
细说物体检测中的Anchors
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

极市导读
本文运用一系列设问,清楚地解释了物体检测工作中anchors的概念及其意义。
今天,我将讨论在物体检测器中引入的一个优雅的概念 —— Anchors,它是如何帮助检测图像中的物体,以及它们与传统的两阶段检测器中的Anchor有何不同。
像往常一样,让我们看看在哪些问题中,anchors被引入作为解决方案。
在开始使用anchors之前,让我们看看两阶段物体检测器是如何工作的,以及它们实际上是如何促进单阶段检测器的发展的。
两阶段物体检测器:传统的两阶段物体检测器检测图像中的物体分两阶段进行:
1、第一阶段:第一阶段遍历输入图像和物体可能出现的输出区域(称为建议区域或感兴趣的区域)。这个过程可以通过外部算法(例如:selective search)或者神经网络来完成。
2、第二阶段:第二阶段是一个神经网络,它接受这些感兴趣的区域,并将其分类到一个目标物体类中。
为了简单起见,我会介绍一个著名的两级探测器 —— Faster-RCNN。两个阶段都包含了一个神经网络。
1、第一个神经网络预测一个物体可能出现的位置(也称为objectness得分)。它基本上就是一个对前景(物体)和背景的分类。这个网络被称为区域建议网络,又名RPN。
2、提取区域建议后,对输入图像中对应的位置进行裁剪,送入下一个神经网络进行分类,假设有N个目标类。这个网络预测在那个位置上存在什么物体。
步骤2看起来非常简单,因为它可以归结为图像分类,即将目标物体分成N个类别中的一个。
让我们深入研究第1步。
(a)这个神经网络如何预测这些目标的位置?
(b) 如果可以训练神经网络进行前景和背景的分类,那么为什么不训练它一次预测所有N个类呢?
(a) 的解决方案就是anchors,(b)的答案是肯定的,我们可以用一个单一的网络来执行N-way目标检测,这样的网络就是众所周知的单阶段目标检测器。单阶段检测器与Faster-RCNN中第一个阶段的网络几乎相同。
我说SSD和RPN几乎是一样的,因为它们在概念上是相同的,但是在体系结构上有不同。
神经网络如何检测图像中的物体?
解决方案(1) —— 单目标检测:让我们使用最简单的情况,在一个图像中找到一个单一的物体。给定一个图像,神经网络必须输出物体的类以及它的边界框在图像中的坐标。所以网络必须输出4+C个数字,其中C是类别的数量。
可以直接将输入图像通过一组卷积层然后将最后的卷积输出转换为一个4+C维的向量,其中,前4个数字表示物体的位置(比如minx, miny, maxx, maxy),后面的C个数字表示类别概率的得分。
解决方案(2) —— 多目标检测:这可以通过将上述方法扩展为N个物体来实现。因此,网络现在输出的不是4+C的数字,而是*N*(4+C)*数字。
取一个大小为H x W x 3的输入图像让它通过一组卷积层得到一个大小为H x W x d的卷积体,d是通道的深度或数量。
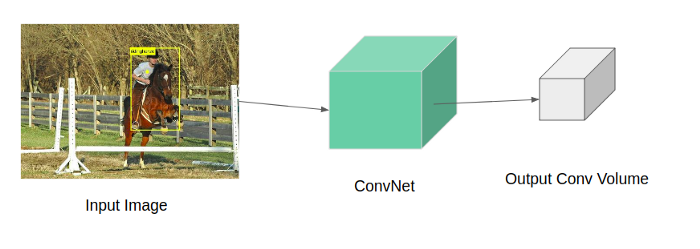
将图像通过ConvNet得到输出的特征图
考虑上面的输出卷积 volume。假设volume大小为7×7×512。使用N个大小为3 x 3 x 512的滤波器,stride=2, padding=1,产生大小为4 x 4 x N的输出volume。
我们取这个大小为4 x 4 x N的输出试着推断它的含义。
在输出的特征图中有16个cells,我们可以说,每个cell都有一个接收域(或感受野),对应到原始图像中的某个点。每个这样的cell都有N个与之相关的数字。正如我前面指出的,N是类别的数量,我们可以说,每个cell都有关于在feature map中对应位置上出现的物体的信息。以同样的方式,还有另一个并行的conv头,其中有4个大小为3 x 3 x 512的滤波器,应用在同一个conv volume上,以获得另一个大小为4 x 4 x 4的输出 —— 这对应边界框的偏移量。
现在我们知道如何用一个神经网络来预测多个目标。但是等一下,我们如何计算这个输出为4x4xn的cell的损失呢?
现在让我们深入到输出层使用的N个滤波器中。从N个滤波器中取出一个,看看它是如何通过对feature map进行卷积得到输出的。
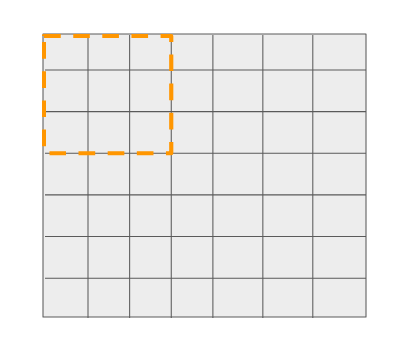
3 x 3 滤波器在7 x 7的特征图上进行卷积,stride = 2
这个3x3的滤波器可以在7x7的网格上移动16个不一样的位置,并做出预测(如前所述),这是非常明显的。
我们知道,网格中的16个cell对应于它之前的层中的一个特定位置。请看下面的图表。输出网格中的第一个cell有一个大小为3x3的参考框。
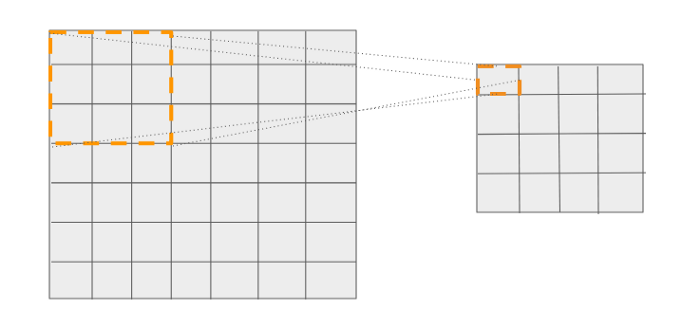
第一个cell可以与输入图像中的特定位置相关联,从该位置进行预测
类似地,输出中的每个cell都可以与输入图像中的特定位置相关联,从该位置进行预测。
因此有16个这样的参考位置(大小为3x3) —— 每个位置都有自己相对于输入图像的坐标。现在通过这些参考位置,我们可以实现两个目标:
1、分类损失:如果N个物体中有一个落在这16个参考位置,即与ground truth的包围框的IOU≥某个阈值,那么我们就知道要匹配哪个ground truth了。
2、回归损失:为什么我们需要这个?假设一个物体落在其中一个参考框中,我们可以简单地输出这些参考位置相对于输入图像的实际坐标。原因是物体不必是方形的。因此,我们不是天真地输出一组固定的框坐标,而是通过输出4个偏移值来调整这些参考位置的默认坐标。现在我们已经知道了ground truth box坐标和相应的参考位置坐标,我们可以简单地使用L1/L2距离来计算回归损失。
与图像分类的任务中只有输出向量要匹配不同,这里我们有16个参考位置要匹配。这意味着该网络可以一次性预测16个物体。要预测的物体数量可以通过对多特征图层次进行预测或通过增加特征图上所谓的参考位置来增加。
这些参考位置就是anchor boxes或者default boxes。
在上面的例子中,只有一个anchor框,也就是每个滤波器位置只做了一个预测。
通常,在feature map中,每个filter位置都可以进行多次预测 —— 这意味着需要有多少预测就有多少个参考。
假设每个filter位置有3个参考。
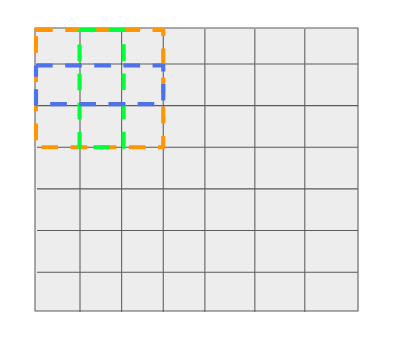
每个filter位置有三个boxes —— 一个是3x3(橙色),一个是1x3(蓝色),另一个是3x1(绿色)
正如我们前面看到的,输出是anchor框的函数,因此如果参考/anchor的数量改变,输出的大小也会改变。因此,网络输出的不是1个anchor点的4x4xN(和4x4x4),而是由于anchor数=3,所以输出的是4x4x(N*3)。
一般来说,单阶段探测器的输出形状可以写成:
分类头的形状:HxWxNA
回归头的形状:HxWx4A
式中,A为使用anchrs的数量。
一个问题!
每个filter位置有多个anchors/参考框的意义是什么?
这使得网络能够在图像的给每个位置上预测多个不同大小的目标。
这种在末端使用卷积层来获得输出的单阶段检测器的变体称为SSD,而在末端使用全连接层来获得输出的变体称为YOLO。
我希望我已经把anchor的概念变得为大家容易理解。anchor总是一个难以把握的概念,在这个博客中仍然有一些关于anchor的未解问题。我想在接下来的文章中回答这些问题。到时候见:)
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~