
基于深度学习的计算机视觉,应用于无人驾驶的视觉感知系统中,主要分为四大块:
主要从需求、难点、实现三个方面对每项感知部分做剖析。上述检测的难度从难到易排序:DOD>FS=LD>SOD。
检测需求:对车辆(轿车、卡车、电动车、自行车)、行人等动态物体的识别;检测难点:(三座大山:检测类别多、多目标追踪难度大、测距精度足够准)(1)遮挡情况情况较多,heading朝向的问题,测距精准度(2)行人、车辆类型种类较多,难以覆盖,容易误检(集装箱vs卡车、树干vs行人)
实现方案:摄像头的内外参标定;对动态物体的检测,尤其是车辆的检测,是需要给出车辆的3D bounding box的(给出一个伪3D也是可以的),所以在神经网络的训练打标签时与普通的2D检测有区别,3D的好处在于能给出车的一个heading信息,以及车的高度信息。车辆及行人都要给出对应的id号,要加入多目标跟踪算法,遮挡情况下的id难以维持,这是一个难点。另外神经网络提取特征能力再强大,也不能cover掉所有的动态物体检测,可以依据现实场景增加一些几何约束条件(如汽车的长宽比例固定,卡车的长宽比例固定,车辆的距离不可能突变,行人的高度有限等),增加几何约束的好处是提高检测率,降低误检率,如轿车不可能误检为卡车;方案是训练一个3D检测模型(2.5D也行)加后端多目标追踪优化加基于单目视觉几何的测距方法。对于动态物体的检测,最后需要结合激光雷达的结果进行融合,在夜间、雨雪天气,视觉无法处理;同时,有激光雷达信息,对于车辆的朝向信息判断更准确,仅凭一个摄像头去做检测、去做heading、去做精准的距离判断,难度太大。 结合激光雷达,夜晚能准确给出车辆的heading信息检测需求:对车辆行驶的安全边界(可行驶区域)进行划分,主要对车辆、普通路边沿、侧石边沿、没有障碍物可见的边界、未知边界进行划分。(1)复杂环境场景时,边界形状复杂多样,导致泛化难度较大。不同于其它的检测有明确的检测类型(如车辆、行人、交通灯),通行空间需要把本车的行驶安全区域划分出来,需要对凡是影响本车前行的障碍物边界全部划分出来,如平常不常见的水马、锥桶、坑洼路面、非水泥路面、绿化带、花砖型路面边界、十字路口、T字路口等进行划分。(2)标定参数校正;在车辆加减速、路面颠簸、上下坡道时,会导致相机俯仰角发生变化,原有的相机标定参数不再准确,投影到世界坐标系后会出现较大的测距误差,通行空间边界会出现收缩或开放的问题。(3)边界点的取点策略和后处理;通行空间考虑更多的是边缘处,所以边缘处的毛刺,抖动需要进行滤波处理,使边缘处更平滑。障碍物侧面边界点易被错误投影到世界坐标系,导致前车隔壁可通行的车道被认定为不可通行区域,如下图所示。
结合激光雷达,夜晚能准确给出车辆的heading信息检测需求:对车辆行驶的安全边界(可行驶区域)进行划分,主要对车辆、普通路边沿、侧石边沿、没有障碍物可见的边界、未知边界进行划分。(1)复杂环境场景时,边界形状复杂多样,导致泛化难度较大。不同于其它的检测有明确的检测类型(如车辆、行人、交通灯),通行空间需要把本车的行驶安全区域划分出来,需要对凡是影响本车前行的障碍物边界全部划分出来,如平常不常见的水马、锥桶、坑洼路面、非水泥路面、绿化带、花砖型路面边界、十字路口、T字路口等进行划分。(2)标定参数校正;在车辆加减速、路面颠簸、上下坡道时,会导致相机俯仰角发生变化,原有的相机标定参数不再准确,投影到世界坐标系后会出现较大的测距误差,通行空间边界会出现收缩或开放的问题。(3)边界点的取点策略和后处理;通行空间考虑更多的是边缘处,所以边缘处的毛刺,抖动需要进行滤波处理,使边缘处更平滑。障碍物侧面边界点易被错误投影到世界坐标系,导致前车隔壁可通行的车道被认定为不可通行区域,如下图所示。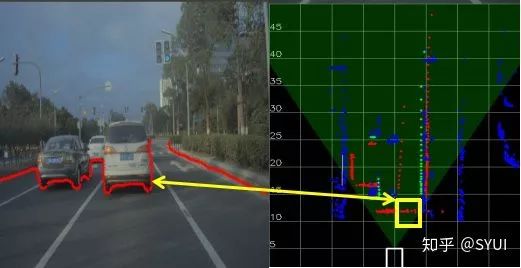 实现方案:摄像头标定(若能在线标定最好,精度可能会打折扣),若不能实现实时在线标定功能,增加读取车辆的IMU信息,利用车辆IMU信息获得的俯仰角自适应地调整标定参数;选取轻量级合适的语义分割网络,对需要分割的类别打标签,场景覆盖尽可能的广;描点操作(极坐标的取点方式),边缘点平滑后处理操作(滤波算法)。
实现方案:摄像头标定(若能在线标定最好,精度可能会打折扣),若不能实现实时在线标定功能,增加读取车辆的IMU信息,利用车辆IMU信息获得的俯仰角自适应地调整标定参数;选取轻量级合适的语义分割网络,对需要分割的类别打标签,场景覆盖尽可能的广;描点操作(极坐标的取点方式),边缘点平滑后处理操作(滤波算法)。
检测需求:对各类车道线(单侧/双侧车道线、实线、虚线、双线)进行检测,还包括线型的颜色(白色/黄色/蓝色)以及特殊的车道线(汇流线、减速线等)的检测。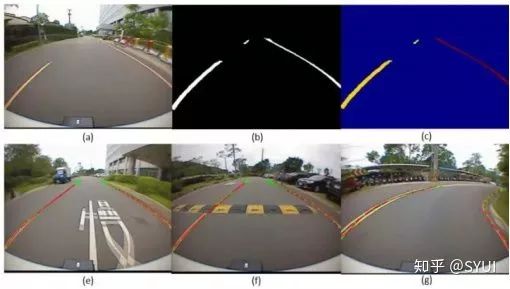 标准单一情况下的车道线识别难度不大,路况大都是平行笔直的实线或虚线(如特斯拉支持高速公路的辅助驾驶,它们的车道线检测拟合的效果极好)。车道线的检测难点在于:(1)线型种类多,不规则路面检测车道线难度大;如遇地面积水、无效标识、修补路面、阴影情况下的车道线容易误检、漏检。(2)上下坡、颠簸路面,车辆启停时,容易拟合出梯形、倒梯形的车道线。(3)弯曲的车道线、远端的车道线、环岛的车道线,车道线的拟合难度较大,检测结果易闪烁;实现方案:传统的图像处理算法需经过摄像头的畸变校正,对每帧图片做透视变换,将相机拍摄的照片转到鸟瞰图视角,再通过特征算子或颜色空间来提取车道线的特征点,使用直方图、滑动窗口来做车道线曲线的拟合,传统算法最大的弊端在于场景的适应性不好。采用神经网络的方法进行车道线的检测跟通行空间检测类似,选取合适的轻量级网络,打好标签;车道线的难点在于车道线的拟合(三次方程、四次方程),所以在后处理上可以结合车辆信息(速度、加速度、转向)和传感器信息做航位推算,尽可能的使车道线拟合结果更佳。Tesla Model3 Autopilot渲染在HMI界面的车道线结果(极其稳定,极其鲁棒)
标准单一情况下的车道线识别难度不大,路况大都是平行笔直的实线或虚线(如特斯拉支持高速公路的辅助驾驶,它们的车道线检测拟合的效果极好)。车道线的检测难点在于:(1)线型种类多,不规则路面检测车道线难度大;如遇地面积水、无效标识、修补路面、阴影情况下的车道线容易误检、漏检。(2)上下坡、颠簸路面,车辆启停时,容易拟合出梯形、倒梯形的车道线。(3)弯曲的车道线、远端的车道线、环岛的车道线,车道线的拟合难度较大,检测结果易闪烁;实现方案:传统的图像处理算法需经过摄像头的畸变校正,对每帧图片做透视变换,将相机拍摄的照片转到鸟瞰图视角,再通过特征算子或颜色空间来提取车道线的特征点,使用直方图、滑动窗口来做车道线曲线的拟合,传统算法最大的弊端在于场景的适应性不好。采用神经网络的方法进行车道线的检测跟通行空间检测类似,选取合适的轻量级网络,打好标签;车道线的难点在于车道线的拟合(三次方程、四次方程),所以在后处理上可以结合车辆信息(速度、加速度、转向)和传感器信息做航位推算,尽可能的使车道线拟合结果更佳。Tesla Model3 Autopilot渲染在HMI界面的车道线结果(极其稳定,极其鲁棒)
静态物体检测:
检测需求:对交通红绿灯、交通标志等静态物体的检测识别;检测难点:(1)红绿灯、交通标识属于小物体检测,在图像中所占的像素比极少,尤其远距离的路口,识别难度更大。如下图红绿灯在1920*1208的像素层面上占据的像素大小仅为18*45pixel左右,在强光照的情况下,人眼都难以辨别,而停在路口的斑马线前的汽车,需要对红绿灯进行正确的识别才能做下一步的判断。 (2)交通标识种类众多;采集到的数据易出现数量不均匀的情况。
(2)交通标识种类众多;采集到的数据易出现数量不均匀的情况。 (3)交通灯易受光照的影响,在不同光照条件下颜色难以区分(红灯与黄灯),且到夜晚时,红灯与路灯、商店的灯颜色相近,易造成误检;实现方案:通过感知去识别红绿灯,有一种舍身取义的感觉,效果一般,适应性差,条件允许的话(如固定园区限定场景),该装V2X就装V2X,多个备份冗余,V2X > 高精度地图 > 感知识别。若碰上GPS信号弱的时候,感知识别可以出场了,大部分情况,V2X足以Cover掉大部分的场景。感知方案的具体实现参照文章,主要为红绿灯数据集采集,标签处理,检测模型训练,算法部署,追踪后端优化,接口开发;(1)真值的来源。定义,校准,分析比对,绝不是看检测结果的map或帧率,需要以激光的数据或者RTK的数据作为真值来验证测距结果在不同工况(白天、雨天、遮挡等情况下)的准确性;(2)硬件帧率、资源消耗。多个网络共存,多个相机共用都是要消耗cpu、gpu资源的,如何处理好这些网络的分配,多个网络的前向推理可能共用一些卷积层,能否复用;引入线程、进程的思想来处理各个模块,更高效的处理协调各个功能块;在多相机读取这一块,做到多目输入的同时不损失帧率,在相机码流的编解码上做些工作。(3)多目融合的问题。一般在汽车上会配备4个(前、后、左、右)四个相机,对于同一物体从汽车的后方移动到前方,即后视摄像头可以看到,再移至侧视相机能看到,最后移至前视相机能看到,在这个过程中,物体的id应保持不变(同一个物体,不因相机观测的变化而改变)、距离信息跳变不宜过大(切换到不同相机,给出的距离偏差不宜太大,)(4)多场景的定义。针对不同的感知模块,需要对数据集即场景定义做明确的划分,这样在做算法验证的时候针对性更强;如对于动态物体检测,可以划分车辆静止时的检测场景和车辆运动时的场景。对于交通灯的检测,可以进一步细分为左转红绿灯场景、直行红绿灯、掉头红绿灯等特定场景。公用数据集与专有数据集的验证。(5)回放工具验证,感知输出的离线数据分析。肉眼观察视觉感知的效果是不可靠的,需要将视觉检测的结果,激光的结果,RTK的结果都统一在回放工具上,对视觉检测的结果进行离线分析,包括距离误差的分析、检测效果与距离的分析、曲线拟合的分析等等,完成这些工作需要统一时间戳,同时输出视觉检测结果的类别信息,距离信息和作为真值传感器的输出信息,进行分析对比,以此验证视觉感知结果的好坏。上述为视觉感知中的具体实现模块功能。目前围绕无人驾驶汽车做基于深度学习开发的独角兽企业:momenta(提供基于深度学习的计算视觉解决方案,自主泊车)地平线(基于深度学习的芯片硬件设计,提供整套软硬件方案)
(3)交通灯易受光照的影响,在不同光照条件下颜色难以区分(红灯与黄灯),且到夜晚时,红灯与路灯、商店的灯颜色相近,易造成误检;实现方案:通过感知去识别红绿灯,有一种舍身取义的感觉,效果一般,适应性差,条件允许的话(如固定园区限定场景),该装V2X就装V2X,多个备份冗余,V2X > 高精度地图 > 感知识别。若碰上GPS信号弱的时候,感知识别可以出场了,大部分情况,V2X足以Cover掉大部分的场景。感知方案的具体实现参照文章,主要为红绿灯数据集采集,标签处理,检测模型训练,算法部署,追踪后端优化,接口开发;(1)真值的来源。定义,校准,分析比对,绝不是看检测结果的map或帧率,需要以激光的数据或者RTK的数据作为真值来验证测距结果在不同工况(白天、雨天、遮挡等情况下)的准确性;(2)硬件帧率、资源消耗。多个网络共存,多个相机共用都是要消耗cpu、gpu资源的,如何处理好这些网络的分配,多个网络的前向推理可能共用一些卷积层,能否复用;引入线程、进程的思想来处理各个模块,更高效的处理协调各个功能块;在多相机读取这一块,做到多目输入的同时不损失帧率,在相机码流的编解码上做些工作。(3)多目融合的问题。一般在汽车上会配备4个(前、后、左、右)四个相机,对于同一物体从汽车的后方移动到前方,即后视摄像头可以看到,再移至侧视相机能看到,最后移至前视相机能看到,在这个过程中,物体的id应保持不变(同一个物体,不因相机观测的变化而改变)、距离信息跳变不宜过大(切换到不同相机,给出的距离偏差不宜太大,)(4)多场景的定义。针对不同的感知模块,需要对数据集即场景定义做明确的划分,这样在做算法验证的时候针对性更强;如对于动态物体检测,可以划分车辆静止时的检测场景和车辆运动时的场景。对于交通灯的检测,可以进一步细分为左转红绿灯场景、直行红绿灯、掉头红绿灯等特定场景。公用数据集与专有数据集的验证。(5)回放工具验证,感知输出的离线数据分析。肉眼观察视觉感知的效果是不可靠的,需要将视觉检测的结果,激光的结果,RTK的结果都统一在回放工具上,对视觉检测的结果进行离线分析,包括距离误差的分析、检测效果与距离的分析、曲线拟合的分析等等,完成这些工作需要统一时间戳,同时输出视觉检测结果的类别信息,距离信息和作为真值传感器的输出信息,进行分析对比,以此验证视觉感知结果的好坏。上述为视觉感知中的具体实现模块功能。目前围绕无人驾驶汽车做基于深度学习开发的独角兽企业:momenta(提供基于深度学习的计算视觉解决方案,自主泊车)地平线(基于深度学习的芯片硬件设计,提供整套软硬件方案)





