的关键点检测算法是哪一个呢?登登登登~ 我愿称之为!
为啥是它呢?结构如下图,就是很简单,在数据量比较少的情况下,收敛快,并且精度也够用,网络还小!反正,很好用就对了!
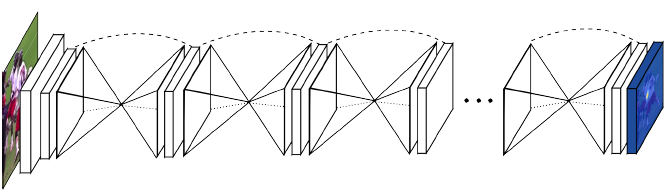
上图是论文提出的网络模型,叫做堆叠漏斗神经网络。这个网络架构形态就像它的名字的一样,是由一个个的漏斗状的神经网络级联起来,每一个漏斗神经网络就像编码器和解码器合成,负责提取特征和生成热图结果。整个网络使用了大量的卷积/反卷积层,池化/反池化层,以及全连接层。网络的输入是一张或者的标准大小尺寸图片(×),输出是该张图片缩小到一定尺寸的各个节点的热图(×)。如我们需要检测20个关键点,那我们在模型的输出特征维度就是,再与标签计算损失进行训练。
聊聊我之前做的摔倒检测的任务
对于关键点检测而言,目前主要的做法分为两种,一种是top-down,一种是bottom-up。我当时采用的就是top-down方案,即先使用检测,将行人拿出来放到关键点检测的网络中去。而bottom-up的做法,是先把图像中的所有关键点给检测到,再给连起来。
目前从我的实战角度而言,top-down更适合,主要是的做法在行人检测阶段能够获取较高的召回,故而相对来说会有比较高的精度;
先简单看下我当时的效果,因为公众号GIF大小要求,所以压缩的有点奇怪~

我当时主要采用的方案为与,这两个网络我们会在面经的时候,着重介绍的。欢迎各位持续关注哦~
判断摔倒主要的逻辑是借鉴了一位同学的毕业设计。主要只表示计算上半身与下半身在图像中的长度,进行计算相对应的比例,该比例相当于一个超参数,低于该参数,视为摔倒。该同学是用的来获取的关键点,再使用关键点来进行判断逻辑的。
其中长这样:

它可以得到深度图信息,同时可以得到最多个人的个关键点。而深度学习的技术,就可以弥补这些硬件的弱势,使用一个不错的摄像头,就可以达到一个较好的效果了。

MediaPipe
今天推荐一个非常吊的库叫做, 官方网站放在了参考链接中。
先看下对于的评价: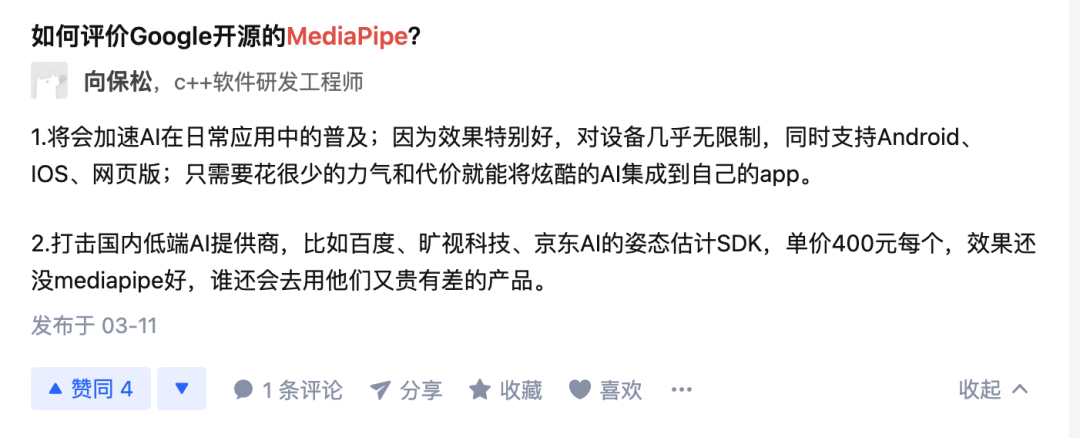
这里也简单介绍下:
是机器视觉开源框架;它具有如下优势:
多种功能支持:同时支持姿态估计、手势识别、脸部识别、目标检测等机器视觉主流应用模型;
2)跨平台支持:同时支持windows、linux、Android、IOS四大主流平台,连web识别都支持;
3)精度和性能好:总结来说就是又快又准!
4)节省数十万云服务器年费,充分利用用户手机计算资源;避免网络延迟降低识别实时性;现有开源功能满足业务场景需求
同样,的劣势为:无法在小程序中实现识别功能;需要单独开发APP,Android、IOS需要分别开发,研发团队技术栈不匹配APP开发;需要用户单独下载APP,需要更多运营成本。
具体支持哪些功能呢?看下图:
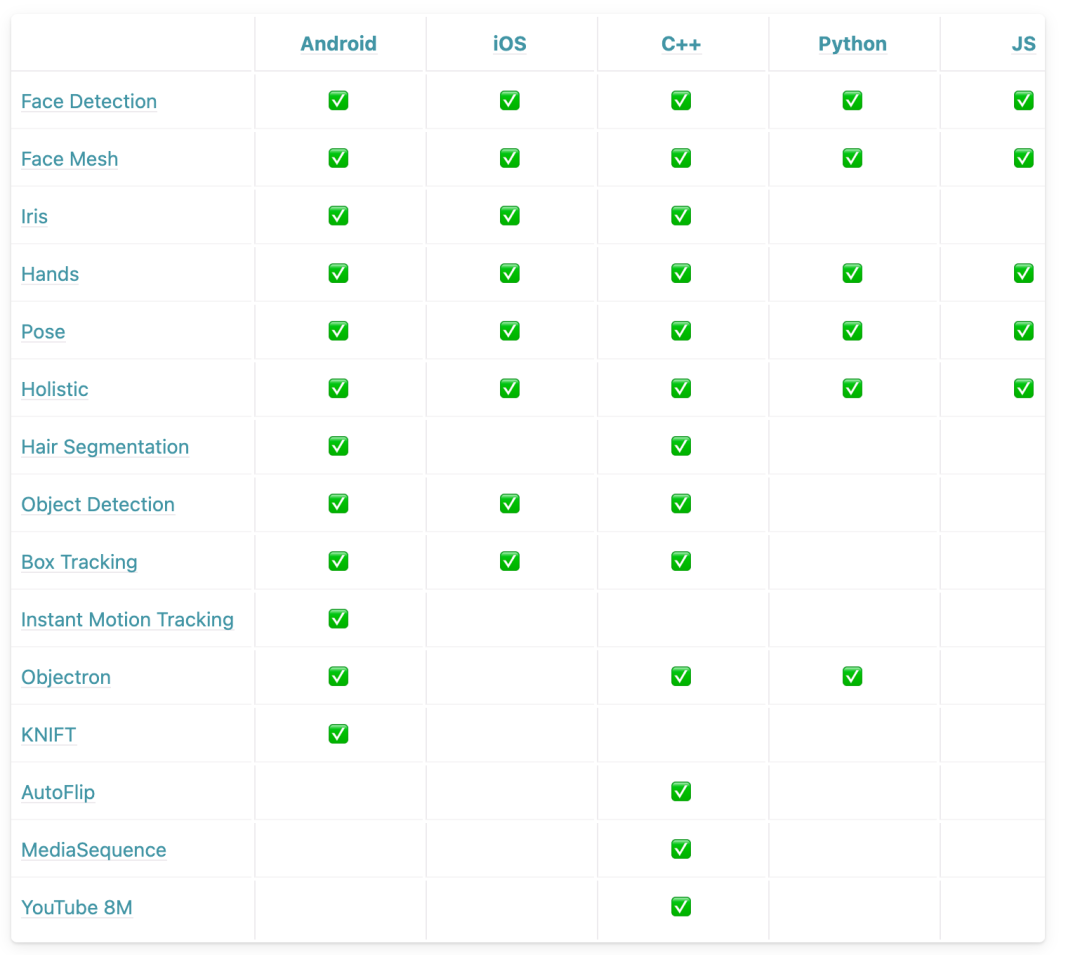
而我在这里,使用来做一个手势关键点检测,各位可以看下效果如何。
代码如下所示:
import cv2
import mediapipe as mp
import time
class handDetector():
def __init__(self, mode=False, maxHands=2, detectionCon=0.5, trackCon=0.5):
self.mode = mode
self.maxHands = maxHands
self.detectionCon = detectionCon
self.trackCon = trackCon
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxHands,
self.detectionCon, self.trackCon)
self.mpDraw = mp.solutions.drawing_utils
def findHands(self, img, draw=True):
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.results = self.hands.process(imgRGB)
# print(results.multi_hand_landmarks)
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms,
self.mpHands.HAND_CONNECTIONS)
return img
def findPosition(self, img, handNo=0, draw=True):
lmList = []
if self.results.multi_hand_landmarks:
myHand = self.results.multi_hand_landmarks[handNo]
for id, lm in enumerate(myHand.landmark):
# print(id, lm)
h, w, c = img.shape
cx, cy = int(lm.x * w), int(lm.y * h)
# print(id, cx, cy)
lmList.append([id, cx, cy])
if draw:
cv2.circle(img, (cx, cy), 1, (255, 0, 255), cv2.FILLED)
return lmList
def main():
pTime = 0
cap = cv2.VideoCapture('./finger_dancer.mp4')
detector = handDetector()
wid = int(cap.get(3))
hei = int(cap.get(4))
size = (wid, hei)
fps = 30
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
out = cv2.VideoWriter()
out.open(r"./out.mp4",
fourcc, fps, size)
while True:
success, img = cap.read()
img = detector.findHands(img)
lmList = detector.findPosition(img)
if len(lmList) != 0:
print(lmList[4])
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 1,
(255, 0, 255), 3)
cv2.imshow("Image", img)
out.write(img)
cv2.waitKey(1)
if __name__ == "__main__":
main()
引用
https://www.zhihu.com/question/401635800/answer/1774116555 https://zhuanlan.zhihu.com/p/357158418 https://google.github.io/mediapipe/
✄------------------------------------------------
双一流大学研究生团队创建,一个专注于目标检测与深度学习的组织,希望可以将分享变成一种习惯。
整理不易,点赞三连!