
【算法基础】十大经典排序算法(动图)
算法分类
冒泡排序(重点)
选择排序
插入排序
归并排序(重点)
快速排序(重点)
堆排序(重点)
计数排序
基数排序
文末有学习资料免费分享~
算法分类
十种常见排序算法可以分为两大类:
比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
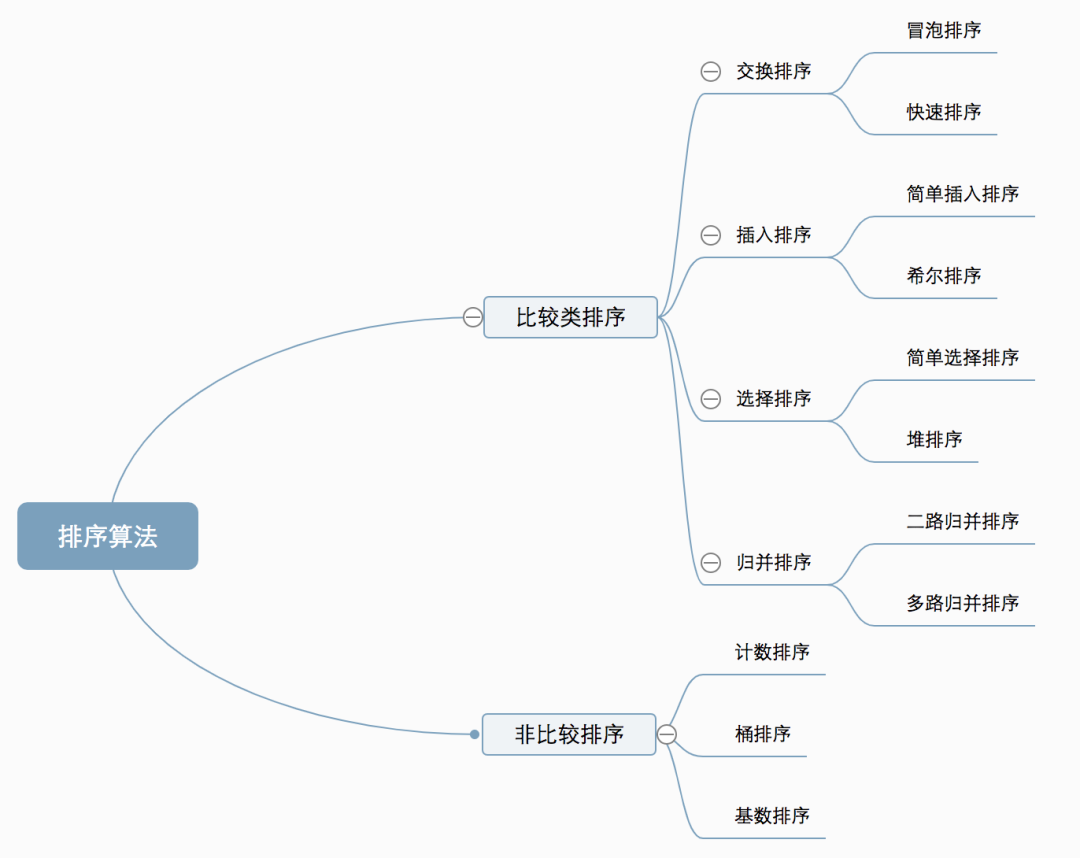
【算法复杂度】
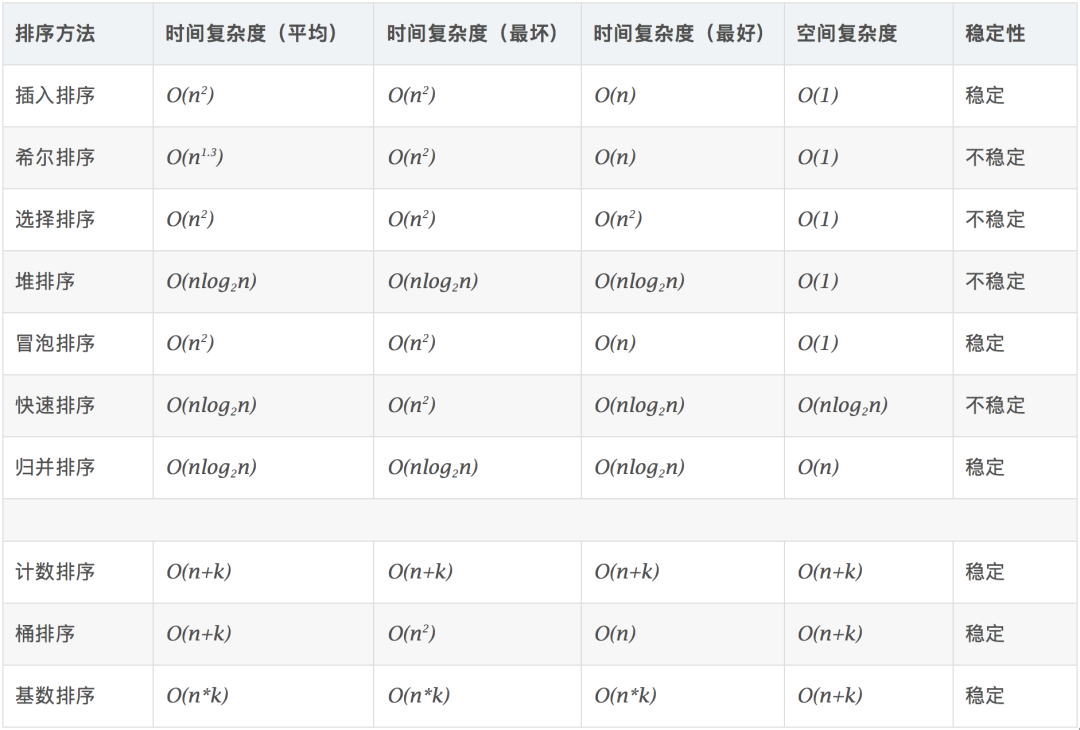
【相关概念】
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。 **空间复杂度:**是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
冒泡排序(重点)
Bubble Sort
【算法描述】
比较相邻的元素。如果第一个比第二个大,就交换它们两个; 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数; 针对所有的元素重复以上的步骤,除了最后一个; 重复步骤1~3,直到排序完成。
【动图演示】
选择排序
Selection Sort 表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。【算法描述】
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
【动图演示】
插入排序
Insertion Sort
【算法描述】
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
从第一个元素开始,该元素可以认为已经被排序; 取出下一个元素,在已经排序的元素序列中从后向前扫描; 如果该元素(已排序)大于新元素,将该元素移到下一位置; 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置; 将新元素插入到该位置后; 重复步骤2~5。
【动图演示】
归并排序(重点)
Merge Sort 归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。 是递归的思想 归并排序是一种稳定的排序方法。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。【算法描述】 把长度为n的输入序列分成两个长度为n/2的子序列; 对这两个子序列分别采用归并排序; 将两个排序好的子序列合并成一个最终的排序序列。
【动图演示】
快速排序(重点)
Quite Sort 快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 之前一直以为快排和二分法有关,但是其实是分治法的应用。
【算法描述】
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
从数列中挑出一个元素,称为 “基准”(pivot); 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作; 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
【动图演示】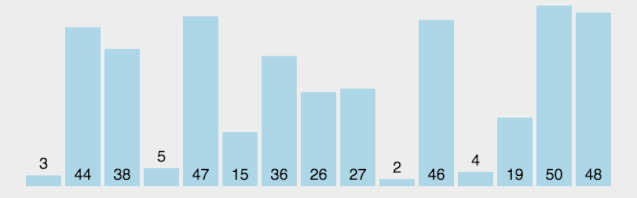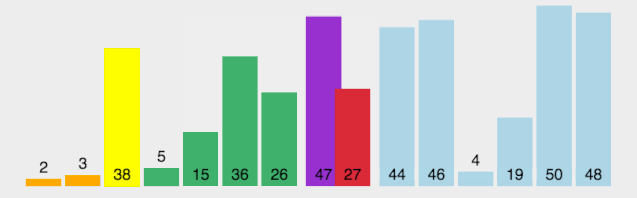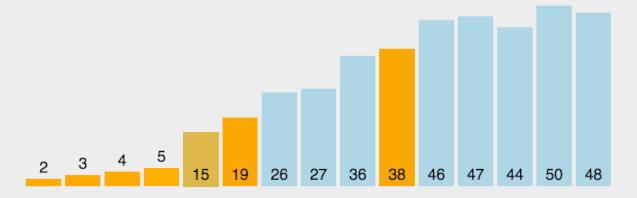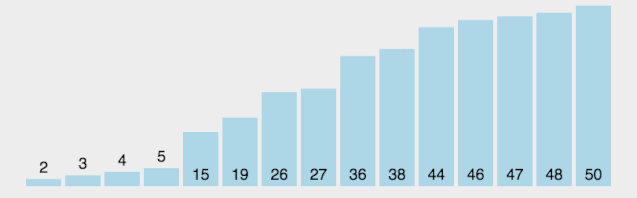
堆排序(重点)
python中sort排序的方法就是堆排序 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
【算法描述】
这个比较复杂。先看动图然后慢慢细说。
【动图演示】
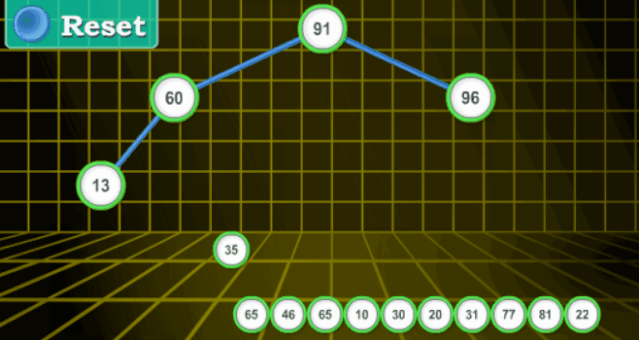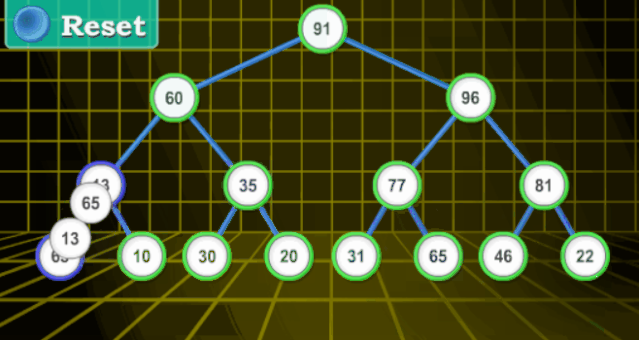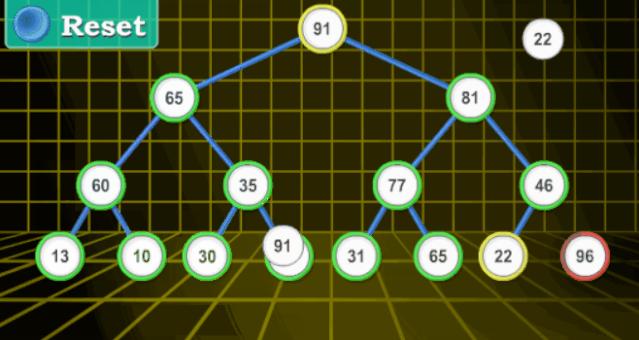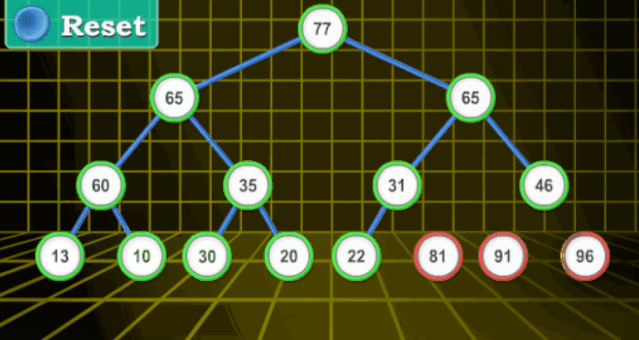
【分步详解】
堆(二叉堆)可以视为一棵完全的二叉树。完全二叉树的一个优秀的性质就是,除了最底层之外,每一层都是满的
二叉堆一般分为两种:最大堆和最小堆。
最大堆 :最大堆中的最大元素在根结点(堆顶);堆中每个父节点的元素值都大于等于其子结点(如果子节点存在)
最小堆:最小堆中的最小元素出现在根结点(堆顶);堆中每个父节点的元素值都小于等于其子结点(如果子节点存在)
假设我们要对目标数组A {57, 40, 38, 11, 13, 34, 48, 75, 6, 19, 9, 7}进行堆排序。
首先第一步和第二步,创建堆,这里我们用最大堆;创建过程中,保证调整堆的特性。从最后一个分支的节点开始进行调整为最大堆。
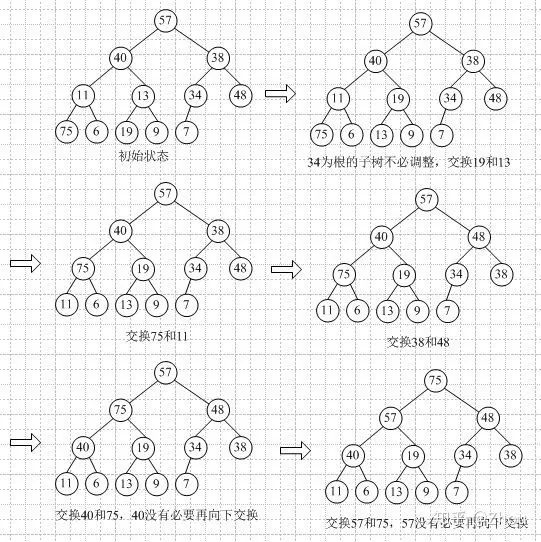
现在得到的最大堆的存储结构如下:
接着,最后一步,堆排序,进行(n-1)次循环。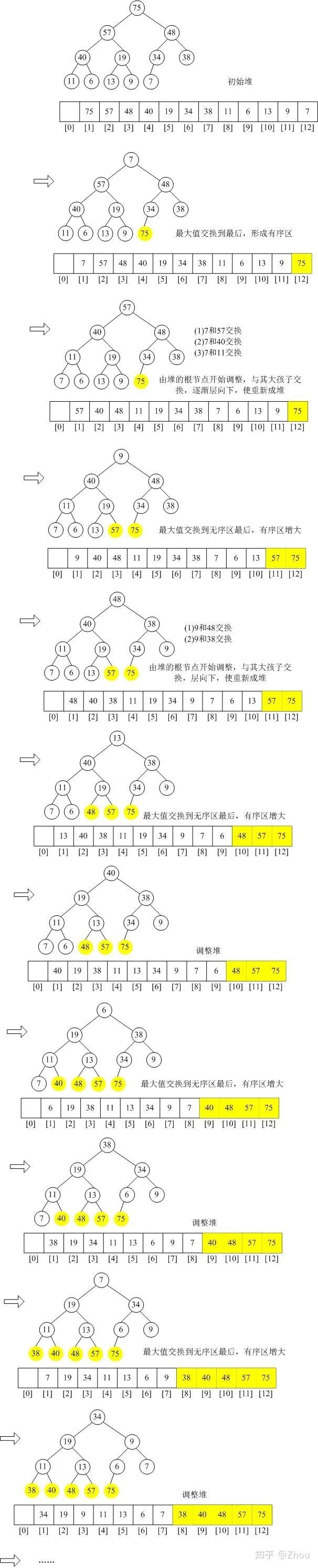
这个迭代持续直至最后一个元素即完成堆排序步骤。
【个人理解】
通过堆这个结构,让随机两个数组进行比大小,然后让获胜者之间再比大小,这样就可以通过复杂都logn得到一个最大的数字。然后不考虑这个数字,在剩下的数字中重复这个过程。有点类似比赛半决赛,四分之一决赛,八强这样的感觉。
计数排序
Counting Sort 计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。敲黑板!计数排序不是基于比较的,所以是线性时间复杂度,但是速度快的代价就是对输入数据有限制要求:确定范围的整数
【算法描述】
这部分不怎么用看,直接看动图就理解了
找出待排序的数组中最大和最小的元素; 统计数组中每个值为i的元素出现的次数,存入数组C的第i项; 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加); 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
【动图演示】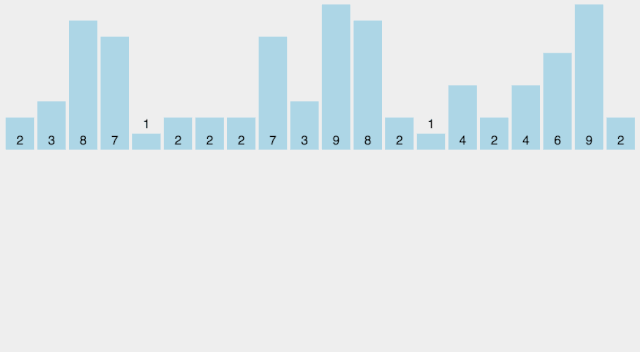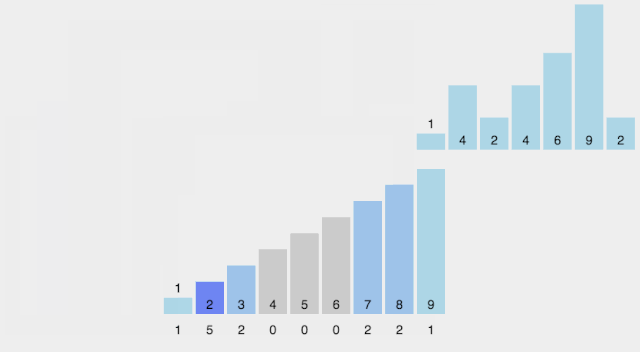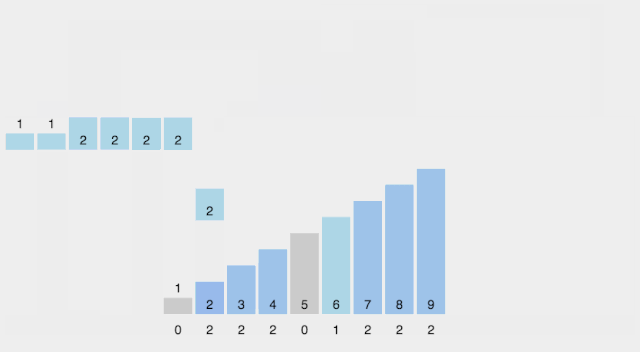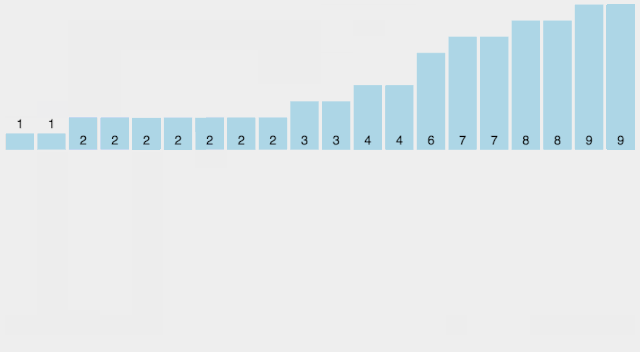
基数排序
Radix Sort 基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。**有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。**最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
【算法描述】
取得数组中的最大数,并取得位数; arr为原始数组,从最低位开始取每个位组成radix数组; 对radix进行计数排序(利用计数排序适用于小范围数的特点);
【动图演示】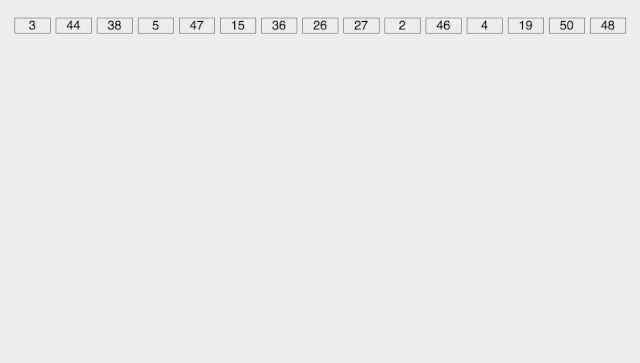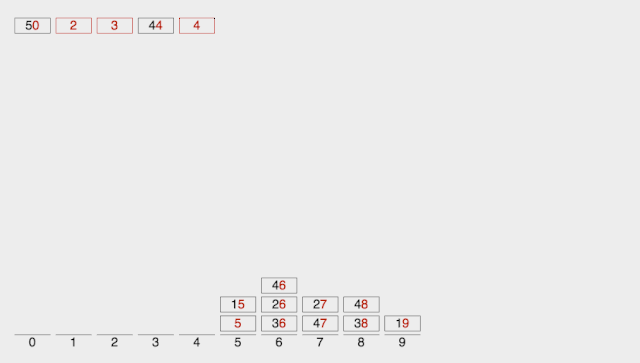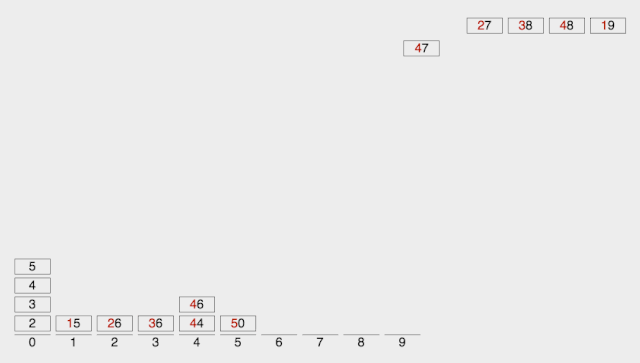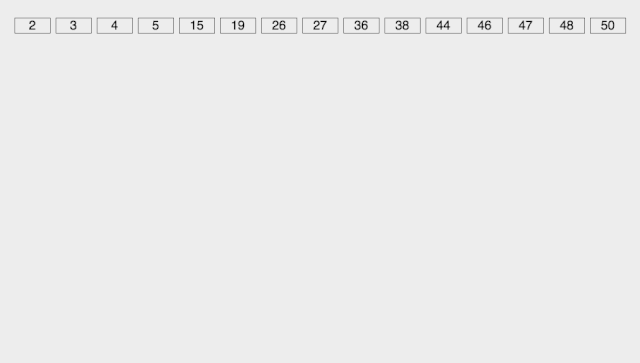
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群: