
如何本地部署ChatGPT大模型
一、介绍 二、iPhone本地部署 三、LLaMa2本地部署 四、Stable Diffusion本地部署 五、ChatGLM部署 5.1 前置安装 5.2 修改代码 5.3、运行
美东时间11月6日举行的OpenAI首届开发者大会(OpenAI DevDay)上,OpenAI宣布,推出自定义版本的ChatGPT,这种由用户定制版本的ChatGPT都简称为GPT。从周二当天开始,用户可以打造自己的GPT,并且公开分享。
此外,Runway的视频生成工具Gen-2也推出新功能“Motion Brush”(运动笔刷),该功能可以通过手势控制生成内容的运动,无需输入文字,大有颠覆未来视频和电影制作行业的趋势,人人都是电影制作导演。
Turbo版GPT 4也迎来了更大的优化加强,各AI公司产品也层出不穷,Polycam发布3DGS、OpenAI发布Dall·E3同款解码器Consistency Decoder、Meetups.AI推出OpenAI助手目录、NousResearch推出长文本语境模型Yarn-Mistral-7b-128k,上周算得上AI春晚了。
而Sam Altman 在大会收尾中暗示,OpenAI 正在进行下一轮重大创新,到时候所有人会发现今天发布的东西是如此的不值一提。
如果说上周之前有人说GPT在未来会取代程序员我还会觉得可笑,那么AI春晚后再有人说这句话我就会倍感焦虑了。
所以计划后续进行一些GPT相关的学习与分享,包括资讯、应用等。
本文会介绍一些本地部署训练一些大模型的方案,主要包括ChatGLM、LLaMa2、AI绘图工具Stable Diffusion、以及一个iOS的本地大模型应用。
一、介绍
什么是GPT?ChatGPT最基本的原理其实就在它的名称中,GPT (Generative Pre-training Transformer)。
-
Chat 聊天
-
G Generative 生成
-
P Pre-training 预训练
-
T Transformer
而与之有鲜明对比的是智普AI开源的ChatGLM-6B,其原理是GLM(General Language Model),虽然跑起来有类似ChatGPT的效果,但在原理上是天差地别,但由于其参数量只有6B大小,且对中文语料支持友好,算得上是个人部署的最佳选择。
此外还有复旦开源的MOSS,Meta开源的LLaMa等。
由于运行依赖GPU,虽然使用CPU也可以部署,但生成速度会非常慢。
二、iPhone本地部署
首先推荐一种最简单的安装部署方式,如果你使用iOS,那么可以使用LLMFarm,安装后只需要下载模型导入即可,详细操作可以参考该项目Readme。
https://github.com/guinmoon/LLMFarm
| 聊天机器人 | 模型 | 生成内容 |
|---|---|---|
 |  |  content3 content3 |
三、LLaMa2本地部署
LLaMA2-7B默认是cuda模式,需要基于GPU来训练运行,对个人用户支持不友好,好在@ggerganov(此人还移植了whisper https://github.com/ggerganov/whisper.cpp)开源了C++实现的基于LLaMA跑在CPU上的版本,可以有效解决MacOS用户难处。
https://github.com/ggerganov/llama.cpp
-
clone代码
git clone https://github.com/ggerganov/llama.cpp
-
进入项目目录
cd llama.cpp
-
创建模型文件夹
mkdir models
-
下载模型
https://huggingface.co/nyanko7/LLaMA-7B/tree/main
-
下载后在models下新建7B目录,将模型放入
tokenizer.model放在models下;checklist.chk、consolidated.00.pth、params.json放在7B目录下。
-
将模型转化为C++版本
python convert-pth-to-ggml.py models/7B/ 1
成功后7B目录下出现ggml-model-f16.bin
-
执行make命令
项目目录下出现main.cpp文件
-
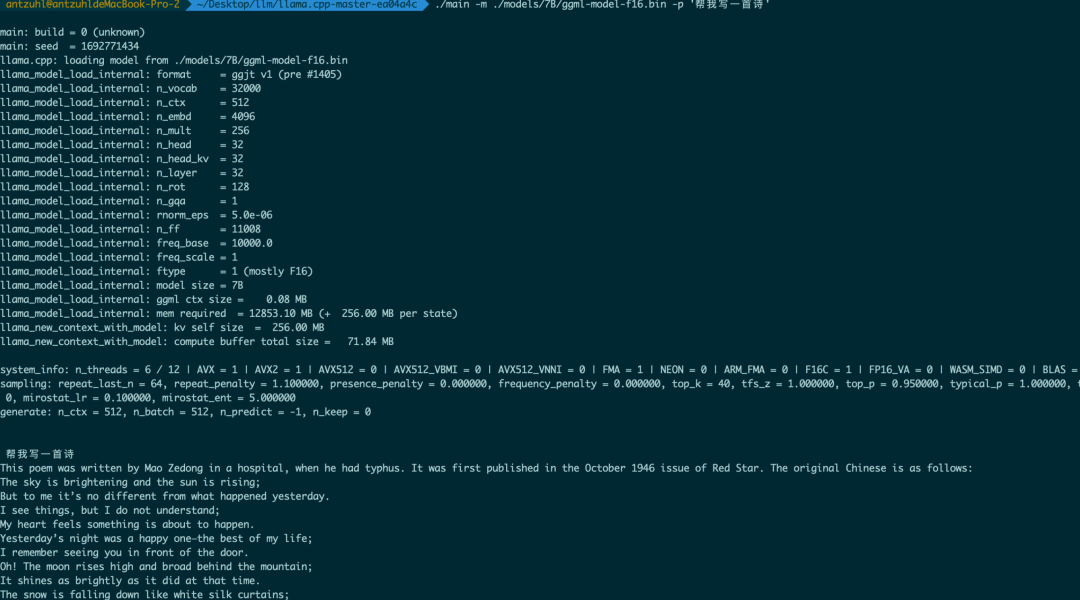
使用
./main -m ./models/7B/ggml-model-f16.bin -p '帮我写一首诗'
四、Stable Diffusion本地部署
Stable Diffusion目前有可以一键运行的包,个人只需要下载不同绘画风格的模型即可。
应用下载: https://github.com/AUTOMATIC1111/stable-diffusion-webui
模型下载: https://huggingface.co/runwayml/stable-diffusion-v1-5
下载后运行webui-user.sh即会提示本地运行端口与地址。
五、ChatGLM部署
5.1 前置安装
-
安装Conda
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.2/install/conda/macos-conda.html
-
安装Git、Brew
-
LFS安装
https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage
https://git-lfs.com/
-
下载glm源码
https://github.com/THUDM/ChatGLM2-6B
-
下载glm2-6b模型
https://huggingface.co/THUDM/chatglm2-6b/tree/main
-
安装mps
curl -O https://mac.r-project.org/openmp/openmp-14.0.6-darwin20-Release.tar.gz
sudo tar fvxz openmp-14.0.6-darwin20-Release.tar.gz -C /
5.2 修改代码
- - gpu
tokenizer = AutoTokenizer.from_pretrained("/Users/?/Desktop/llm-model/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/?/Desktop/llm-model/chatglm2-6b", trust_remote_code=True).half().to('mps')
5.3、运行
python cli_demo.py
文中 链接请点击阅读原文访问。