
【NLP】FedNLP: 首个联邦学习赋能NLP的开源框架,NLP迈向分布式新时代
文 | 阿毅
两周前,南加大Yuchen Lin(PhD student @USC and ex-research intern @GoogleAI)所在的团队在Twitter官宣开源首个以研究为导向的联邦学习赋能NLP的FedNLP框架。发布数小时内就获得了647个赞,163次转发,可见其热度。我相信大家也是满脑子疑问:什么是联邦学习?为什么将联邦学习与NLP结合呢?那么本篇推文就来给大家讲解一下联邦学习与NLP这两个看似没有关系的研究领域为何可以携手共赴未来新时代。
论文题目:FedNLP: A Research Platform for Federated Learning in Natural Language Processing
论文链接:
https://yuchenlin.xyz/files/fednlp.pdf
框架链接
https://github.com/FedML-AI/FedNLP
为了促进NLP中的联邦学习研究,本文开源了以研究为导向的FedNLP框架,该框架旨在以联邦学习为基础在NLP中研究数据隐私保护的研究平台。具体来说,FedNLP支持NLP中各种流行的任务,例如文本分类,序列标记,对话系统,seq2seq生成和语言建模。该框架还实现了Transformer语言模型(例如BERT)和FL方法(例如FedAvg,FedOpt等)之间的接口,以进行语言模型的分布式训练。本文使用FedNLP进行的初步实验表明,在分布式和集中式数据集上学习的性能之间存在很大的性能差距,这就意味着开发适合NLP任务的FL方法是有趣且令人兴奋的未来研究方向。
 动机概述
动机概述
许多现实部署的NLP应用程序高度依赖于用户本地数据,例如,文本消息、文档及其标签,问题和选定的答案等,这些数据可能存储于个人设备上,也可以存储于组织的更大数据孤岛中。根据许多数据隐私法规,这些本地数据通常被认为是高度隐私的,因此任何人都不能直接访问,而这使得很难训练一种高性能模型以使用户受益。联邦学习(Federated Learning, FL)[1] 作为谷歌2017年提出的一种新兴的隐私保护的分布式机器学习系统通过允许用户(即个人设备或组织,如手机设备或者医院)将其数据保留在本地并与云服务器协作地学习一个共享的全局模型来保护用户的数据隐私,从而为社区提供一种新颖而有前途的研究方向:FL + NLP。简单来说,FL应用到NLP领域中是为了开发一些隐私保护、个性化的语言模型。
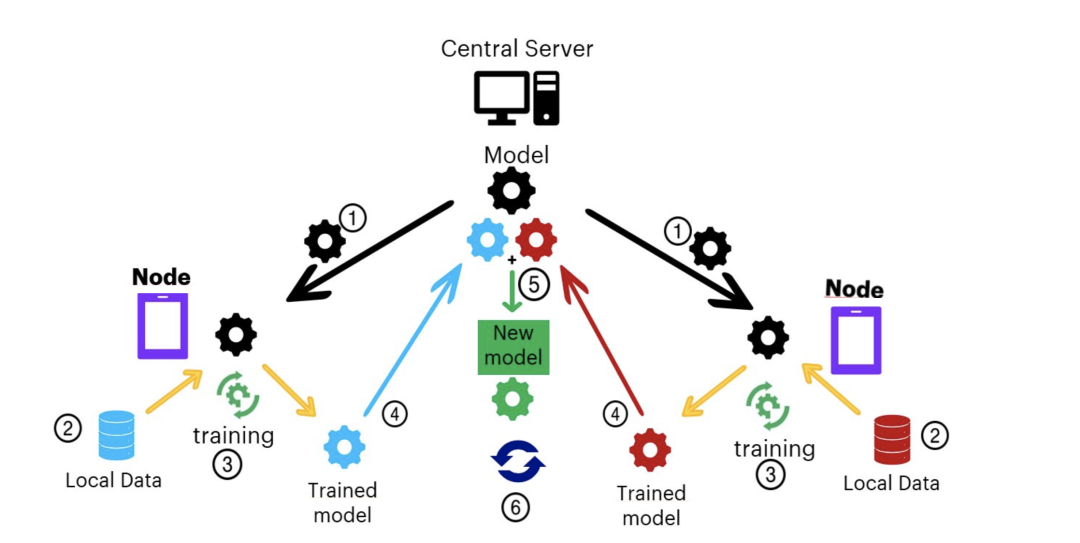
再讲二者如何结合之前,小编先简单介绍一下FL系统:如下图所示,FL系统由一个服务器和个客户端组成,其中每个客户端持有一个本地数据集。FL系统的训练步骤分为三个阶段:初始化、本地训练、更新聚合,具体总结如下:
阶段1,初始化
所有参与本轮训练的客户端发送信息给云服务器以表示登记参与联邦学习训练,云服务器去除存在网络故障或者网络不佳的客户端。然后云服务器将从所有参与的客户端中随机抽取一定比例(0<q<1)的客户端参加本轮训练,并将预训练(或者初始化)的全局模型发送给相应的客户端。
阶段2,本地训练
每个客户端收到全局模型作为自己的本地模型(local model)。然后,客户端开始使用自己的本地数据集进行训练,其中数据集的大小为,由训练数据集即输入-输出对组成,因此本地训练需要优化的损失函数定义如下:
其中,是指模型的参数,是指本地损失函数(例如).
阶段3,更新聚合
在联邦学习中,更新聚合是指云服务器对客户端上传的模型更新进行聚合操作,常见的聚合规则有FedAvg、FedProx等。客户端进行本地训练之后将自己的本地模型更新上传给云服务器,云服务器对收到的本地模型更新执行聚合操作得到新的全局模型,其定义如下:
以上过程重复执行,直到全局模型收敛结束训练,因此联邦学习系统实际上就是一个变型的分布式机器学习训练框架,其目的是使得用户数据不上传、不分享。
对于联邦学习感兴趣的读者,可以阅读以下两篇非常经典的综述:
[2] Kairouz P, McMahan H B, Avent B, et al. Advances and open problems in federated learning[J]. arXiv preprint arXiv:1912.04977, 2019.
[3] Yang Q, Liu Y, Chen T, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10(2): 1-19.
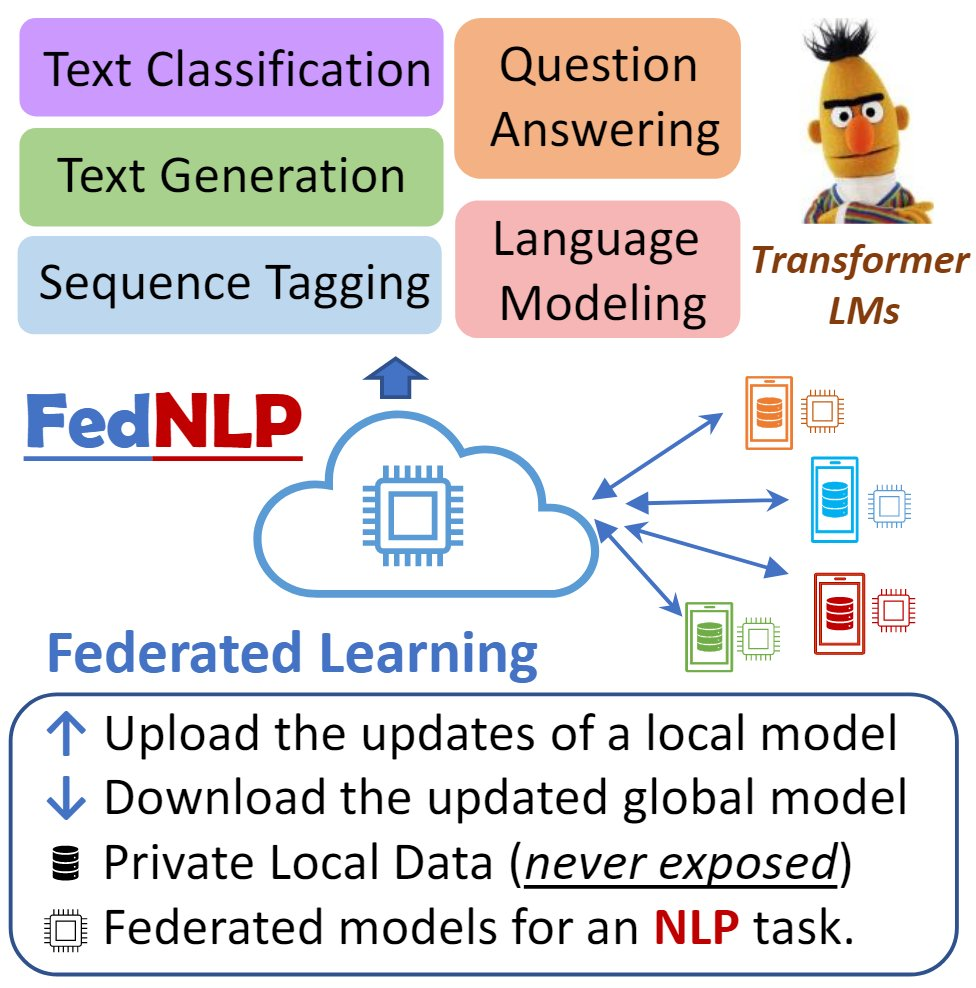
挑战
如下图所示,FL的隐私保护特性可以很好地为语言模型训练服务,那么两者结合存在哪些技术挑战呢?其实,挑战在主要是以下四个:
目前,该研究方向因缺乏提供基本构件的标准化平台而受阻:基准数据集、NLP模型、FL方法、评估方式等。当前大多数FL平台,它们要么专注于统一各种FL方法,要么使用计算机视觉模型和数据集进行实验,却缺乏将预先训练的语言模型、最流行的NLP和各种任务公式的实际NLP应用联系起来的能力。 开发用于FL + NLP的全面通用平台的第二个挑战是处理具有不同输入和输出格式的实际NLP应用程序的各种任务表述。 由于客户端上的non-IID数据分部是FL系统的主要特征,因此如何为现有NLP数据集模拟实际的non-IID分布也是一个挑战。 最后,一个平台还需要将各种FL方法与基于Transformer的NLP模型集成以用于各种任务类型,因此需要一个灵活且可扩展的学习框架。特别是,现在需要对Transformers的常规训练器组件进行修改,以实现针对通信高效和安全的联邦学习框架。
那么针对以上框架,南加大团队是如何应当的呢?且看下章详解:
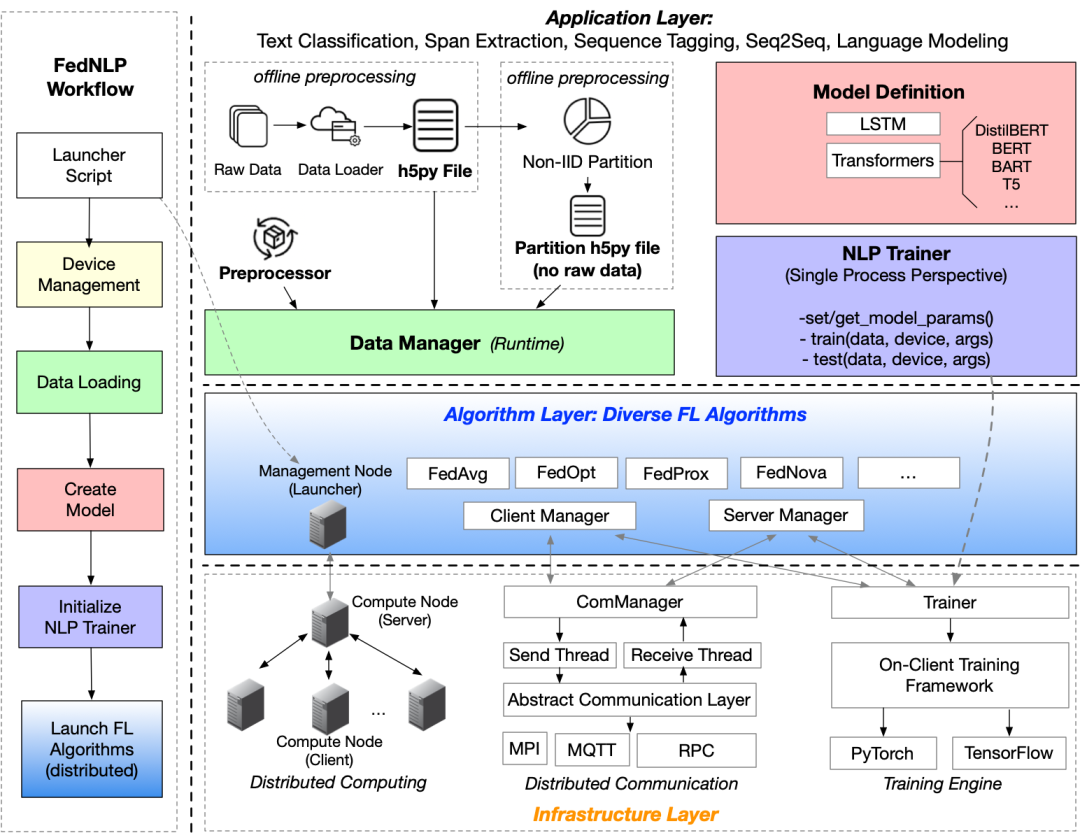
框架概述
FedNLP平台由三层组成:应用程序层、算法层和基础架构层。在应用程序层,FedNLP提供了三个模块:数据管理,模型定义和用于所有任务格式的单进程训练器;在算法层,FedNLP支持各种FL算法。在基础架构层,FedNLP旨在将单过程训练器与用于FL的分布式学习系统集成在一起 具体来说,我们使每个层和模块履行其职责,并具有高度的模块化。
应用层 数据管理。在数据管理中,DataManager要做的是控制从加载数据到返回训练函数的整个工作流程。具体来说,DataManager设置为读取h5py数据文件并驱动预处理器以将原始数据转换为特征。根据任务定义,有四种类型的DataManager。用户可以通过继承DataManager类之一,指定数据操作函数并嵌入特定的预处理器来自定义自己的DataManager。 模型定义。框架支持两种类型的模型:Transformer和LSTM。对于Transformer模型,为了与现有的NLP生态对接,框架与HuggingFace Transformers库兼容,因此可以直接重用各种类型的Transformer,而无需重新实现。 NLP训练器(单进程角度)。对于特定于任务的NLP训练器,最突出的功能是它不需要用户具有分布式计算的任何背景,即FedNLP的用户只需完成单进程代码编写。 算法层 每个算法包括两个核心对象ServerManager和ClientManager,它们集成了基础结构层的通信模块ComManager和训练引擎的Trainer,以完成分布式算法协议(如FedAvg、FedProx、FedOPT等)和分布式训练。请注意,用户可以通过将自定义的Trainer传递给算法API来自定义Trainer。 基础架构层 用户可以编写分布式脚本来管理GPU资源分配。特别是,FedNLP提供了GPU分配API),以将特定的GPU分配给不同的FL客户端。 算法层可以使用统一抽象的ComManager来完成复杂的算法通信协议。当前,我们支持MPI(消息传递接口),RPC(远程过程调用)和MQTT(消息队列遥测传输)通信后端。MPI满足单个集群中的分布式训练需求;RPC可以满足跨数据中心的通信需求(例如,跨孤岛联邦学习);MQTT可以满足智能手机或物联网设备的通信需求。 训练引擎,该训练引擎通过作为Trainer类重用现有的深度学习训练引擎。该模块的当前版本基于PyTorch,但它可以轻松支持TensorFlow等框架。将来,我们可能会考虑在此级别上支持通过编译器技术优化的轻量级边缘训练引擎。
仿真结果
该团队对FedNLP平台进行了初步分析,并在一些常见设置中进行了实验。请注意,这些初步实验的目的是展示FedNLP平台的功能,同时保留有关未来工作的最新性能开发。
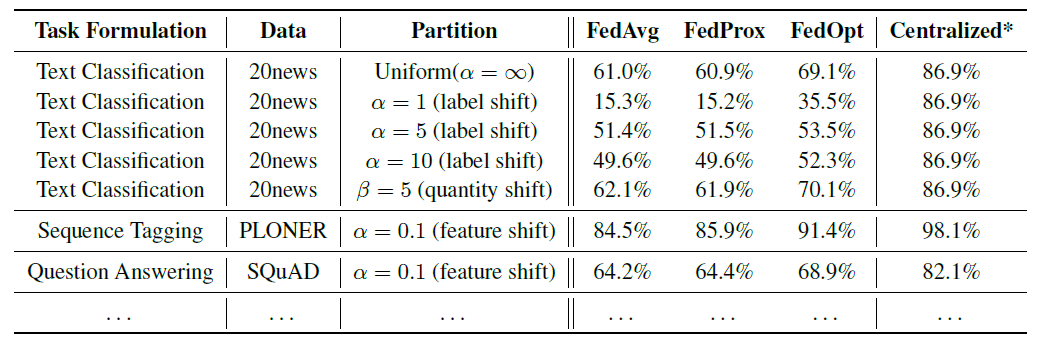
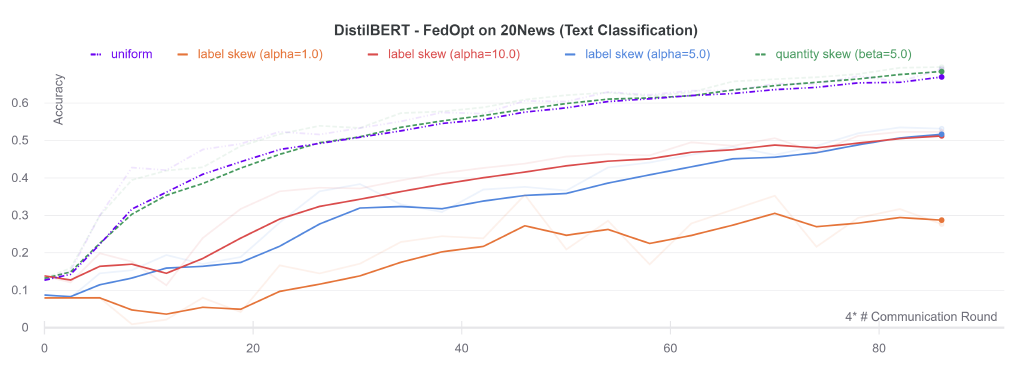
数据异构程度与准确性的关系
从下图所知,在文本分类任务上,越小(意味着non-IID程度越严重),框架的性能越差(保持同样的FL方法),这说明non-IID问题仍然是FL的瓶颈问题。其次,对于不同的non-IID,例如label shift和quantity shift,两者的性能差异也是很大的。通过这个实验,该平台已经为大家提供了两种不同的non-IID设置,以及该设置下的baseline,因此大家可以设计一些解决NLP领域中non-IID问题的FL方法。
FL方法与准确率的关系
该团队在保持non-IID程度一致的情况下,在不同任务上对不同的FL方法的性能进行了比较。实验结果显示,FedOpt的性能是三者中最佳的,这也为大家提供该任务上解决non-IID问题初步baseline。但是大家也发现,就算是FedOpt离集中式的方法的性能还是差很多的,说明还有存在很多的提升空间。
应用举例
对于FL + NLP来说,目前落地最多的就是基于FL的键盘下一字预测,如:
[4] Hard A, Rao K, Mathews R, et al. Federated learning for mobile keyboard prediction[J]. arXiv preprint arXiv:1811.03604, 2018.
[5] Yang T, Andrew G, Eichner H, et al. Applied federated learning: Improving google keyboard query suggestions[J]. arXiv preprint arXiv:1812.02903, 2018.
[6] Ramaswamy S, Mathews R, Rao K, et al. Federated learning for emoji prediction in a mobile keyboard[J]. arXiv preprint arXiv:1906.04329, 2019.
FL方法还可以用来训练高质量的语言模型,该模型可以胜过未经联邦学习而训练的模型,如:
[7] Shaoxiong Ji, Shirui Pan, Guodong Long, Xue Li, Jing Jiang, and Zi Huang. 2019. Learning private neural language modeling with attentive aggregation. 2019 International Joint Conference on Neural Networks (IJCNN), pages 1–8.
[8] Mingqing Chen, Ananda Theertha Suresh, Rajiv Mathews, Adeline Wong, Cyril Allauzen, Françoise Beaufays, and Michael Riley. 2019. Federated learning of n-gram language models. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), pages 121–130, Hong Kong, China. Association for Computational Linguistics.
除了这些应用之外,在医学关系提取和医学名称实体识别也有相关工作:
[9] Suyu Ge, Fangzhao Wu, Chuhan Wu, Tao Qi, Yongfeng Huang, and X. Xie. 2020. Fedner: Privacy-preserving medical named entity recognition with federated learning. ArXiv, abs/2003.09288.
[10] Dianbo Sui, Yubo Chen, Jun Zhao, Yantao Jia, Yuantao Xie, and Weijian Sun. 2020. FedED: Federated learning via ensemble distillation for medical relation extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2118–2128, Online. Association for Computational Linguistics.
总结
基于上述开源框架已有的工作我们可以从FL和NLP两个角度切入来做一些未来的工作:
NLP 开发一些基于FL的新型应用和模型,例如在医疗领域、翻译领域等 如何将大型语言模型与FL训练结合 如何量化语言模型隐私泄露的可能性 FL 如何设计新的FL方法来解决NLP中的non-IID问题 如何设计新的FL训练协议以完美匹配NLP领域的特性 如何设计新的边缘训练方法来提高应对大型语言模型需要大量通信的能力 如何提高现有FL隐私保护的能力,例如在NLP领域防御后门攻击、中毒攻击等
萌屋作者:阿毅
[1] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial Intelligence and Statistics. PMLR, 2017: 1273-1282.
[2] Kairouz P, McMahan H B, Avent B, et al. Advances and open problems in federated learning[J]. arXiv preprint arXiv:1912.04977, 2019.
[3] Yang Q, Liu Y, Chen T, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10(2): 1-19.
[4] Hard A, Rao K, Mathews R, et al. Federated learning for mobile keyboard prediction[J]. arXiv preprint arXiv:1811.03604, 2018.
[5] Yang T, Andrew G, Eichner H, et al. Applied federated learning: Improving google keyboard query suggestions[J]. arXiv preprint arXiv:1812.02903, 2018.
[6] Ramaswamy S, Mathews R, Rao K, et al. Federated learning for emoji prediction in a mobile keyboard[J]. arXiv preprint arXiv:1906.04329, 2019.
[7] Shaoxiong Ji, Shirui Pan, Guodong Long, Xue Li, Jing Jiang, and Zi Huang. 2019. Learning private neural language modeling with attentive aggregation. 2019 International Joint Conference on Neural Networks (IJCNN), pages 1–8.
[8] Mingqing Chen, Ananda Theertha Suresh, Rajiv Mathews, Adeline Wong, Cyril Allauzen, Françoise Beaufays, and Michael Riley. 2019. Federated learning of n-gram language models. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), pages 121–130, Hong Kong, China. Association for Computational Linguistics.
[9] Suyu Ge, Fangzhao Wu, Chuhan Wu, Tao Qi, Yongfeng Huang, and X. Xie. 2020. Fedner: Privacy-preserving medical named entity recognition with federated learning. ArXiv, abs/2003.09288.
[10] Dianbo Sui, Yubo Chen, Jun Zhao, Yantao Jia, Yuantao Xie, and Weijian Sun. 2020. FedED: Federated learning via ensemble distillation for medical relation extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2118–2128, Online. Association for Computational Linguistics.
往期精彩回顾
本站qq群851320808,加入微信群请扫码:
