
【机器学习】交通数据的时间序列分析和预测实战
本文较长,建议收藏!由于篇幅限制,文内精简了部分代码,但不影响阅读体验,若你需要完整代码和数据,请在公众号「机器学习研习院」联系作者获取!
本文主要内容
★ 首先使用探索性数据分析,从不同时间维度探索分析交通系统乘客数量。
★ 创建一个函数来检查时间序列数据的平稳性,通过一阶差分将非平稳性数据转化为平稳性数据。
★ 然后将数据分为训练集和验证集,简单介绍了并应用多个时间序列预测技术,如朴素法、移动平均方法、简单指数平滑、霍尔特线性趋势法、霍尔特-温特法、ARIMA和SARIMAX模型。
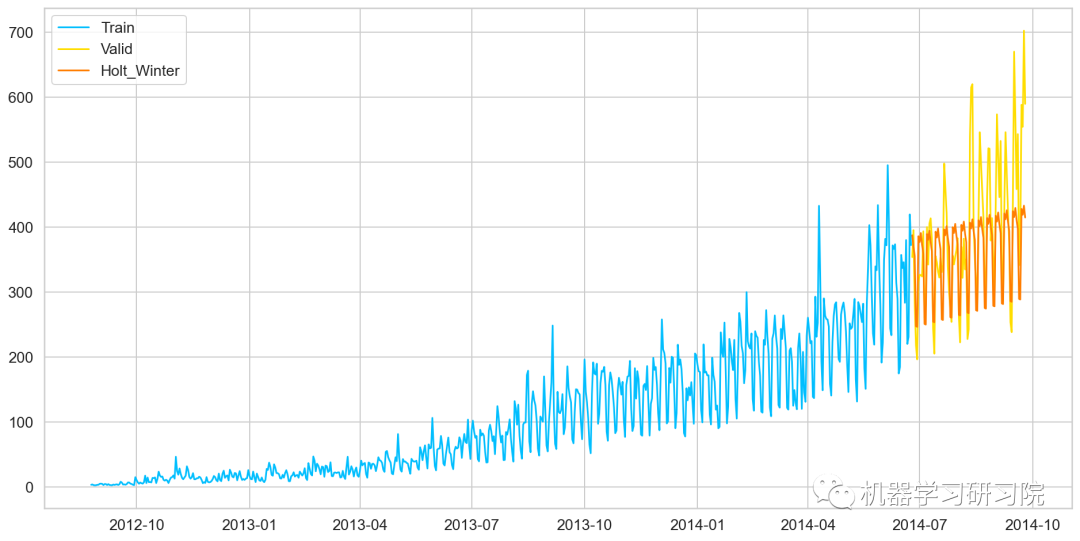
★ 最后使用SARIMAX模型预测未来7个月的流量,因为它有最小的RMSE。如下图所示,蓝色线是训练数据,黄色线是验证数据,红色是使用SARIMAX模型预测的数据。
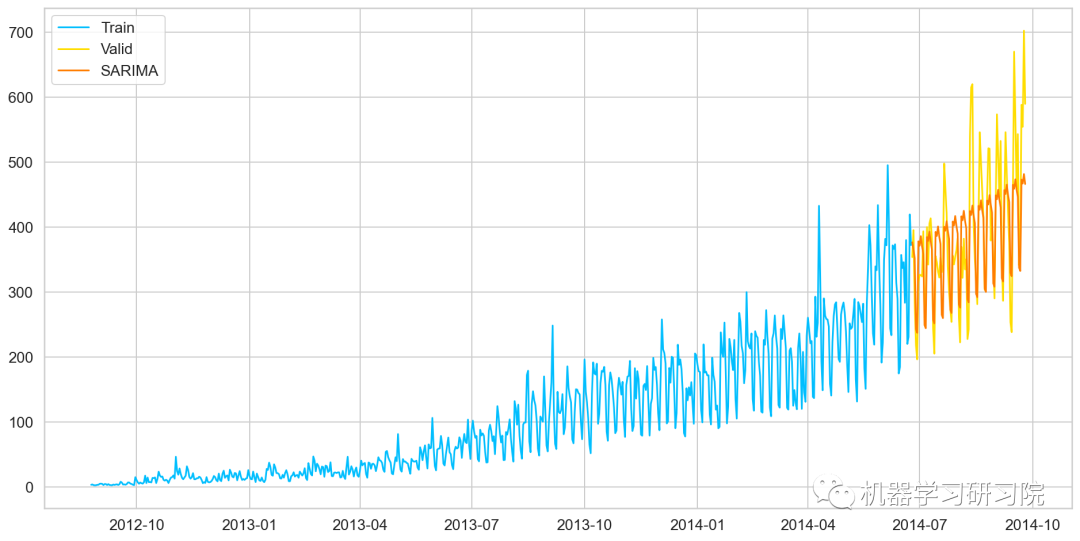
虽然拟合最好的SARIMAX模型,但似乎也没那么棒,当然会有更好的方法来预测该数据。而本文重点是介绍这些基于统计学的经典时间序列预测技术在实际案例中的应用。

导入相关模块

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
from pandas import Series
from sklearn.metrics import mean_squared_error
from math import sqrt
from statsmodels.tsa.seasonal import seasonal_decompose
import statsmodels
import statsmodels.api as sm
from statsmodels.tsa.arima_model import ARIMA数据集准备
去直接读取用pandas读取csv文本文件,并拷贝一份以备用。
train = pd.read_csv("Train.csv")
test = pd.read_csv("Test.csv")
train_org = train.copy()
test_org = test.copy()
查看数据的列名
train.columns, test.columns
(Index(['ID', 'Datetime', 'Count'], dtype='object'),
Index(['ID', 'Datetime'], dtype='object'))
查看数据类型
train.dtypes, test.dtypes
(ID int64
Datetime object
Count int64
dtype: object,
ID int64
Datetime object
dtype: object)
查看数据大小
test.shape, train.shape
((5112, 2), (18288, 3))
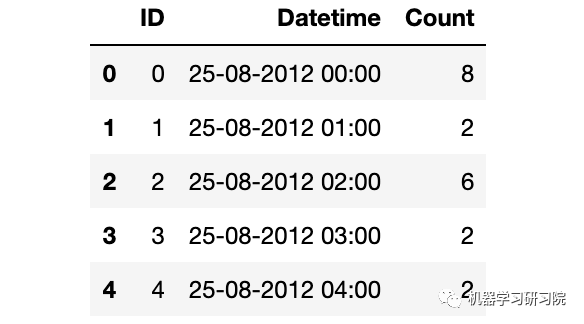
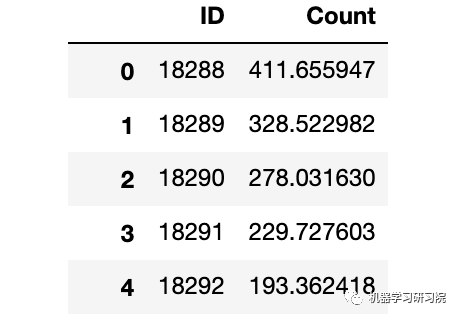
查看数据样貌
train.head()
解析日期格式
train['Datetime'] = pd.to_datetime(train.Datetime, format = '%d-%m-%Y %H:%M')
test['Datetime'] = pd.to_datetime(test.Datetime, format = '%d-%m-%Y %H:%M')
test_org['Datetime'] = pd.to_datetime(test_org.Datetime,format='%d-%m-%Y %H:%M')
train_org['Datetime'] = pd.to_datetime(train_org.Datetime,format='%d-%m-%Y %H:%M')
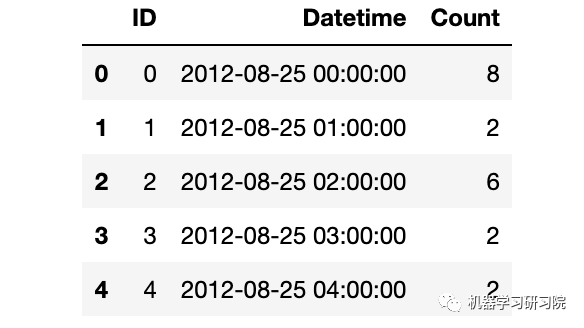
时间日期格式解析结束后,记得查看下结果。
train.dtypes
ID int64
Datetime datetime64[ns]
Count int64
dtype: object
train.head()
时间序列数据的特征工程
时间序列的特征工程一般可以分为以下几类。本次案例我们根据实际情况,选用时间戳衍生时间特征。
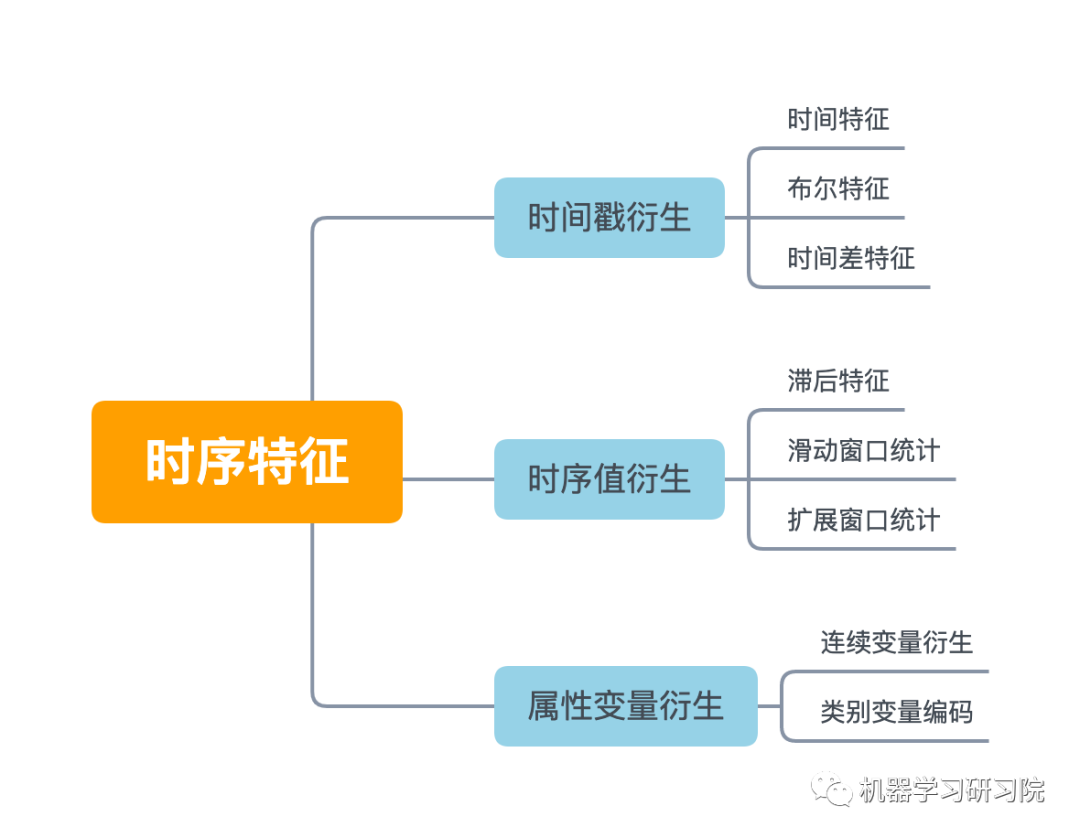
时间戳虽然只有一列,但是也可以根据这个就衍生出很多很多变量了,具体可以分为三大类:时间特征、布尔特征,时间差特征。
本案例首先对日期时间进行时间特征处理,而时间特征包括年、季度、月、周、天(一年、一月、一周的第几天)、小时、分钟...
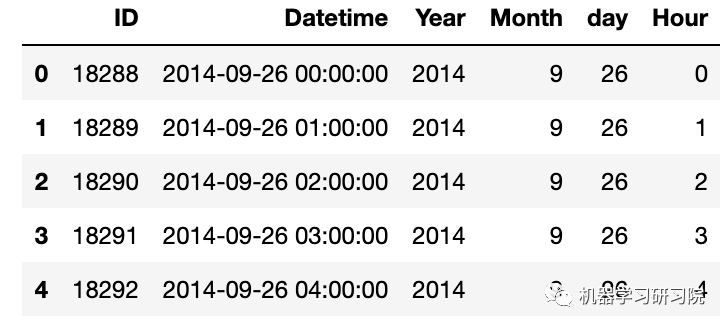
因为需要对test, train, test_org, train_org四个数据框进行同样的处理,直接使用for循环批量提取年月日小时等特征。
for i in (test, train, test_org, train_org):
i['Year'] = i.Datetime.dt.year
i['Month'] = i.Datetime.dt.month
i['day'] = i.Datetime.dt.day
i['Hour'] = i.Datetime.dt.hour
#i["day of the week"] = i.Datetime.dt.dayofweek
test.head()
时间戳衍生中,另一常用的方法为布尔特征,即:
是否年初/年末 是否月初/月末 是否周末 是否节假日 是否特殊日期 是否早上/中午/晚上 等等
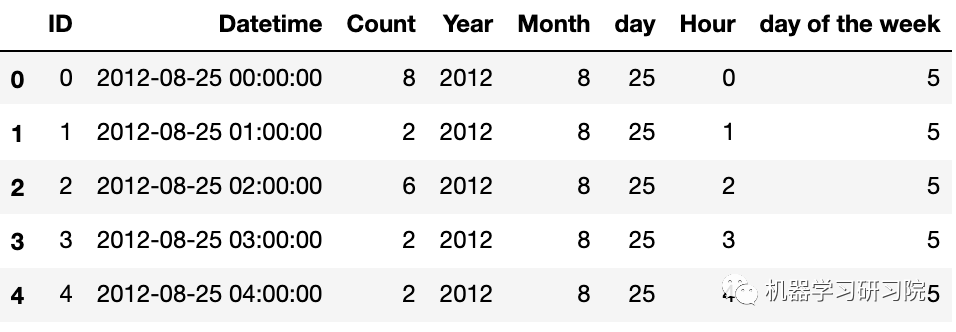
下面判断是否是周末,进行特征衍生的布尔特征转换。首先提取出日期时间的星期几。
train['day of the week'] = train.Datetime.dt.dayofweek
# 返回给定日期时间的星期几
train.head()
再判断day of the week是否是周末(星期六和星期日),是则返回1 ,否则返回0
def applyer(row):
if row.dayofweek == 5 or row.dayofweek == 6:
return 1
else:
return 0
temp = train['Datetime']
temp2 = train.Datetime.apply(applyer)
train['weekend'] = temp2
train.index = train['Datetime']
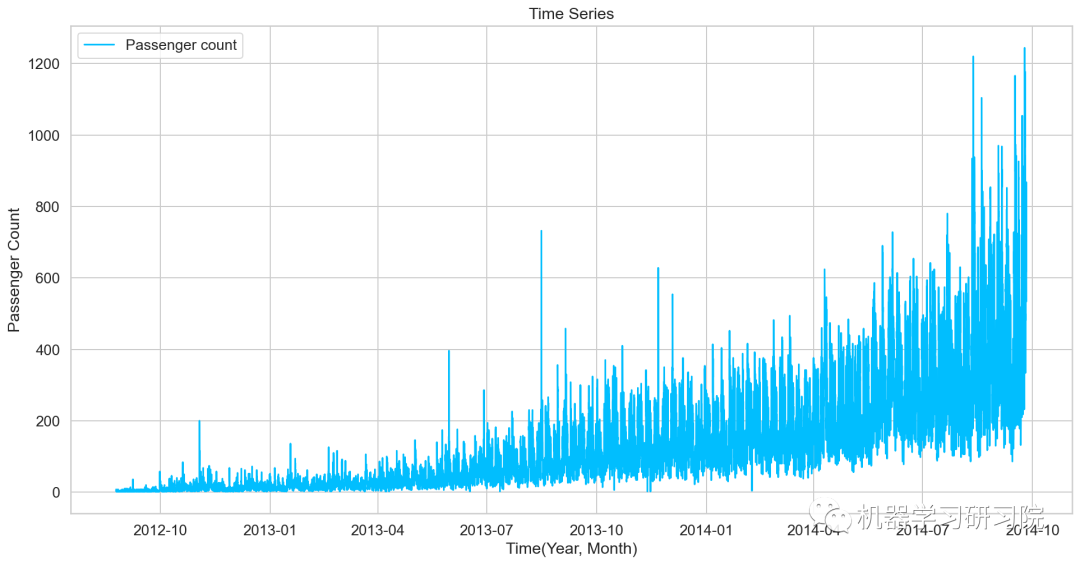
对年月乘客总数统计后可视化,看看总体变化趋势。
df = train.drop('ID',1)
ts = df['Count']
plt.plot(ts, label = 'Passenger count')
探索性数据分析
首先使用探索性数据分析,从不同时间维度探索分析交通系统乘客数量。
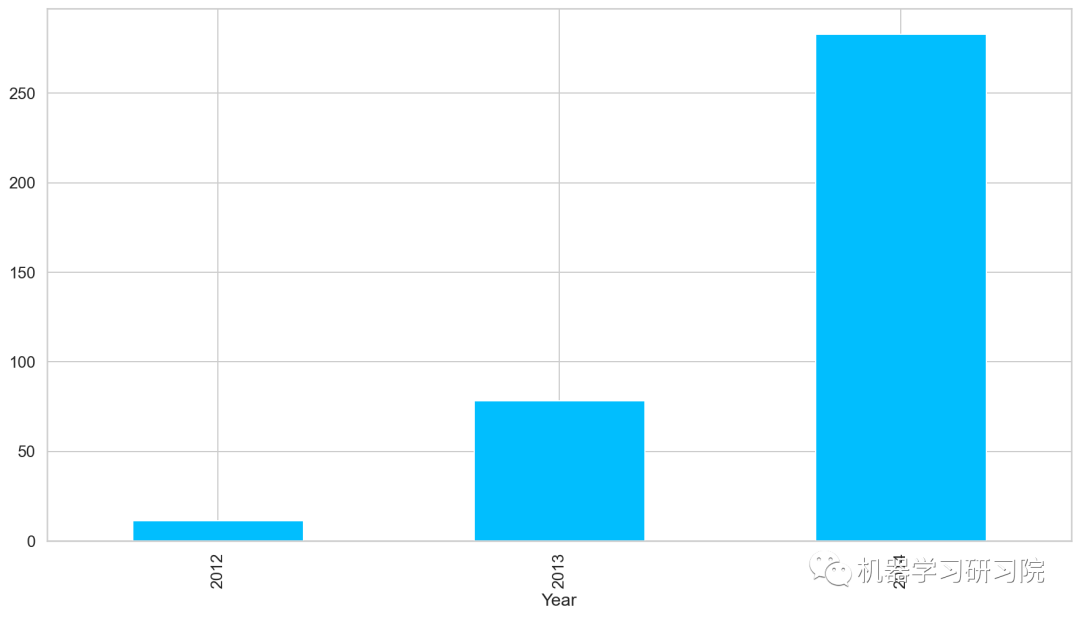
年
对年进行聚合,求所有数据中按年计算的每日平均客流量,从图中可以看出,随着时间的增长,每日平均客流量增长迅速。
train.groupby('Year')['Count'].mean().plot.bar()
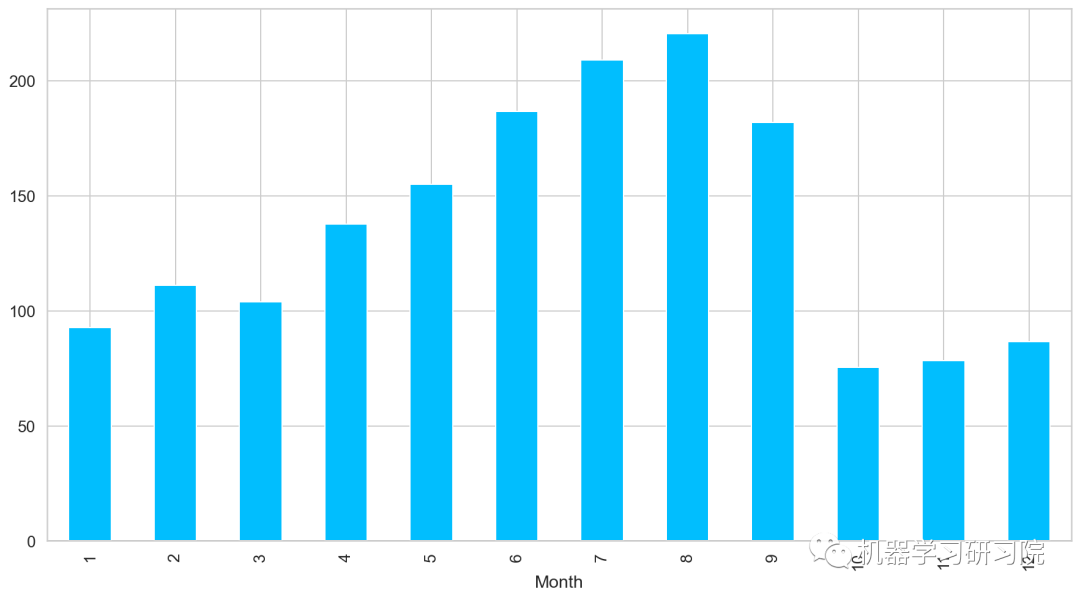
月
对月份进行聚合,求所有数据中按月计算的每日平均客流量,从图中可以看出,春夏季客流量每月攀升,而秋冬季客流量骤减。
train.groupby('Month')['Count'].mean().plot.bar()
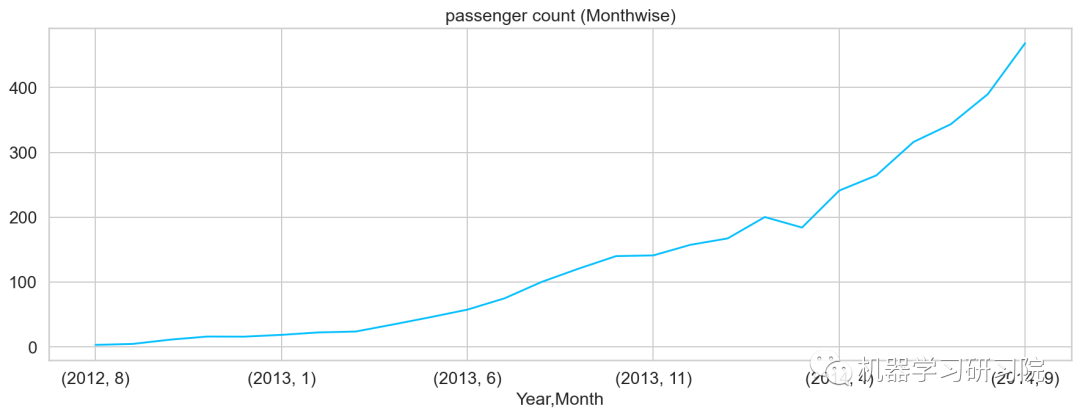
年月
对年月份进行聚合,求所有数据中按年月计算的每日平均客流量,从图可知道,几本是按照平滑指数上升的趋势。
temp = train.groupby(['Year','Month'])['Count'].mean()
temp.plot()# 乘客人数(每月)
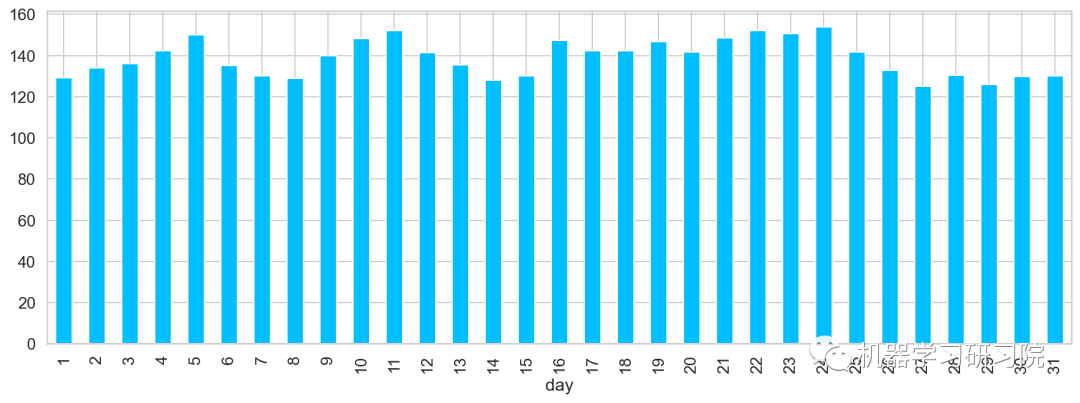
日
对日进行聚合,求所有数据中每月中的每日平均客流量。从图中可大致看出,在5、11、24分别出现三个峰值,该峰值代表了上中旬的高峰期。
train.groupby('day')['Count'].mean(
).plot.bar(figsize = (15,5))
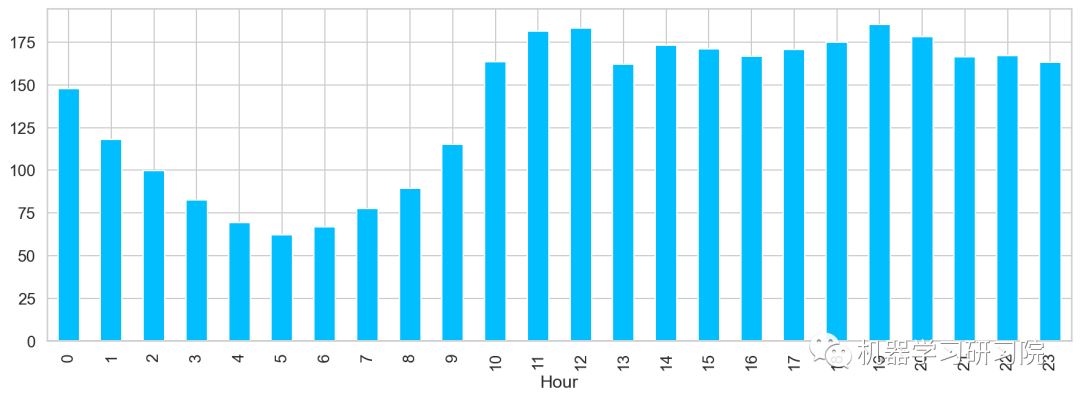
小时
对小时进行聚合,求所有数据中一天内按小时计算的平均客流量,得到了在中(12)晚(19)分别出现两个峰值,该峰值代表了每日的高峰期。
train.groupby('Hour')['Count'].mean().plot.bar()
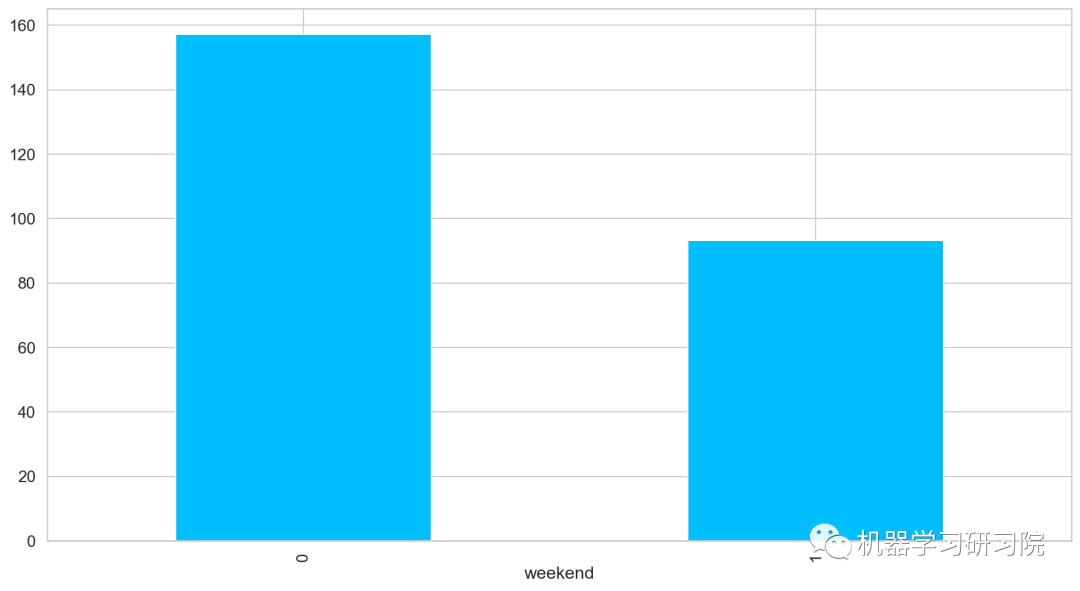
是否周末
对是否是周末进行聚合,求所有数据中按是否周末计算的平均客流量,发现工作日比周末客流量客流量多近一倍,果然大家都是周末都喜欢宅在家里。
train.groupby('weekend')['Count'].mean().plot.bar()
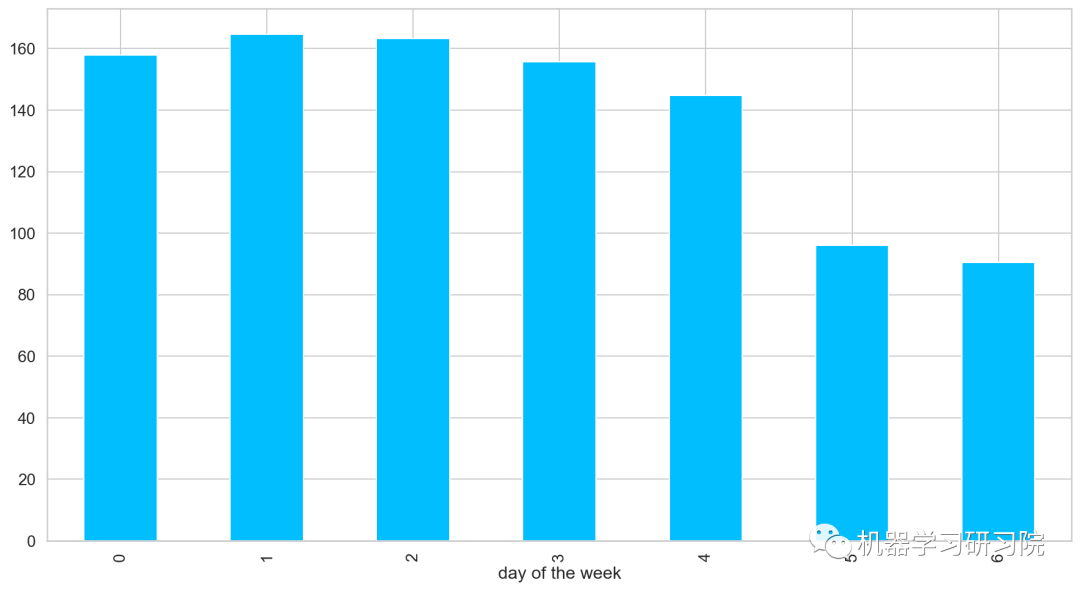
周
对星期进行聚合统计,求所有数据中按是周计算的平均客流量。
train.groupby('day of the week')['Count'].mean().plot.bar()
时间重采样
◎ 重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程;
◎ 将高频率数据聚合到低频率称为降采样(downsampling);
◎ 将低频率数据转换到高频率则称为升采样(unsampling);
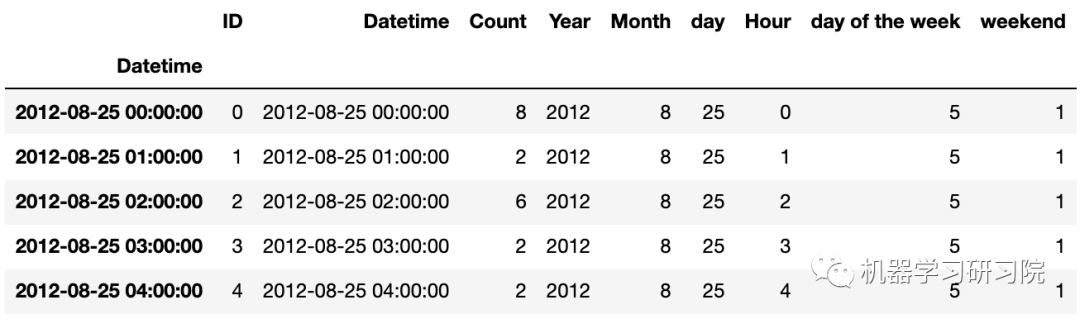
train.head()
Pandas中的resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
Resample方法的主要参数,如需要了解详情,可以戳这里了解更多。
| 参数 | 说明 |
|---|---|
| freq | 表示重采样频率,例如'M'、'5min'、Second(15) |
| how='mean' | 用于产生聚合值的函数名或数组函数,例如'mean'、'ohlc'、np.max等,默认是'mean',其他常用的值由:'first'、'last'、'median'、'max'、'min' |
| axis=0 | 默认是纵轴,横轴设置axis=1 |
接下来对训练数据进行对月、周、日及小时多重采样。其实我们分月份进行采样,然后求月内的均值。事实上重采样,就相当于groupby,只不过是根据月份这个period进行分组。
train = train.drop('ID', 1)
train.timestamp = pd.to_datetime(train.Datetime, format = '%d-%m-%Y %H:%M')
train.index = train.timestamp
# 每小时的时间序列
hourly = train.resample('H').mean()
# 换算成日平均值
daily = train.resample('D').mean()
# 换算成周平均值
weekly = train.resample('W').mean()
# 换算成月平均值
monthly = train.resample('M').mean()
重采样后对其进行可视化,直观地看看其变化趋势。
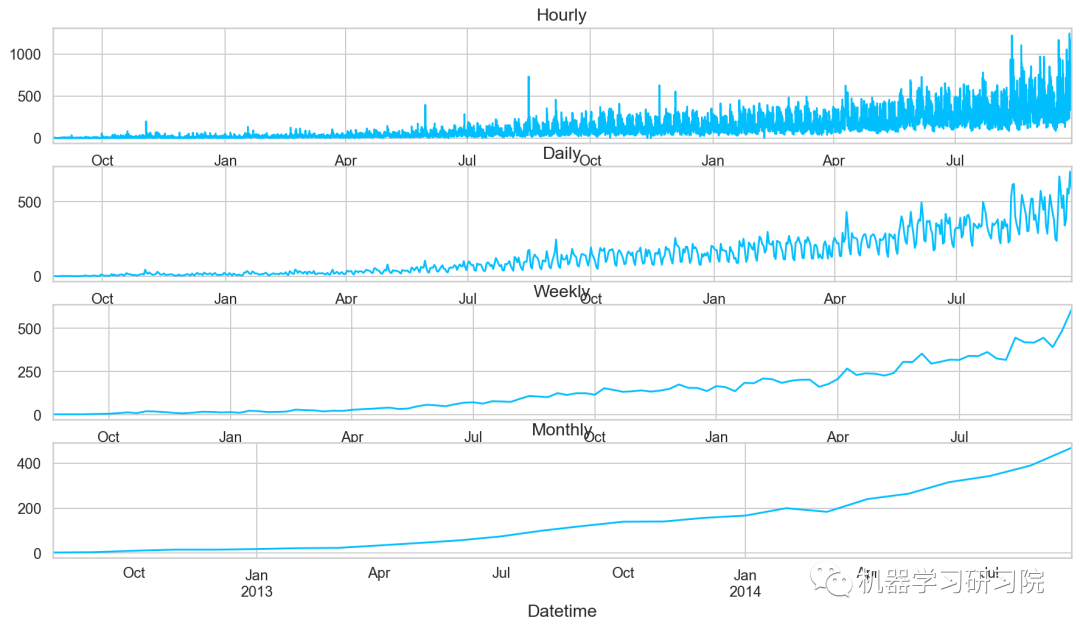
对测试数据也进行相同的时间重采样处理。
test.Timestamp = pd.to_datetime(test.Datetime,format='%d-%m-%Y %H:%M')
test.index = test.Timestamp
# 换算成日平均值
test = test.resample('D').mean()
train.Timestamp = pd.to_datetime(train.Datetime,format='%d-%m-%Y %H:%M')
train.index = train.Timestamp
# C换算成日平均值
train = train.resample('D').mean()
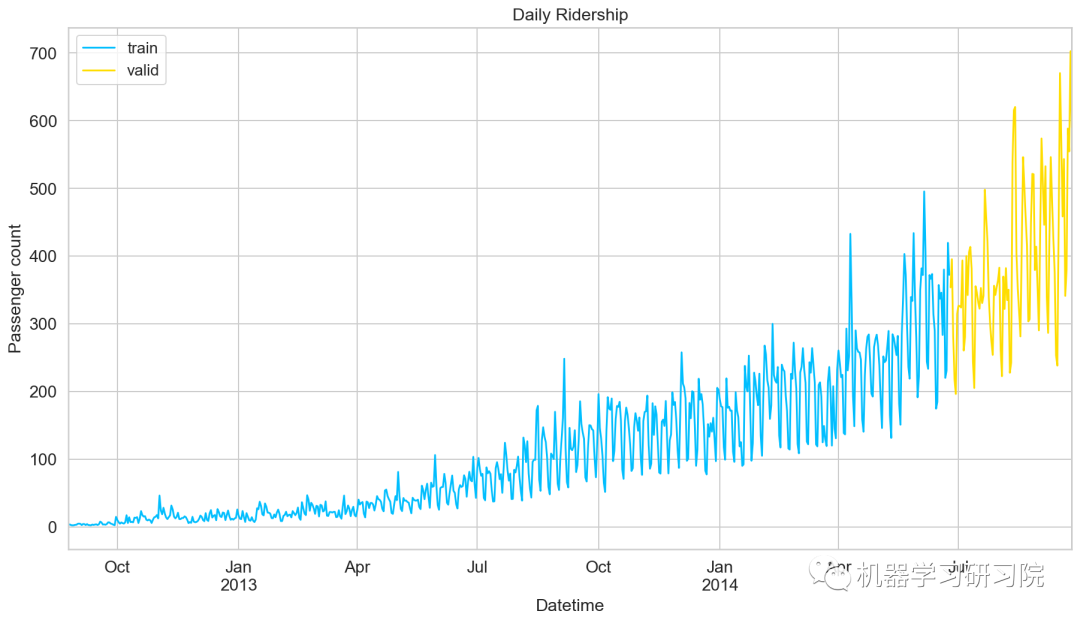
划分训练集和验证集
到目前为止,我们有训练集和测试集,实际上,我们还需要一个验证集,用来实时验证和调整训练模型。下面直接用索引切片的方式做处理。
Train = train.loc['2012-08-25':'2014-06-24']
valid = train['2014-06-25':'2014-09-25']
划分好数据集后,绘制折线图将训练集和验证集进行可视化。
模型建立
数据准备好了,就到了模型建立阶段,这里我们应用多个时间序列预测技术,如朴素法、移动平均方法、简单指数平滑、霍尔特线性趋势法、霍尔特-温特法、ARIMA和SARIMAX模型。
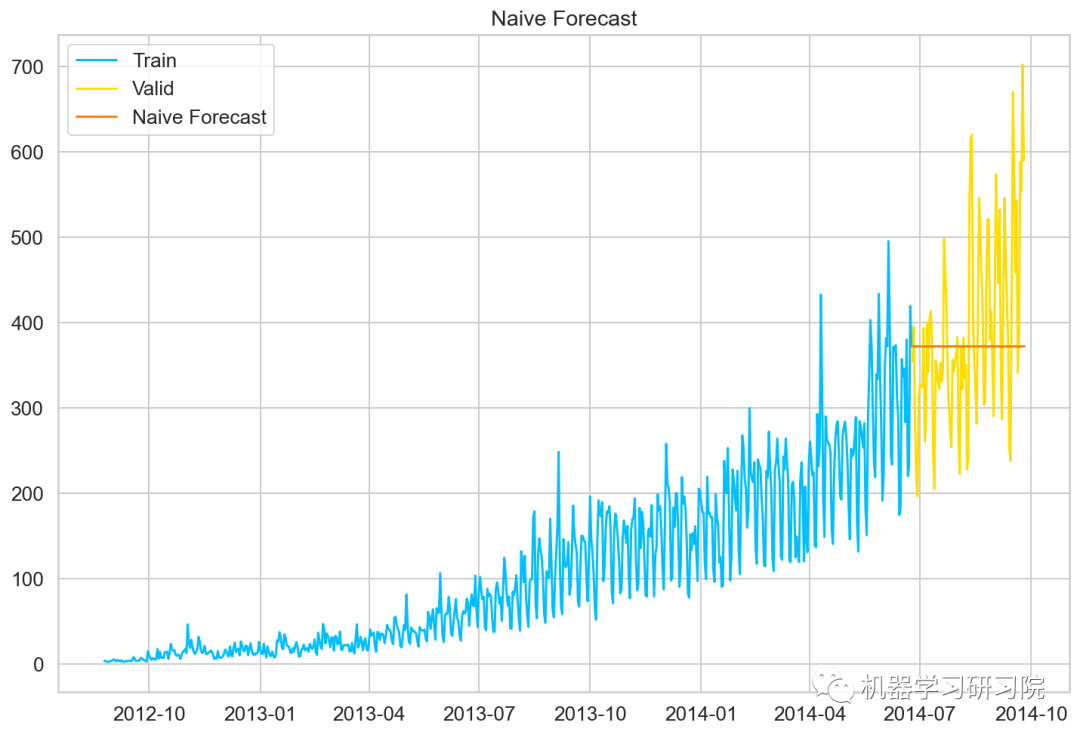
朴素预测法
如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素预测法(Naive Forecast),即 。
因为朴素预测法用最近的观测值作为预测值,因此他最简单的预测方法。虽然朴素预测法并不是一个很好的预测方法,但是它可以为其他预测方法提供一个基准。
dd = np.asarray(Train.Count)
# 将结构数据转化为ndarray
y_hat = valid.copy()
y_hat['naive'] = dd[len(dd)-1]
plt.plot(Train.index, Train['Count'], label = 'Train')
plt.plot(valid.index,valid['Count'], label='Valid')
plt.plot(y_hat.index,y_hat['naive'], label='Naive Forecast')
模型评价
用RMSE检验朴素法的的准确率
rms = sqrt(mean_squared_error(valid.Count, y_hat.naive))
print(rms)
111.79050467496724
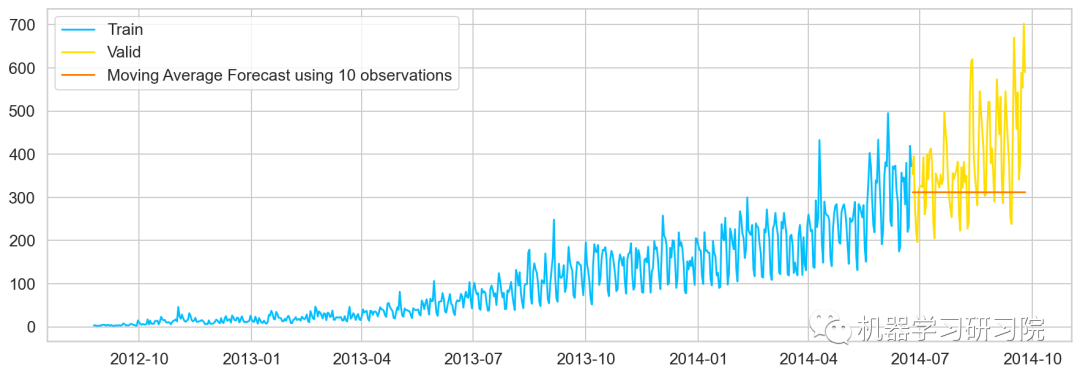
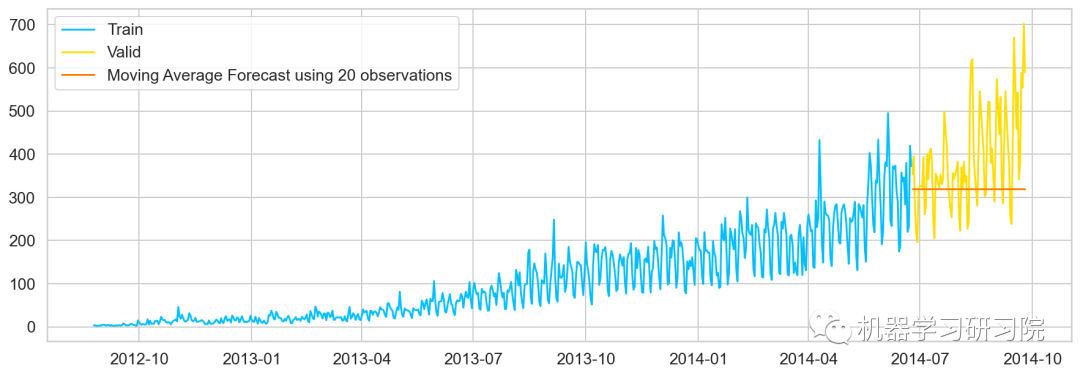
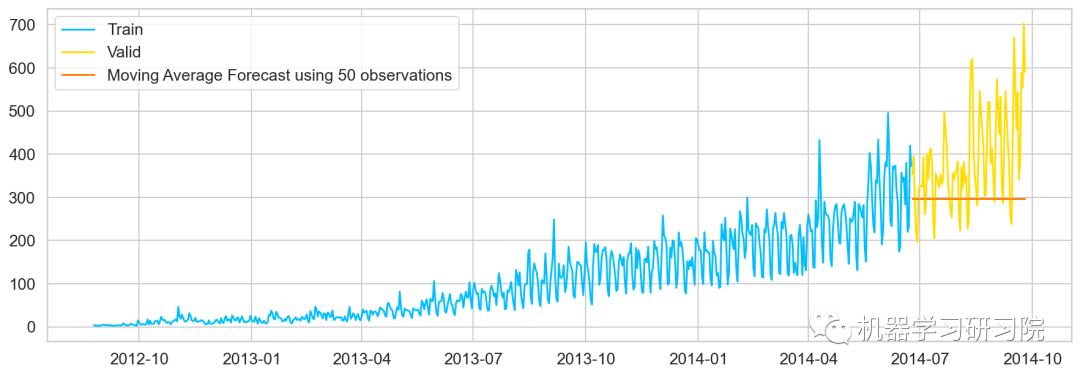
移动平均值法
移动平均法也叫滑动平均法,取前面n个点的平均值作为预测值。
计算移动平均值涉及到一个有时被称为"滑动窗口"的大小值 。使用简单的移动平均模型,我们可以根据之前数值的固定有限数 的平均值预测某个时序中的下一个值。利用一个简单的移动平均模型,我们预测一个时间序列中的下一个值是基于先前值的固定有限个数“p”的平均值。
这样,对于所有的
# 最近10次观测的移动平均值,即滑动窗口大小为P=10
y_hat_avg = valid.copy()
y_hat_avg['moving_avg_forecast'] = Train['Count'].rolling(10).mean().iloc[-1]
# 最近20次观测的移动平均值
y_hat_avg = valid.copy()
y_hat_avg['moving_avg_forecast'] = Train['Count'].rolling(20).mean().iloc[-1]
# 最近30次观测的移动平均值
y_hat_avg = valid.copy()
y_hat_avg['moving_avg_forecast'] = Train['Count'].rolling(50).mean().iloc[-1]
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['moving_avg_forecast'],
label='Moving Average Forecast using 50 observations')
简单指数平滑法
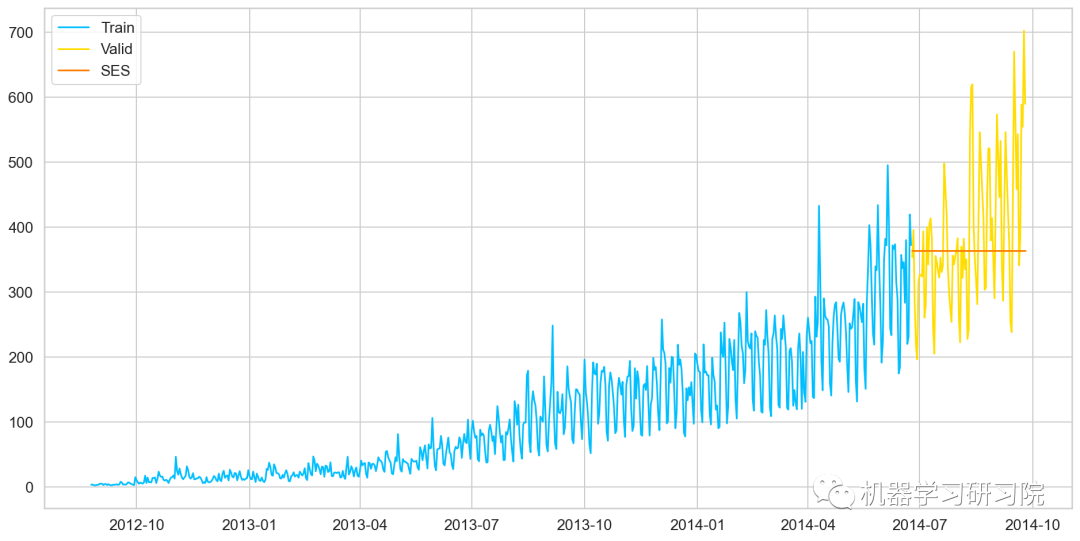
介绍这个之前,需要知道什么是简单平均法(Simple Average),该方法预测的期望值等于所有先前观测点的平均值。
物品价格会随机上涨和下跌,平均价格会保持一致。我们经常会遇到一些数据集,虽然在一定时期内出现小幅变动,但每个时间段的平均值确实保持不变。这种情况下,我们可以认为第二天的价格大致和过去的平均价格值一致。
简单平均法和加权移动平均法在选取时间点的思路上存在较大的差异:
简单平均法将过去数据一个不漏地全部加以同等利用; 移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期更大的权重。
我们就需要在这两种方法之间取一个折中的方法,在将所有数据考虑在内的同时也能给数据赋予不同非权重。
简单指数平滑法 (Simple Exponential Smoothing)相比更早时期内的观测值,越近的观测值会被赋予更大的权重,而时间越久远的权重越小。它通过加权平均值计算出预测值,其中权重随着观测值从早期到晚期的变化呈指数级下降,最小的权重和最早的观测值相关:
其中是平滑参数。
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
y_hat_avg = valid.copy()
fit2 = SimpleExpSmoothing(np.asarray(Train['Count'])).fit(smoothing_level = 0.6, optimized = False)
y_hat_avg['SES'] = fit2.forecast(len(valid))
plt.figure(figsize = (16,8))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.show()
模型评价
用RMSE检验朴素法的的准确率
rms = sqrt(mean_squared_error(valid.Count, y_hat_avg.SES))
print(rms)
113.43708111884514
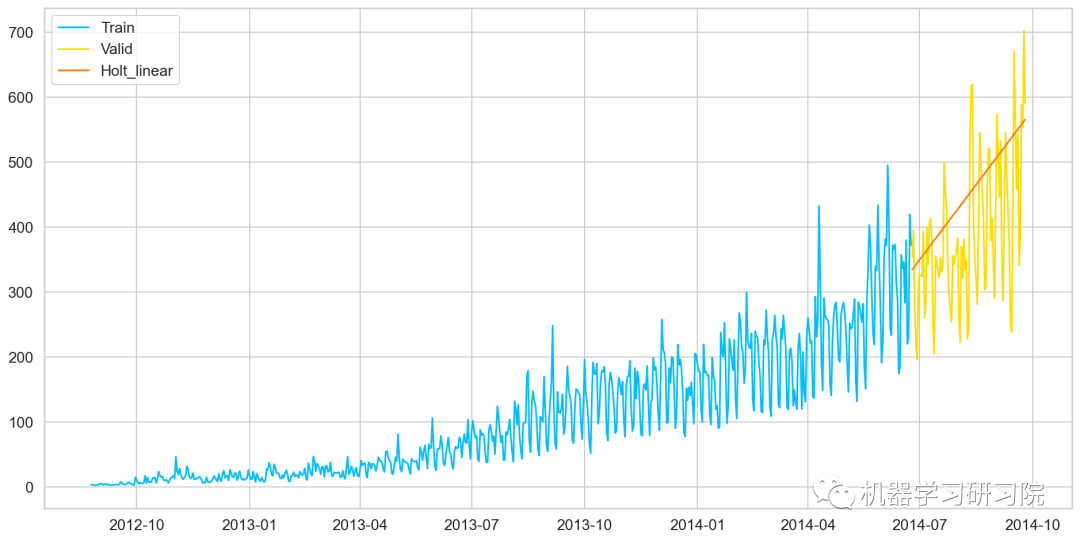
霍尔特线性趋势法
Holts线性趋势模型,该方法考虑了数据集的趋势,即序列的增加或减少性质。
尽管这些方法中的每一种都可以应用趋势:简单平均法会假设最后两点之间的趋势保持不变,或者我们可以平均所有点之间的所有斜率以获得平均趋势,使用移动趋势平均值或应用指数平滑。但我们需要一种无需任何假设就能准确绘制趋势图的方法。这种考虑数据集趋势的方法称为霍尔特线性趋势法,或者霍尔特指数平滑法。
y_hat_avg = valid.copy()
fit1 = Holt(np.asarray(Train['Count'])
).fit(smoothing_level = 0.3, smoothing_slope = 0.1)
y_hat_avg['Holt_linear'] = fit1.forecast(len(valid))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['Holt_linear'], label='Holt_linear')
模型评价
用RMSE检验朴素法的的准确率
rms = sqrt(mean_squared_error(valid.Count, y_hat_avg.Holt_linear))
print(rms)
112.94278345314041
由于holts线性趋势,到目前为止具有最好的准确性,我们尝试使用它来预测测试数据集。
predict = fit1.forecast(len(test))
test['prediction'] = predict
# 计算每小时计数的比率
train_org['ratio'] = train_org['Count']/train_org['Count'].sum()
# 按小时计数分组
temp = train_org.groupby(['Hour'])['ratio'].sum()
# 保存聚合后的数据
pd.DataFrame(temp, columns =['ratio']).to_csv('GROUPBY.csv')
temp2 = pd.read_csv('GROUPBY.csv')
# 按日、月、年合并test和test_org
merge = pd.merge(test,test_org, on= ('day','Month','Year'),how = 'left')
merge['Hour'] = merge['Hour_y']
merge['ID'] = merge['ID_y']
merge.head()
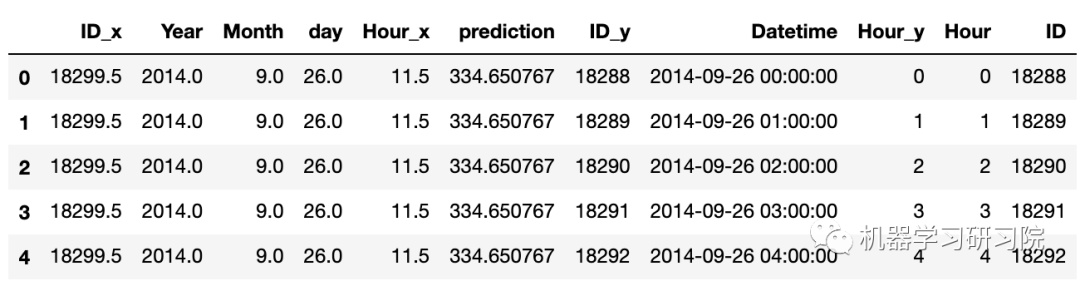
删除不需要的特征。
merge = merge.drop(['Year','Month','Datetime','Hour_x','Hour_y','ID_x','ID_y'], axis =1)
merge.head()
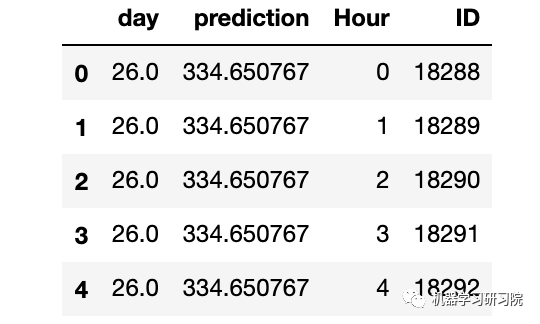
通过合并merge和temp2进行预测。
prediction = pd.merge(merge,temp2, on = 'Hour', how = 'left')
# 将比率转换成原始比例
prediction['Count'] = prediction['prediction']*prediction['ratio']*24
submission = prediction
pd.DataFrame(submission, columns=['ID','Count']).to_csv('Holt_Linear.csv')
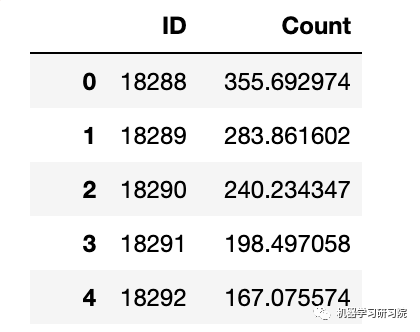
霍尔特-温特法
霍尔特-温特(Holt-Winters)方法,在 Holt模型基础上引入了 Winters 周期项(也叫做季节项),可以用来处理月度数据(周期 12)、季度数据(周期 4)、星期数据(周期 7)等时间序列中的固定周期的波动行为。引入多个 Winters 项还可以处理多种周期并存的情况。
# Holts Winter model
y_hat_avg = valid.copy()
fit1 = ExponentialSmoothing(np.asarray(Train['Count']), seasonal_periods = 7, trend = 'add', seasonal = 'add',).fit()
y_hat_avg['Holts_Winter'] = fit1.forecast(len(valid))
plt.plot( Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['Holts_Winter'], label='Holt_Winter')
模型评价
用RMSE检验朴素法的的准确率
rms = sqrt(mean_squared_error(valid.Count, y_hat_avg.Holts_Winter))
print(rms)
82.37292653831038
模型预测
predict=fit1.forecast(len(test))
test['prediction']=predict
# 按日、月、年合并Test和test_original
merge=pd.merge(test, test_org, on=('day','Month', 'Year'), how='left')
merge['Hour']=merge['Hour_y']
merge=merge.drop(['Year', 'Month', 'Datetime','Hour_x','Hour_y'], axis=1)
# 通过合并merge和temp2进行预测
prediction=pd.merge(merge, temp2, on='Hour', how='left')
# 将比率转换成原始比例
prediction['Count']=prediction['prediction']*prediction['ratio']*24
prediction['ID']=prediction['ID_y']
submission=prediction.drop(['day','Hour','ratio','prediction', 'ID_x', 'ID_y'],axis=1)
# 转换最终提交的csv格式
pd.DataFrame(submission, columns=['ID','Count']).to_csv('Holt winters.csv')
迪基-福勒检验
函数执行迪基-福勒检验以确定数据是否为平稳时间序列。
在统计学里,迪基-福勒检验(Dickey-Fuller test)可以测试一个自回归模型是否存在单位根(unit root)。回归模型可以写为,是一阶差分。测试是否存在单位根等同于测试是否 。因为迪基-福勒检验测试的是残差项,并非原始数据,所以不能用标准t统计量。我们需要用迪基-福勒统计量。
from statsmodels.tsa.stattools import adfuller
def test_stationary(timeseries):
# 确定滚动数据
rolmean = timeseries.rolling(24).mean()
rolstd = timeseries.rolling(24).std()
# 会议滚动数据
orig = plt.plot(timeseries, color='blue',label='Original')
mean = plt.plot(rolmean, color='red', label='Rolling Mean')
std = plt.plot(rolstd, color='black', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
# 执行迪基-福勒检验
print('Results of Dickey-Fuller Test: ')
dftest = adfuller(timeseries,autolag = 'AIC')
dfoutput = pd.Series(dftest[0:4], index = ['Test Statistic', 'P-value', '#lags used', 'No of Observations used'])
for key, value in dftest[4].items():
dfoutput['Critical Value (%s)' %key] = value
print(dfoutput)
绘制检验图
test_stationary(train_org['Count'])
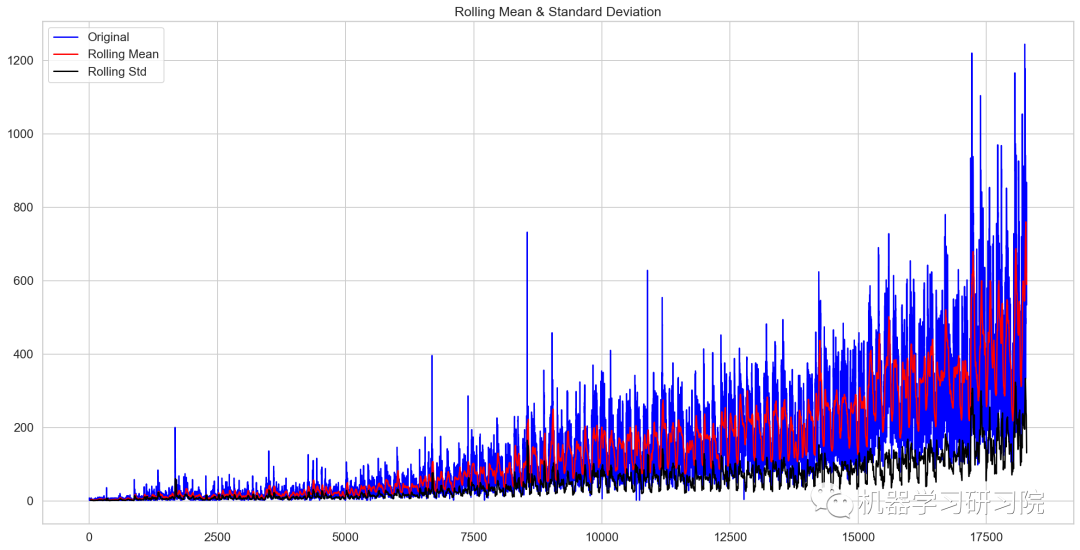
Results of Dickey-Fuller Test:
Test Statistic -4.456561
P-value 0.000235
#lags used 45.000000
No of Observations used 18242.000000
Critical Value (1%) -3.430709
Critical Value (5%) -2.861698
Critical Value (10%) -2.566854
dtype: float64
检验统计数据表明,由于p值小于0.05,数据是平稳的。
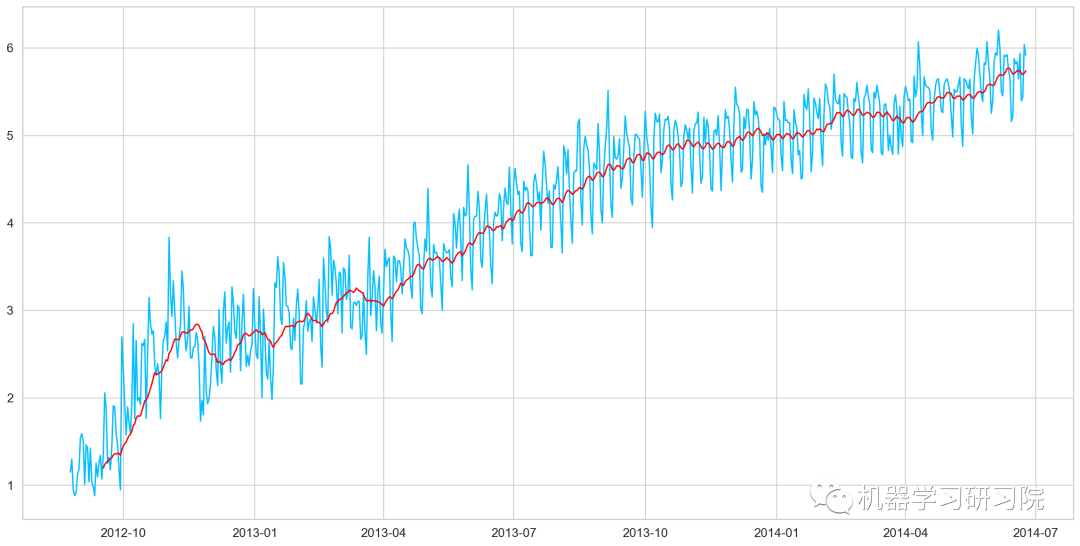
移动平均值
在统计学中,移动平均(moving average),又称滑动平均是一种通过创建整个数据集中不同子集的一系列平均数来分析数据点的计算方法。移动平均通常与时间序列数据一起使用,以消除短期波动,突出长期趋势或周期。
对原始数据求对数。
Train_log = np.log(Train['Count'])
valid_log = np.log(Train['Count'])
Train_log.head()
Datetime
2012-08-25 1.152680
2012-08-26 1.299283
2012-08-27 0.949081
2012-08-28 0.882389
2012-08-29 0.916291
Freq: D, Name: Count, dtype: float64
绘制移动平均值曲线
moving_avg = Train_log.rolling(24).mean()
plt.plot(Train_log)
plt.plot(moving_avg, color = 'red')
plt.show()
去除移动平均值后再进行迪基-福勒检验
train_log_moving_avg_diff = Train_log - moving_avg
train_log_moving_avg_diff.dropna(inplace = True)
test_stationary(train_log_moving_avg_diff)
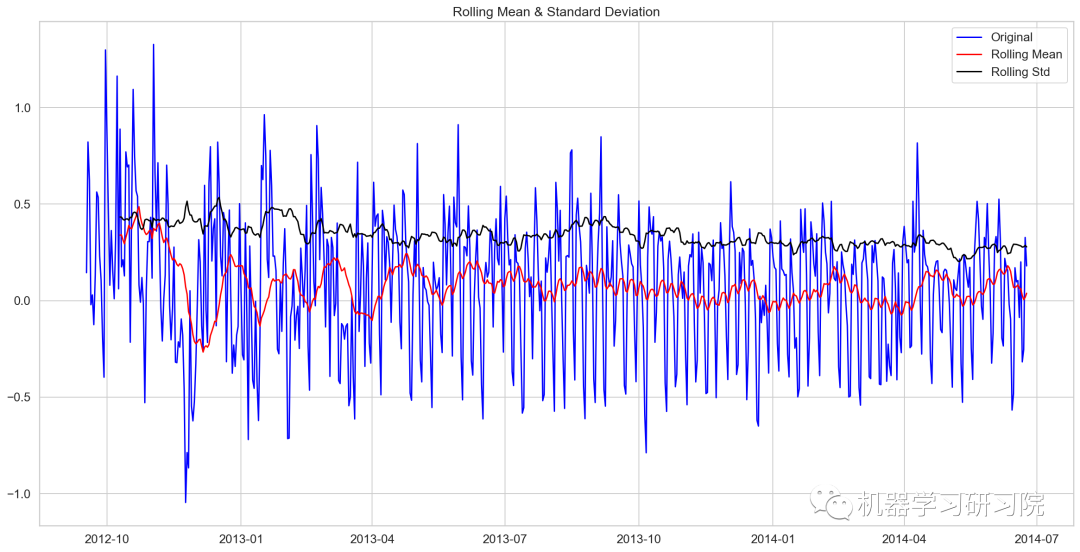
Results of Dickey-Fuller Test:
Test Statistic -5.861646e+00
P-value 3.399422e-07
#lags used 2.000000e+01
No of Observations used 6.250000e+02
Critical Value (1%) -3.440856e+00
Critical Value (5%) -2.866175e+00
Critical Value (10%) -2.569239e+00
dtype: float64
对数时序数据求二阶差分后再迪基-福勒检验
train_log_diff = Train_log - Train_log.shift(1)
test_stationary(train_log_diff.dropna())
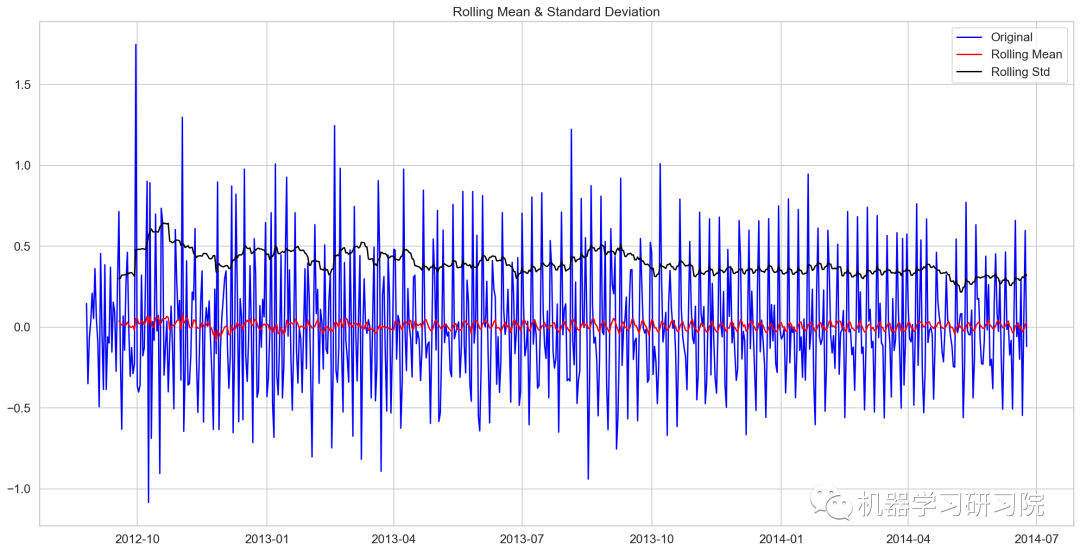
Results of Dickey-Fuller Test:
Test Statistic -8.237568e+00
P-value 5.834049e-13
#lags used 1.900000e+01
No of Observations used 6.480000e+02
Critical Value (1%) -3.440482e+00
Critical Value (5%) -2.866011e+00
Critical Value (10%) -2.569151e+00
dtype: float64
季节性分解
对进行对数转换后的原始数据进行季节性分解。
decomposition = seasonal_decompose(
pd.DataFrame(Train_log).Count.values, freq = 24)
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
plt.plot(Train_log, label='Original')
plt.plot(trend, label='Trend')
plt.plot(seasonal,label='Seasonality')
plt.plot(residual, label='Residuals')
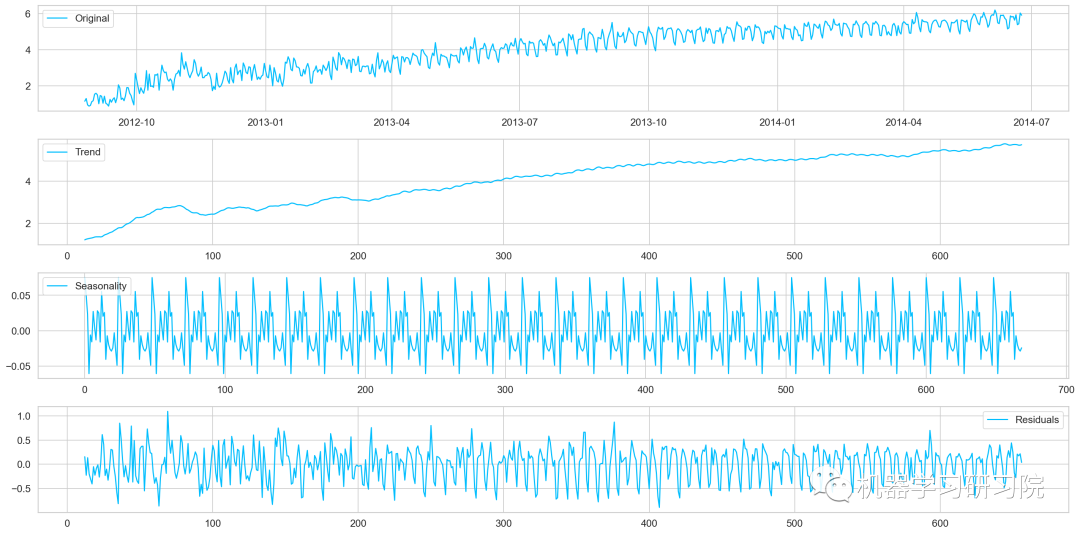
对季节性分解后的残差数据进行迪基-福勒检验
train_log_decompose = pd.DataFrame(residual)
train_log_decompose['date'] = Train_log.index
train_log_decompose.set_index('date', inplace=True)
train_log_decompose.dropna(inplace = True)
test_stationary(train_log_decompose[0])
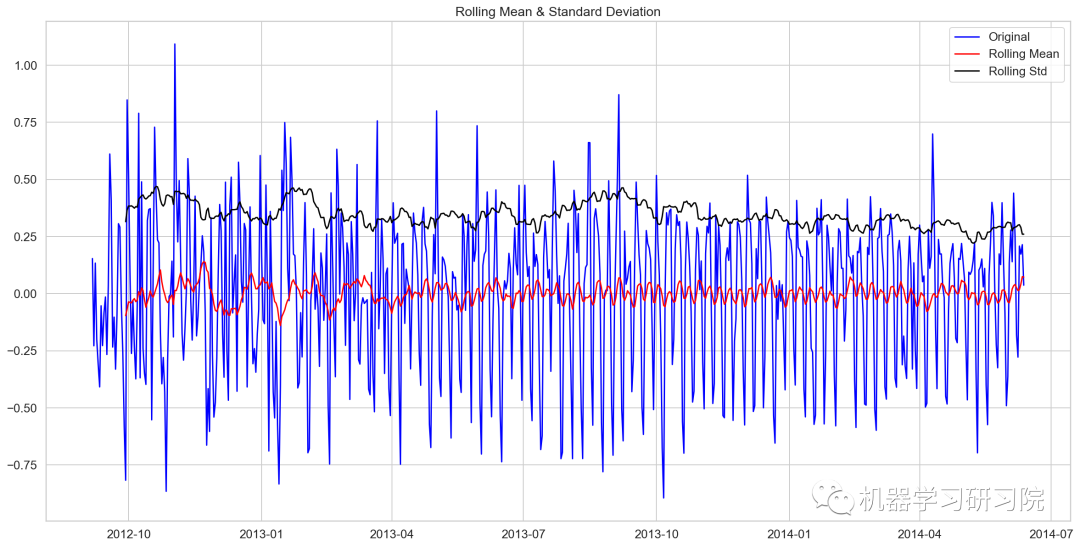
Results of Dickey-Fuller Test:
Test Statistic -7.822096e+00
P-value 6.628321e-12
#lags used 2.000000e+01
No of Observations used 6.240000e+02
Critical Value (1%) -3.440873e+00
Critical Value (5%) -2.866183e+00
Critical Value (10%) -2.569243e+00
dtype: float64
自相关和偏自相关图
from statsmodels.tsa.stattools import acf, pacf
lag_acf = acf(train_log_diff.dropna(), nlags=25)
lag_pacf = pacf(train_log_diff.dropna(), nlags=25, method='ols')
plt.plot(lag_acf)
plt.axhline(y=0,linestyle='--',color='gray')
plt.axhline(y=-1.96/np.sqrt(len(train_log_diff.dropna())),linestyle='--',color='gray')
plt.axhline(y=1.96/np.sqrt(len(train_log_diff.dropna())),linestyle='--',color='gray')
plt.plot(lag_pacf)
plt.axhline(y=0,linestyle='--',color='gray')
plt.axhline(y=-1.96/np.sqrt(len(train_log_diff.dropna())),linestyle='--',color='gray')
plt.axhline(y=1.96/np.sqrt(len(train_log_diff.dropna())),linestyle='--',color='gray')
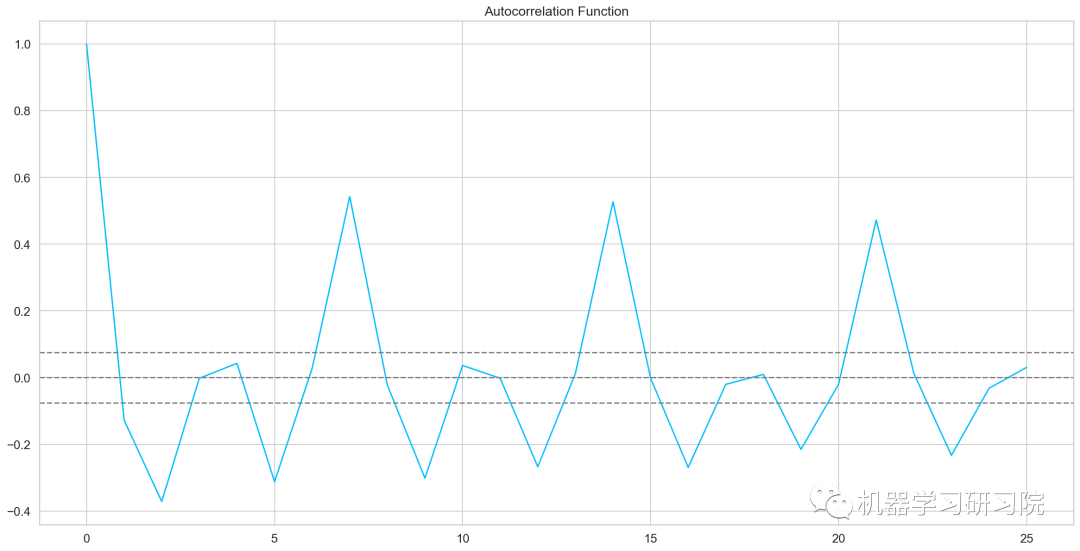
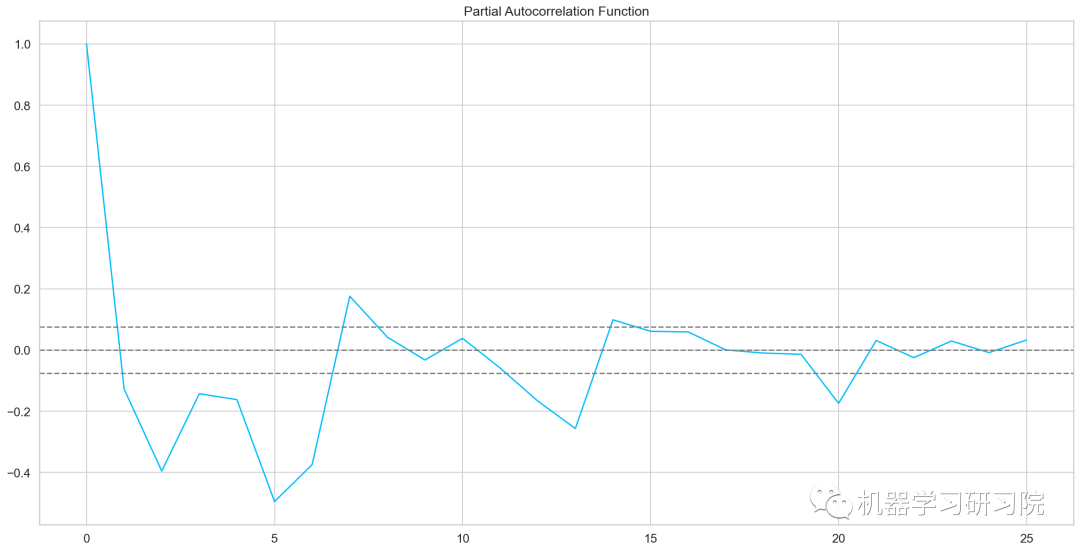
AR模型
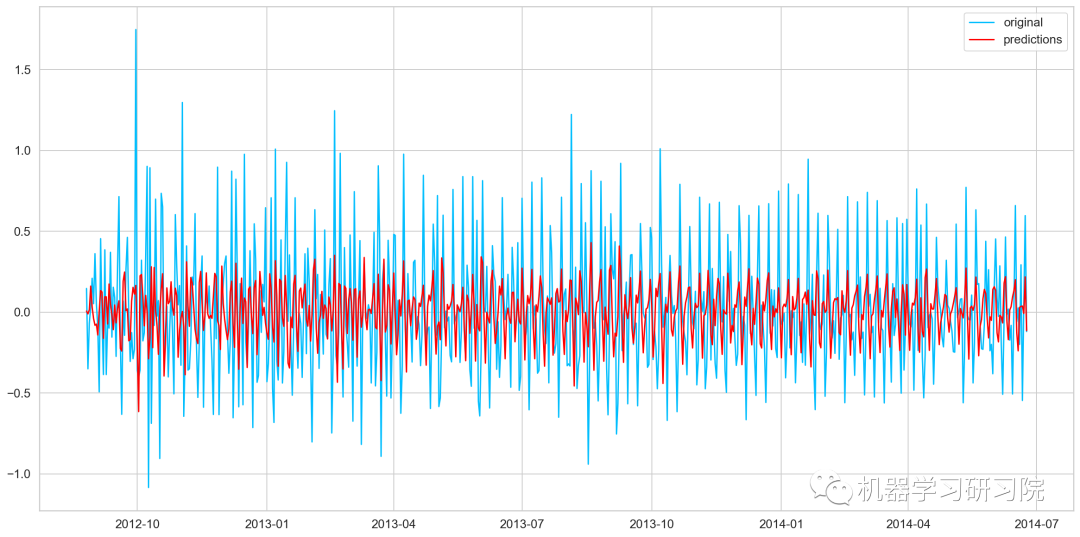
AR模型训练及预测
model = ARIMA(Train_log, order = (2,1,0))
# 这里q值是零,因为它只是AR模型
results_AR = model.fit(disp = -1)
plt.plot(train_log_diff.dropna(), label='original')
plt.plot(results_AR.fittedvalues, color='red', label='predictions')
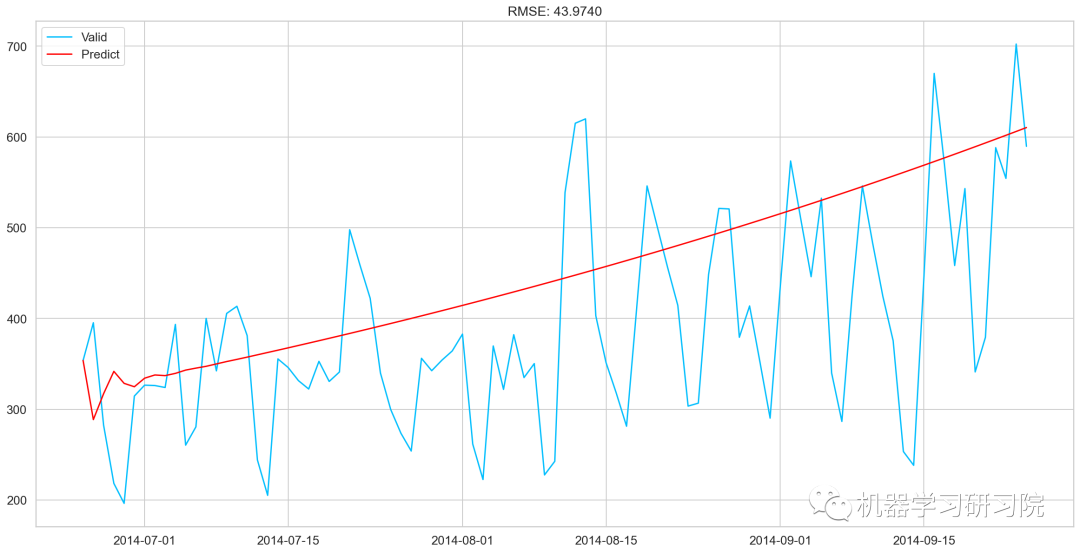
AR_predict=results_AR.predict(start="2014-06-25", end="2014-09-25")
AR_predict=AR_predict.cumsum().shift().fillna(0)
AR_predict1=pd.Series(np.ones(valid.shape[0]) * np.log(valid['Count'])[0], index = valid.index)
AR_predict1=AR_predict1.add(AR_predict,fill_value=0)
AR_predict = np.exp(AR_predict1)
plt.plot(valid['Count'], label = "Valid")
plt.plot(AR_predict, color = 'red', label = "Predict")
plt.legend(loc= 'best')
plt.title('RMSE: %.4f'% (np.sqrt(np.dot(AR_predict, valid['Count']))/valid.shape[0]))
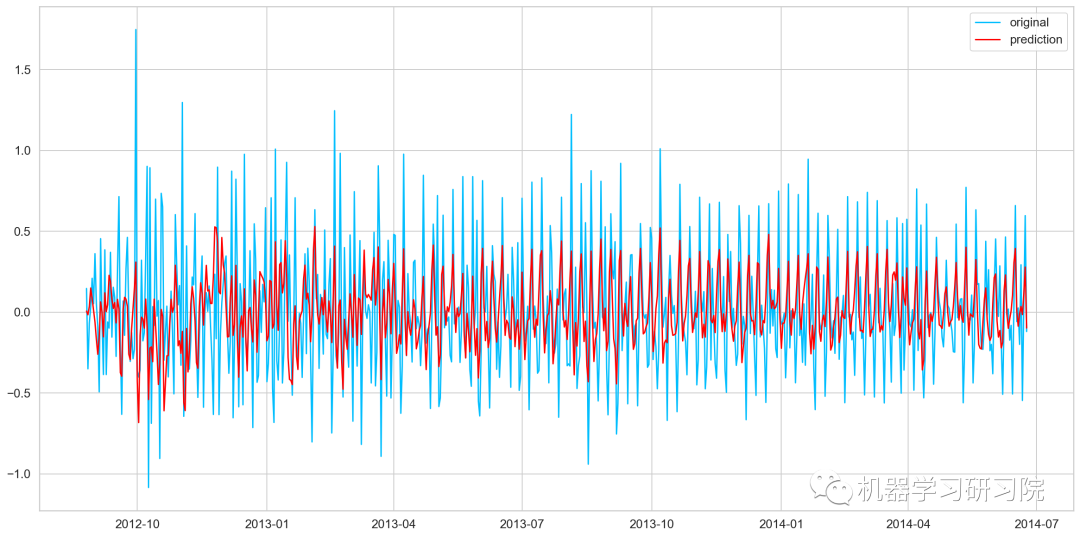
MA模型
model = ARIMA(Train_log, order=(0, 1, 2))
# 这里的p值是零,因为它只是MA模型
results_MA = model.fit(disp=-1)
plt.plot(train_log_diff.dropna(), label='original')
plt.plot(results_MA.fittedvalues, color='red', label='prediction')
MA_predict=results_MA.predict(start="2014-06-25", end="2014-09-25")
MA_predict=MA_predict.cumsum().shift().fillna(0)
MA_predict1=pd.Series(np.ones(valid.shape[0]) * np.log(valid['Count'])[0], index = valid.index)
MA_predict1=MA_predict1.add(MA_predict,fill_value=0)
MA_predict = np.exp(MA_predict1)
plt.plot(valid['Count'], label = "Valid")
plt.plot(MA_predict, color = 'red', label = "Predict")
plt.legend(loc= 'best')
plt.title('RMSE: %.4f'% (np.sqrt(np.dot(MA_predict, valid['Count']))/valid.shape[0]))
ARMA模型
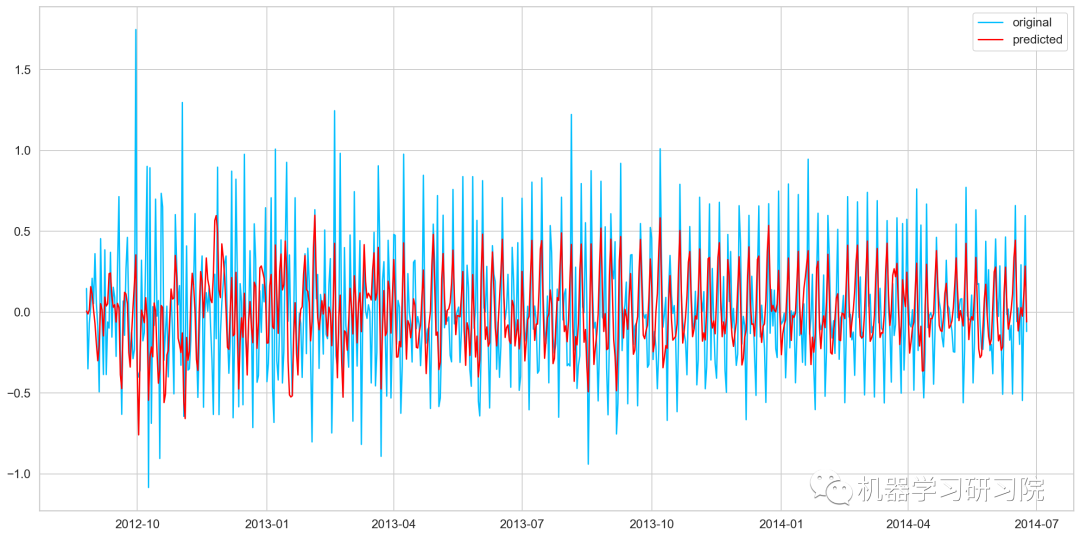
model = ARIMA(Train_log, order=(2, 1, 2))
results_ARIMA = model.fit(disp=-1)
plt.plot(train_log_diff.dropna(), label='original')
plt.plot(results_ARIMA.fittedvalues, color='red', label='predicted')
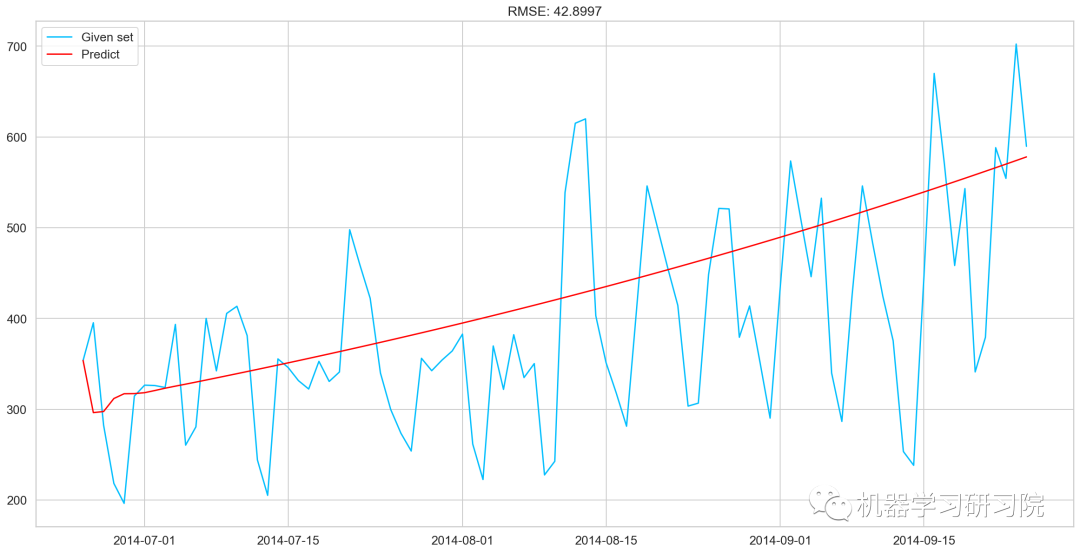
def check_prediction_diff(predict_diff, given_set):
predict_diff= predict_diff.cumsum().shift().fillna(0)
predict_base = pd.Series(np.ones(given_set.shape[0]) * np.log(given_set['Count'])[0], index = given_set.index)
predict_log = predict_base.add(predict_diff,fill_value=0)
predict = np.exp(predict_log)
plt.plot(given_set['Count'], label = "Given set")
plt.plot(predict, color = 'red', label = "Predict")
plt.legend(loc= 'best')
plt.title('RMSE: %.4f'% (np.sqrt(np.dot(predict, given_set['Count']))/given_set.shape[0]))
def check_prediction_log(predict_log, given_set):
predict = np.exp(predict_log)
plt.plot(given_set['Count'], label = "Given set")
plt.plot(predict, color = 'red', label = "Predict")
plt.legend(loc= 'best')
plt.title('RMSE: %.4f'% (np.sqrt(np.dot(predict, given_set['Count']))/given_set.shape[0]))
plt.show()
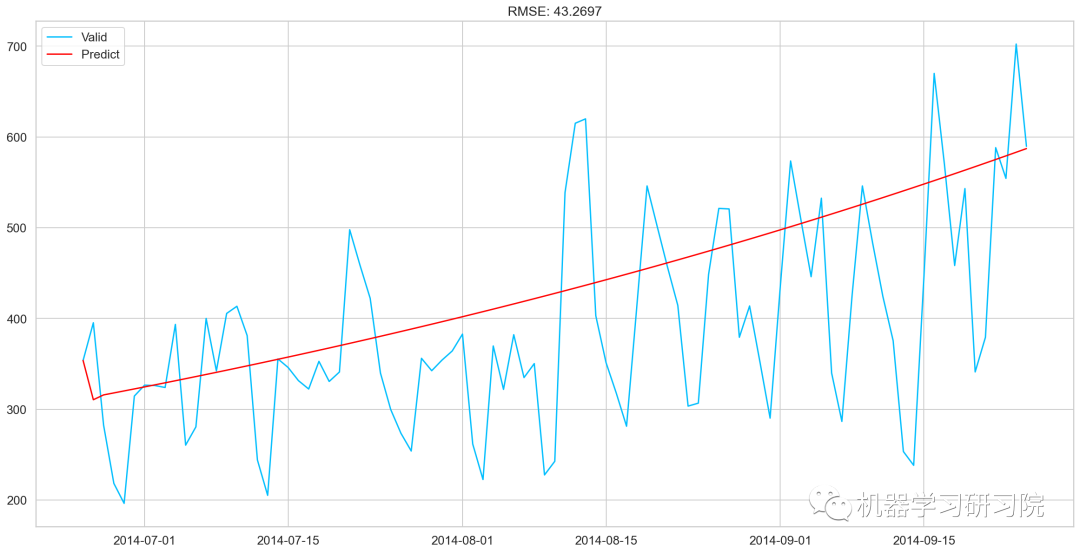
ARIMA_predict_diff=results_ARIMA.predict(start="2014-06-25",
end="2014-09-25")
check_prediction_diff(ARIMA_predict_diff, valid)
SARIMAX模型
y_hat_avg = valid.copy()
fit1 = sm.tsa.statespace.SARIMAX(Train.Count, order=(2, 1, 4),seasonal_order=(0,1,1,7)).fit()
y_hat_avg['SARIMA'] = fit1.predict(start="2014-6-25", end="2014-9-25", dynamic=True)
plt.plot( Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['SARIMA'], label='SARIMA')
模型评价
rms = sqrt(mean_squared_error(valid.Count, y_hat_avg.SARIMA))
print(rms)
70.26240839723575
预测
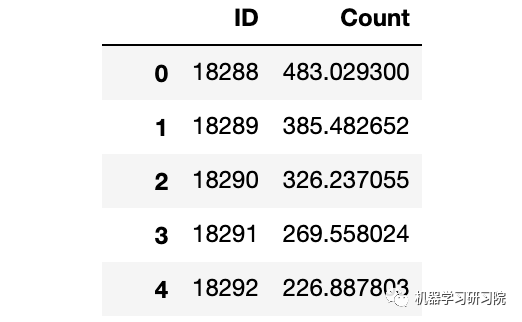
predict=fit1.predict(start="2014-9-26", end="2015-4-26", dynamic=True)
test['prediction']=predict
# 按日、月、年合并Test和test_original
merge=pd.merge(test, test_org, on=('day','Month', 'Year'), how='left')
merge['Hour']=merge['Hour_y']
merge=merge.drop(['Year', 'Month', 'Datetime','Hour_x','Hour_y'], axis=1
# 通过合并merge和temp2进行预测
prediction=pd.merge(merge, temp2, on='Hour', how='left')
# 将比率转换成原始比例
prediction['Count']=prediction['prediction']*prediction['ratio']*24
prediction['ID']=prediction['ID_y']
submission=prediction.drop(['day','Hour','ratio','prediction', 'ID_x', 'ID_y'],axis=1)
# 转换最终提交的csv格式
pd.DataFrame(submission, columns=['ID','Count']).to_csv('SARIMAX.csv')
参考资料
实际序列预测方法: https://blog.csdn.net/WHYbeHERE/article/details/109732168
往期精彩回顾 本站qq群955171419,加入微信群请扫码: