
一份数学小白也能读懂的「马尔可夫链蒙特卡洛方法」入门指南
↓↓↓点击关注,回复资料,10个G的惊喜
选自Medium 作者:Ben Shaver 机器之心编译 参与:黄小天、刘晓坤
在众多经典的贝叶斯方法中,马尔可夫链蒙特卡洛(MCMC)由于包含大量数学知识,且计算量很大,而显得格外特别。本文反其道而行之,试图通过通俗易懂且不包含数学语言的方法,帮助读者对 MCMC 有一个直观的理解,使得毫无数学基础的人搞明白 MCMC。
在我们中的很多人看来,贝叶斯统计学家不是巫术师,就是完全主观的胡说八道者。在贝叶斯经典方法中,马尔可夫链蒙特卡洛(Markov chain Monte Carlo/MCMC)尤其神秘,其中数学很多,计算量很大,但其背后原理与数据科学有诸多相似之处,并可阐释清楚,使得毫无数学基础的人搞明白 MCMC。这正是本文的目标。
那么,到底什么是 MCMC 方法?一言以蔽之:
MCMC 通过在概率空间中随机采样以近似兴趣参数(parameter of interest)的后验分布。
我将在本文中做出简短明了的解释,并且不借助任何数学知识。
首先,解释重要的术语。「兴趣参数」(parameter of interest)可以总结我们感兴趣现象的一些数字。我们通常使用统计学评估参数,比如,如果想要了解成年人的身高,我们的兴趣参数可以是精确到英寸的平均身高。「分布」是参数的每个可能值、以及我们有多大可能观察每个参数的数学表征,其最著名的实例是钟形曲线:
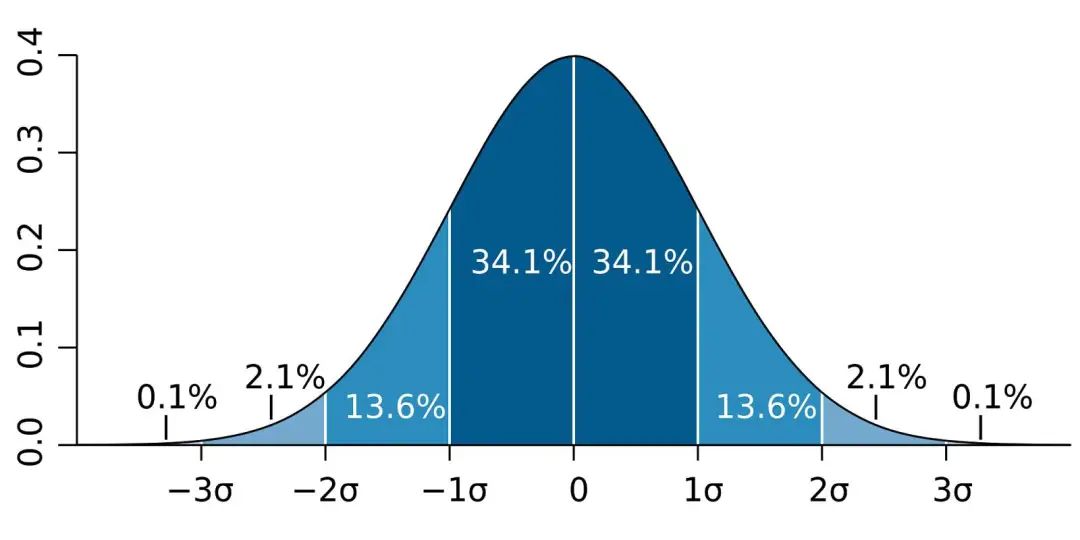
在贝叶斯统计学中,分布还有另外一种解释。贝叶斯不是仅仅表征一个参数值以及每个参数有多大可能是真值,而是把分布看作是我们对参数的「信念」。因此,钟形曲线表明我们非常确定参数值相当接近于零,但是我们认为在一定程度上真值高于或低于该值的可能性是相等的。
事实上,人的身高确实遵从一个正态曲线,因此我们假定平均身高的真值符合钟形曲线,如下所示:
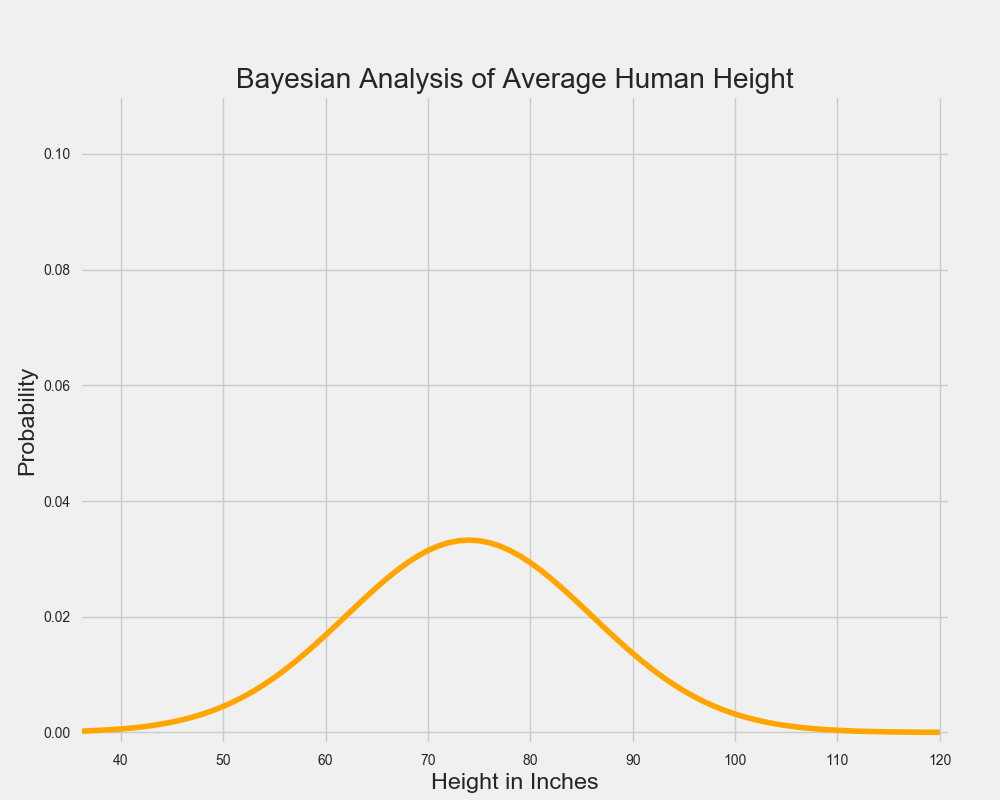
很明显,上图表征是巨人的身高分布,因为据图可知,最有可能的平均身高是 6'2"(但他们也并非超级自信)。
让我们假设其中某个人后来收集到一些数据,并且观察了身高在 5"和 6"之间的一些人。我们可以用另一条正态曲线表征下面的数据,该曲线表明了哪些平均身高值能最好地解释这些数据:
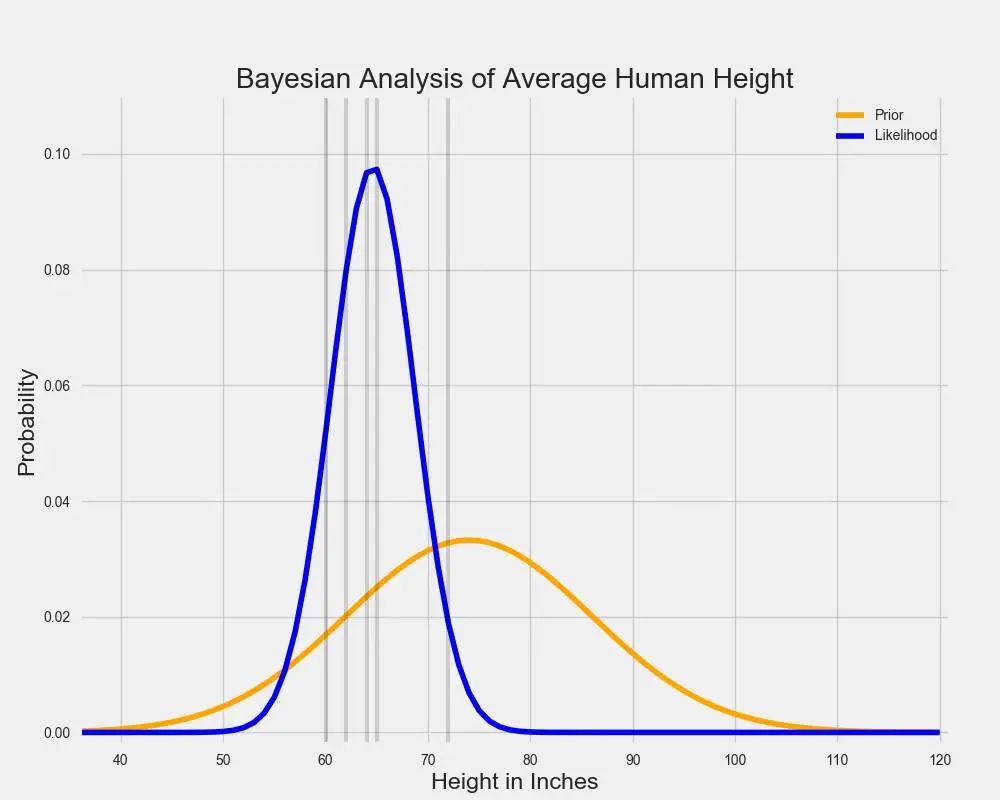
在贝叶斯统计中,表征我们对参数信念的分布被称为「先验分布」,因为它在我们看到任何数据之前捕捉到了我们的信念。「可能性分布」(likelihood distribution)通过表征一系列参数值以及伴随的每个参数值解释观察数据的可能性,以总结数据之中的信息。评估最大化可能性分布的参数值只是回答这一问题:什么参数值会使我们更可能观察到已经观察过的数据?如果没有先验信念,我们可能无法对此作出评估。
但是,贝叶斯分析的关键是结合先验与可能性分布以确定后验分布。它可以告诉我们哪个参数值最大化了观察到已观察过的特定数据的概率,并把先验信念考虑在内。在我们的实例中,后验分布如下所示:
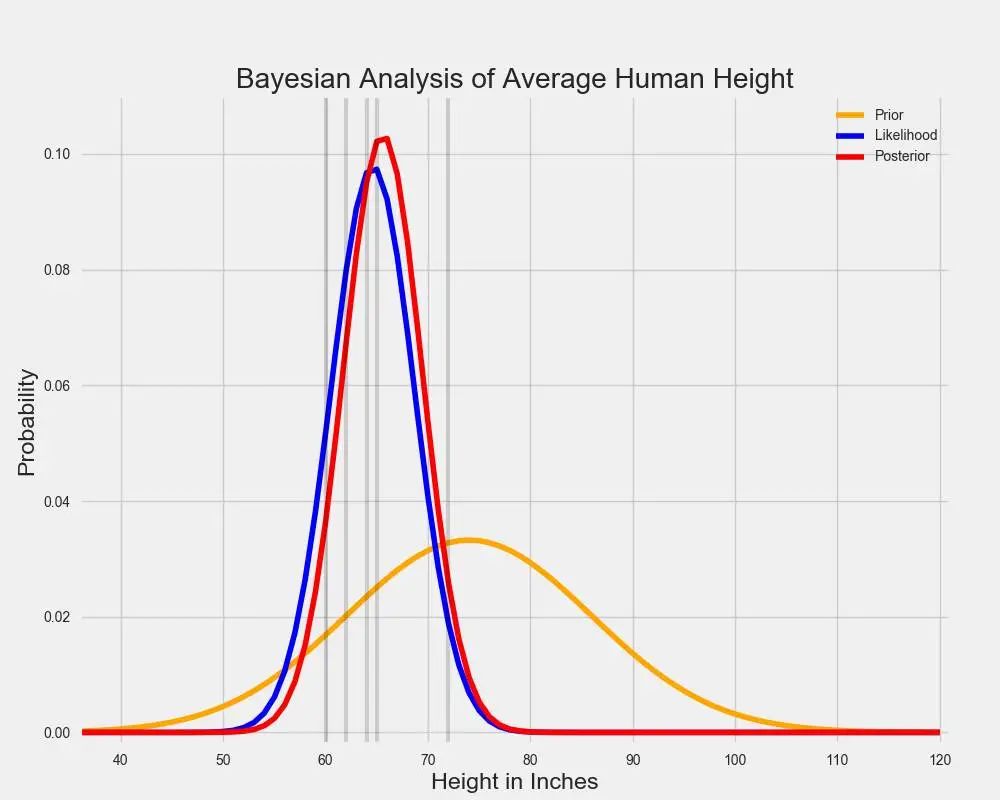
如上所示,红线表征后验分布。你可以将其看作先验和可能性分布的一种平均值。由于先验分布较小且更加分散,它表征了一组关于平均身高真值的「不太确定」的信念。同时,可能性分布在相对较窄的范围内总结数据,因此它表征了对真参数值的「更确定」的猜测。
当先验与可能性分布结合在一起,数据(由可能性分布表征)主导了假定存在于这些巨人之中的个体的先验弱信念。尽管该个体依然认为平均身高比数据告诉他的稍高一些,但是他非常可能被数据说服。
在两条钟形曲线的情况下,求解后验分布非常容易。有一个结合了两者的简单等式。但是如果我们的先验和可能性分布表现很差呢?有时使用非简化的形状建模数据或先验信念时是最精确的。如果可能性分布需要带有两个峰值的分布才能得到最好地表征呢?并且出于某些原因我们想要解释一些非常奇怪的先验分布?通过手动绘制一个丑陋的先验分布,我已可视化了该情景,如下所示:
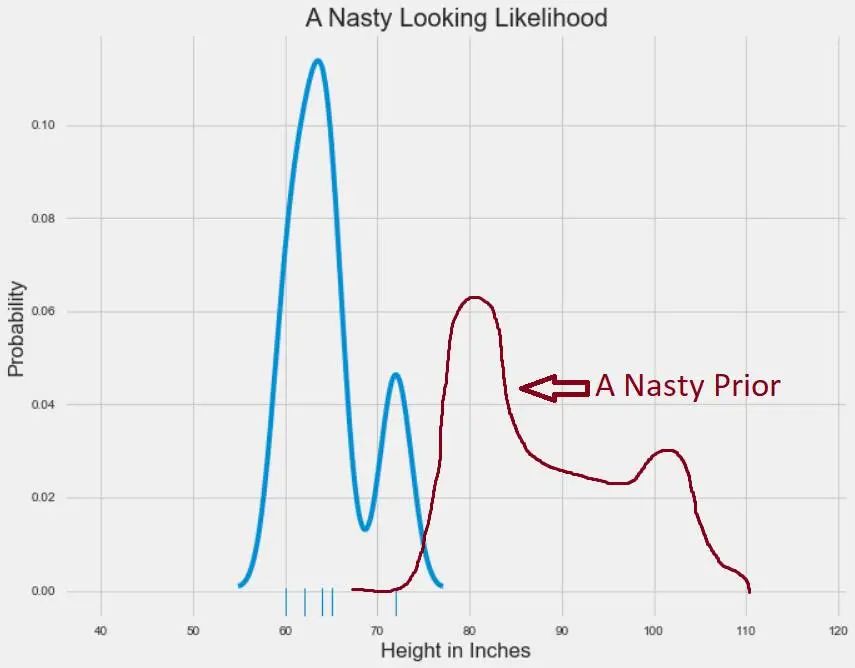
可视化由 Matplotlib 渲染,并使用 MS Paint 做了改善
如前所述,存在一些后验分布,它给出了每个参数值的可能性分布。但是很难得到完整的分布,也无法解析地求解。这就是使用 MCMC 方法的时候了。
MCMC 允许我们在无法直接计算的情况下评估后验分布的形状。为了理解其工作原理,我将首先介绍蒙特卡洛模拟(Monte Carlo simulation),接着讨论马尔可夫链。
蒙特卡洛模拟只是一种通过不断地生成随机数来评估固定参数的方法。通过生成随机数并对其做一些计算,蒙特卡洛模拟给出了一个参数的近似值(其中直接计算是不可能的或者计算量过大)。
假设我们想评估下图中的圆圈面积:
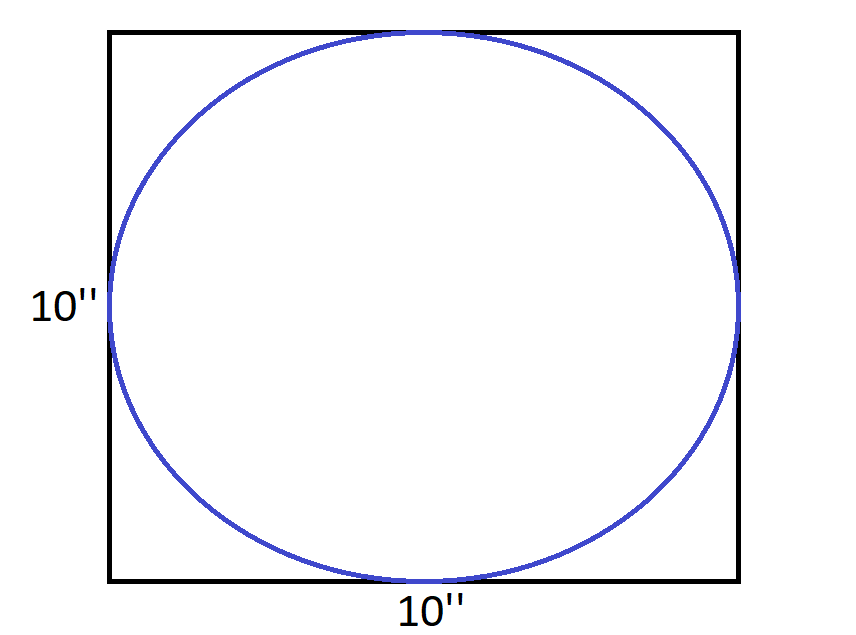
由于圆在边长为 10 英寸的正方形之内,所以通过简单计算可知其面积为 78.5 平方英寸。但是,如果我们随机地在正方形之内放置 20 个点,接着我们计算点落在圆内的比例,并乘以正方形的面积,所得结果非常近似于圆圈面积。
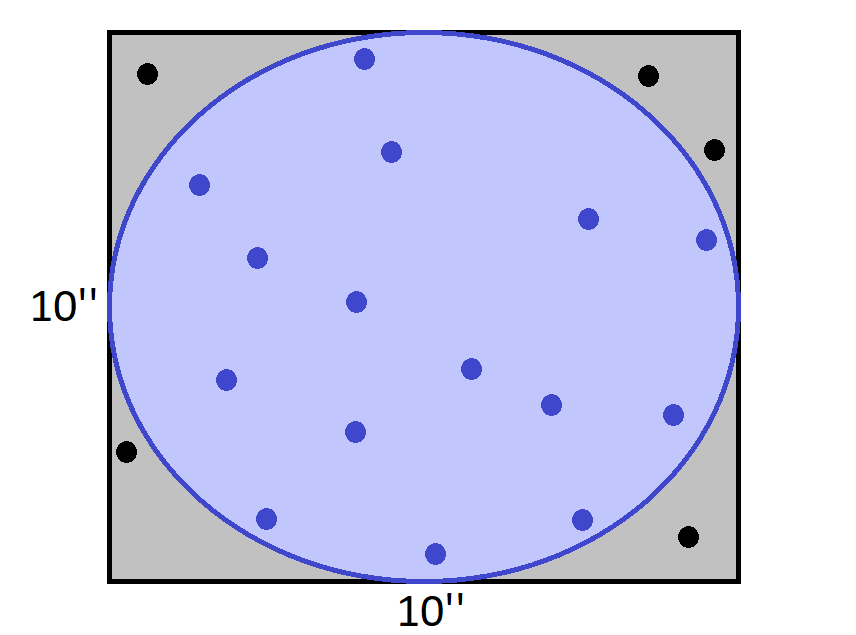
由于 15 个点落在了圆内,那么圆的面积可以近似地为 75 平方英寸,对于只有 20 个随机点的蒙特卡洛模拟来说,结果并不差。
现在,假设我们想要计算下图中由蝙蝠侠方程(Batman Equation)绘制的图形的面积:
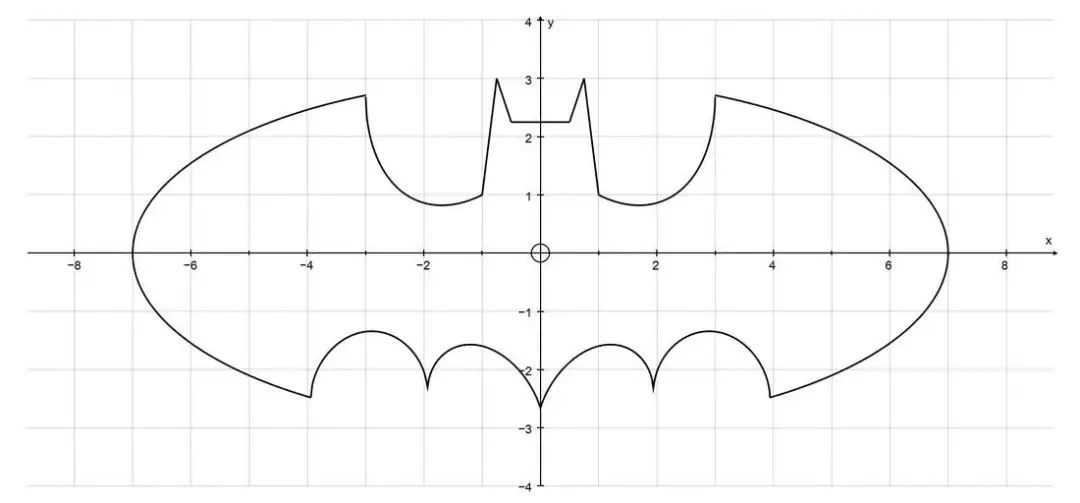
我们从来没有学过一个方程可以求这样的面积。不管怎样,通过随机地放入随机点,蒙特卡洛模拟可以相当容易地为该面积提供一个近似值。
蒙特卡洛模拟不只用于估算复杂形状的面积。通过生成大量随机数字,它还可用于建模非常复杂的过程。实际上,蒙特卡洛模拟还可以预测天气,或者评估选举获胜的概率。
理解 MCMC 方法的第二个要素是马尔科夫链(Markov chains)。马尔科夫链由存在概率相关性的事件的序列构成。每个事件源于一个结果集合,根据一个固定的概率集合,每个结果决定了下一个将出现的结果。
马尔科夫链的一个重要特征是「无记忆性」:可能需要用于预测下一个时间的一切都已经包含在当前的状态中,从事件的历史中得不到任何新信息。例如 Chutes and Ladders 这个游戏就展示了这种无记忆性,或者说马尔科夫性,但在现实世界中很少事物是这种性质的。尽管如此,马尔科夫链也是理解现实世界的强大工具。
在十九世纪,人们观察到钟形曲线在自然中是一种很常见的模式。(我们注意到,例如,人类的身高服从钟形曲线分布。)Galton Boards 曾通过将弹珠坠落并通过布满木钉的板模拟了重复随机事件的平均值,在弹珠的最终数量分布中重现了钟形曲线:
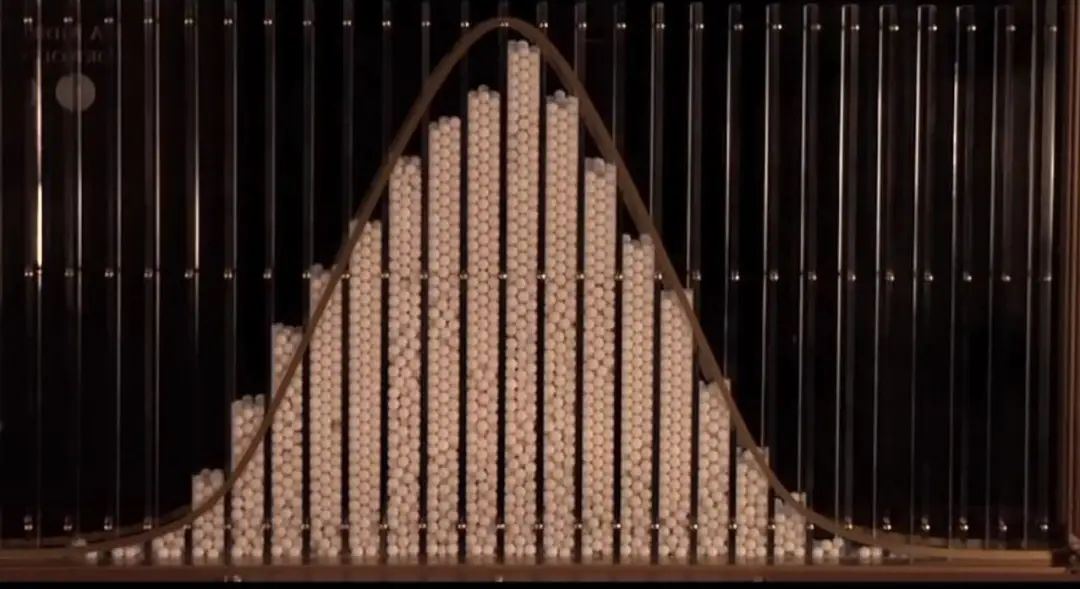
俄罗斯数学家和神学家 Pavel Nekrasov 认为钟形曲线,或者更一般的说,大数规律只不过是小孩子的游戏和普通的谜题中的伪假象,其中每个事件之间都是完全独立的。他认为现实世界中的互相依赖的事件,例如人类行为,并不遵循漂亮的数学模式或分布。
Andrey Markov(马尔科夫链正是以他的名字命名)试图证明非独立的事件可能也遵循特定的模式。他的其中一个最著名的例子是从一份俄罗斯诗歌作品中数出几千个两字符对(two-character pairs)。他使用这些两字符对计算了每个字符的条件概率。即,给定一个确定的上述字母或空白,关于下一个字母将是 A、T 或者空白等,存在一个确定的概率。通过这些概率,Markov 可以模拟一个任意的长字符序列。这就是马尔科夫链。虽然早先的几个字符很大程度上依赖于初始字符的选择,Markov 表明在长字符序列中,字符的分布会出现特定的模式。因此,即使是互相依赖的事件,如果服从固定的概率分布,将遵循平均水平的模式。
举一个更有意义的例子,假设你住在一个有 5 个房间的房子里,里面有一个卧室、浴室、客厅、厨房、饭厅。然后我们收集一些数据,假定只需要当前你所处的房间和相应的时间就可以预测下一个你所处的房间的概率。例如,如果你在厨房,你有 30% 的概率会留在厨房,有 30% 的概率会走到饭厅,有 20% 的概率会走到客厅,有 10% 的概率会走到浴室,以及有 10% 的概率会走到卧室。使用每个房间的概率集合,我们可以构建一个关于你接下来要去的房间的预测链。
如果想预测一个人处于厨房之后所在的房间,基于几个状态而做出预测可能有效。但由于我们的预测仅仅基于一个人在房子中的单次观察,可以合理地认为预测结果是不够好的。例如,如果一个人从卧室走到浴室,相比从厨房走到浴室的情况,他更可能会返回原来的房间。因此,马尔科夫链并不真正适用于现实世界。
然而,通过迭代运行马尔科夫链数千次,确实能给出关于你接下来可能所处的房间的长期预测。更重要的是,这个预测并不受这个人起始所处的房间的影响。对此可以直观地理解为:在模拟和描述长期过程(或普遍情况)一个人所处房间的概率时,时间因素是不重要的。因此,如果我们理解了控制行为的概率,就可以使用马尔科夫链计算变化的长期趋势。
希望通过介绍一些蒙特卡洛模拟和马尔科夫链,可以使你对 MCMC 方法的零数学解释有更直观的理解。
回到原来的问题,即评估平均身高的后验分布:
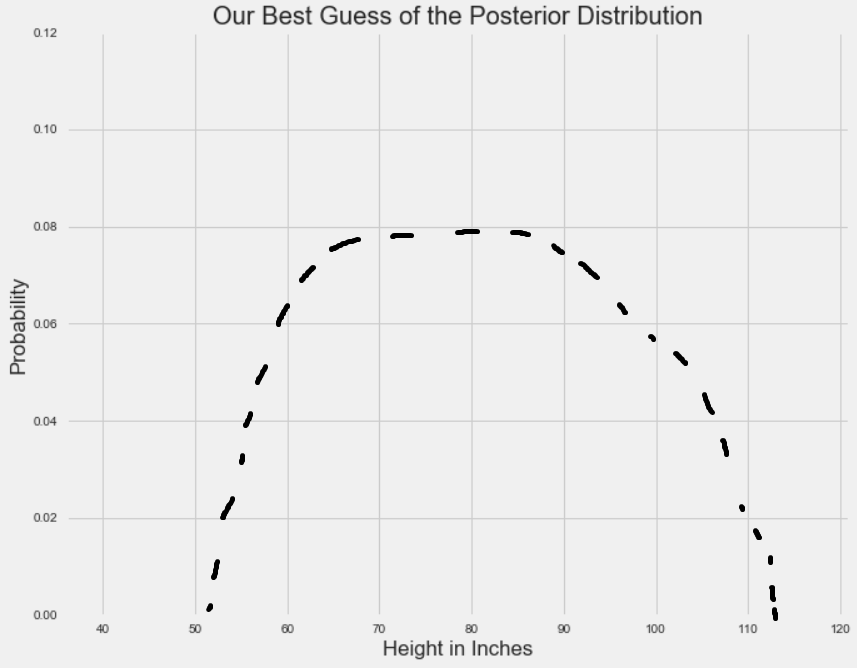
这个平均身高的后验分布的实例没有基于真实数据。
我们知道后验分布在某种程度上处于先验分布和可能性分布的范围内,但无论如何都无法直接计算。使用 MCMC 方法,我们可以有效地从后验分布中提取样本,然后计算统计特征,例如提取样本的平均值。
首先,MCMC 方法选择一个随机参数值。模拟过程中会持续生成随机的值(即蒙特卡洛部分),但服从某些能生成更好参数值的规则。即对于一对参数值,可以通过给定先验信度计算每个值解释数据的有效性,从而确定哪个值更好。我们会将更好的参数值以及由这个值的解释数据有效性决定的特定概率添加到参数值的链中(即马尔科夫链部分)。
为了可视化地解释上述过程,首先强调一下,一个分布的特定值的高度代表的是观察到该值的概率。因此,参数值(x 轴)对应的概率(y 轴)可能或高或低。对于单个参数,MCMC 方法会从随机在 x 轴上采样开始。
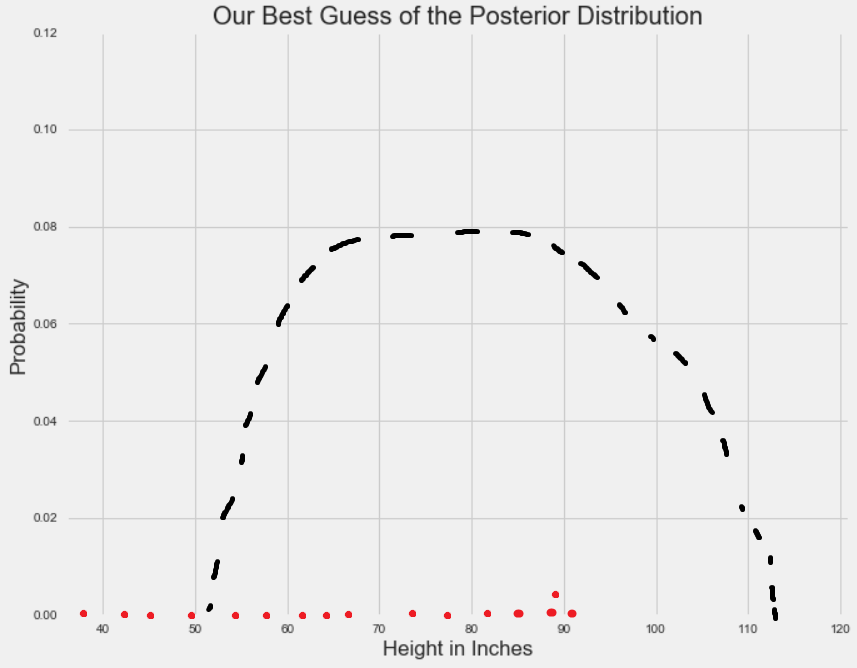
红点表征随机参数采样。
由于随机采样服从固定的概率,它们倾向于经过一段时间后收敛于参数的高概率区域:
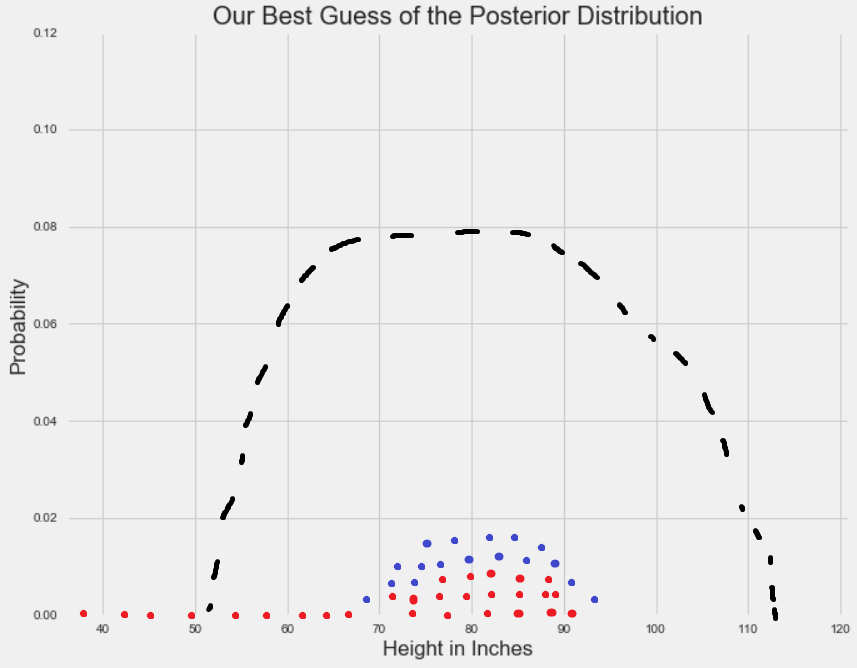
蓝点表示当采样收敛之后,经过任意时间的随机采样。注意:垂直堆叠这些点仅仅是为了说明目的。
收敛出现之后,MCMC 采样会得到作为后验分布样本的一系列点。用这些点画直方图,然后你可以计算任何感兴趣的统计特征:
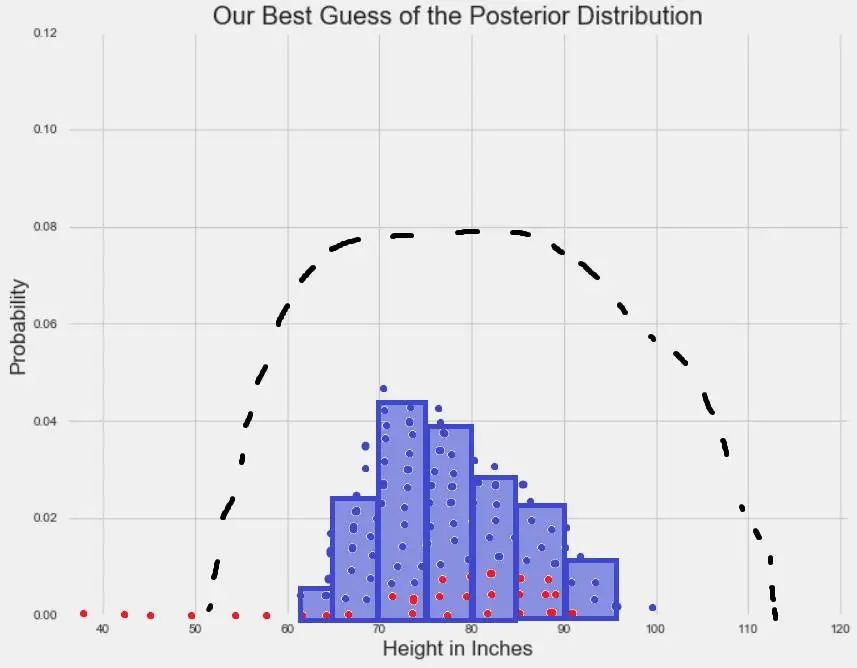
通过 MCMC 模拟生成的样本集合计算的任何统计特征,都是对真实后验分布的统计特征的最佳近似。
MCMC 方法也可以用于评估多于一个参数的后验分布(例如,人类身高和体重)。对于 n 个参数,在 n 维空间中存在高概率的区域,其中特定的参数值集合可以更有效地解释数据。因此,我认为 MCMC 方法的本质,就是在一个概率空间中进行随机采样以近似后验分布。
原文链接:https://towardsdatascience.com/a-zero-math-introduction-to-markov-chain-monte-carlo-methods-dcba889e0c50
推荐阅读
用Python学线性代数:自动拟合数据分布 Python 用一行代码搞事情,机器学习通吃 Github 上最大的开源算法库,还能学机器学习! JupyterLab 这插件太强了,Excel灵魂附体 终于把 jupyter notebook 玩明白了 一个超好用的 Python 标准库,666 几百本编程中文书籍(含Python)持续更新
好文点个在看吧!