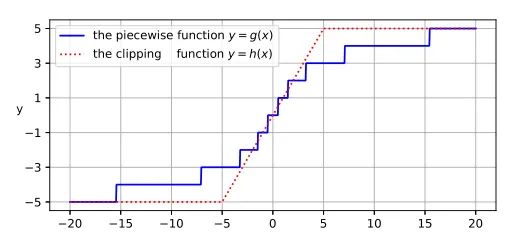
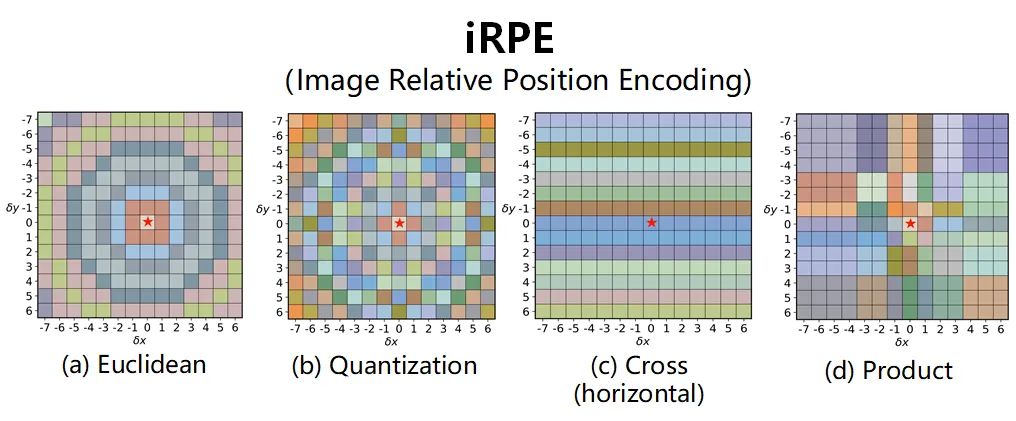
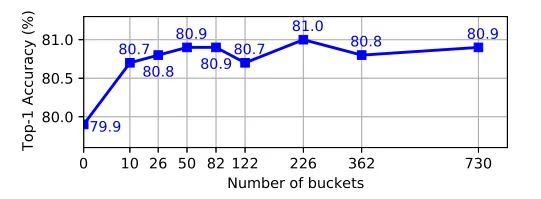
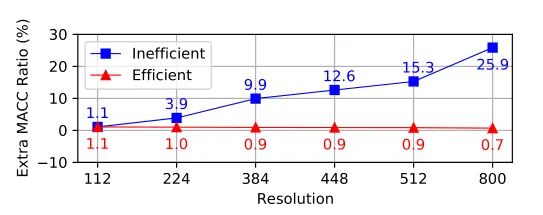
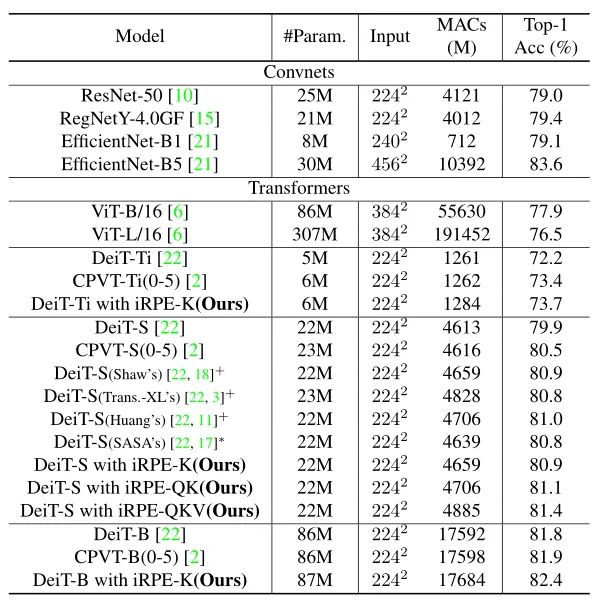
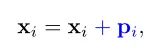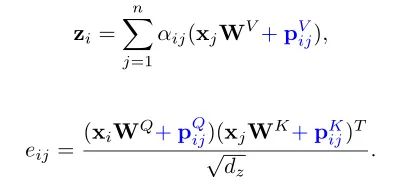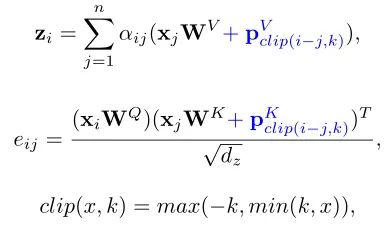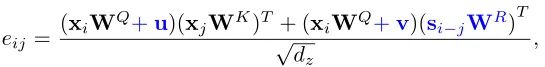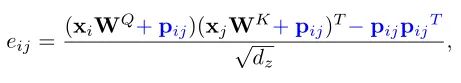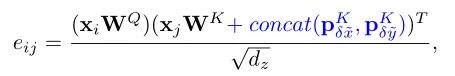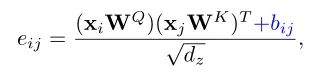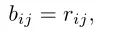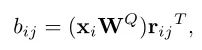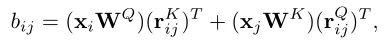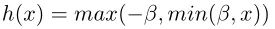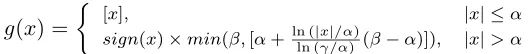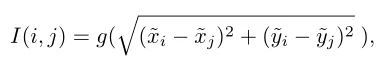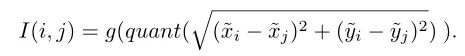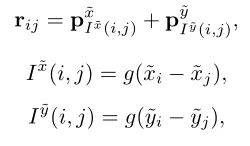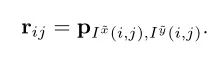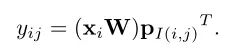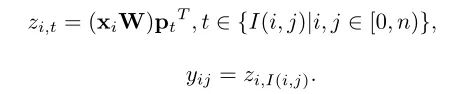由于Transformer对于序列数据进行并行操作,所以序列的位置信息就被忽略了。因此,相对位置编码(Relative position encoding, RPE)是Transformer获取输入序列位置信息的重要方法,RPE在自然语言处理任务中已被广泛使用。但是,在计算机视觉任务中,相对位置编码的有效性还没有得到很好的研究,甚至还存在争议。因此,作者在本文中先回顾了现有的相对位置编码方法,并分析了它们在视觉Transformer中应用的优缺点。接着,作者提出了新的用于二维图像的相对位置编码方法(iRPE)。iRPE考虑了方向,相对距离,Query的相互作用,以及Self-Attention机制中相对位置embedding。作为一个即插即用的模块,本文提出的iREP是简单并且轻量级的。实验表明,通过使用iRPE,DeiT和DETR在ImageNet和COCO上,与原始版本相比,分别获得了1.5%(top-1 Acc)和1.3%(mAP)的性能提升(无需任何调参)。
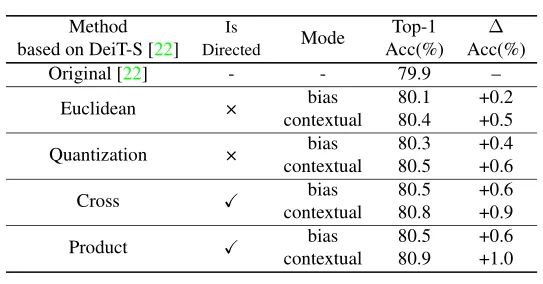
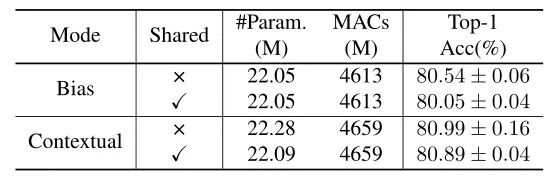
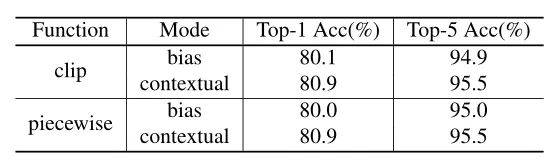
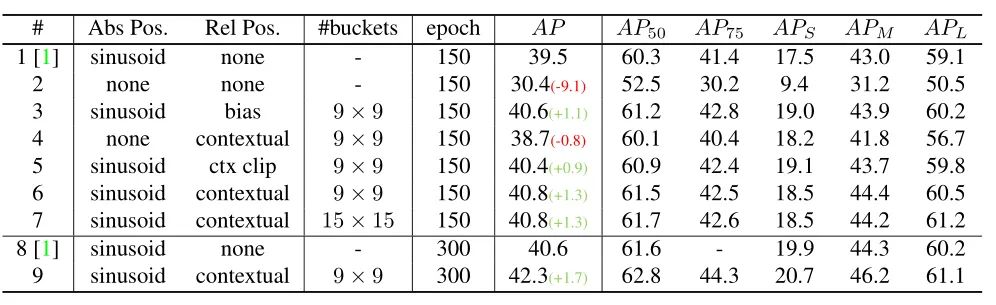
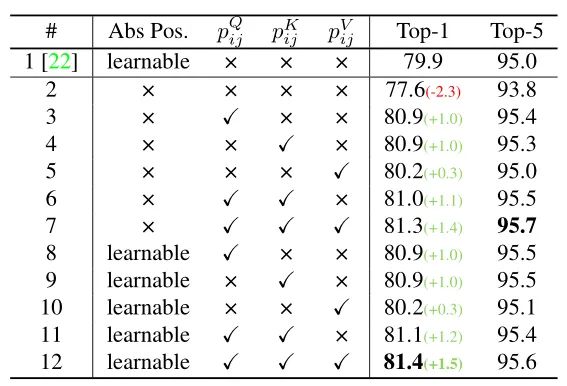
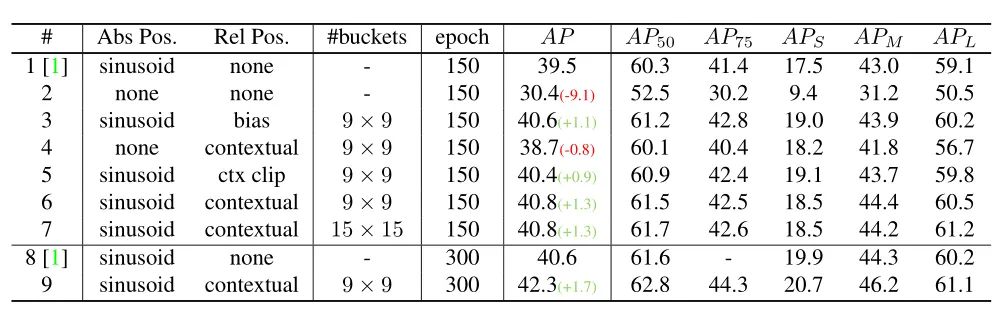
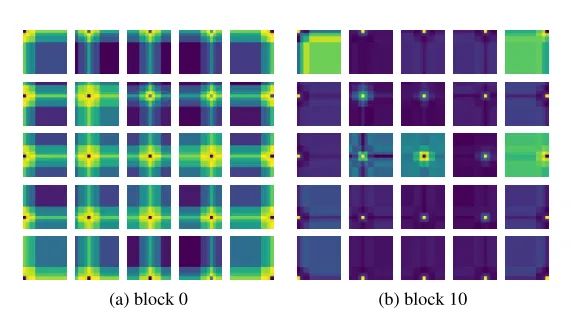
本文作者回顾了现有的相对位置编码方法,并提出了四种专门用于视觉Transformer的方法。作者通过实验证明了通过加入相对位置编码,与baseline模型相比,在检测和分类任务上都有比较大的性能提升。此外,作者通过对不同位置编码方式的比较和分析,得出了下面几个结论:1)相对位置编码可以在不同的head之间参数共享,能够在contextual模式下实现与非共享相当的性能。2)在图像分类任务中,相对位置编码可以代替绝对位置编码。然而,绝对位置编码对于目标检测任务是必须的,它需要用绝对位置编码来预测目标的位置。3)相对位置编码应考虑位置方向性,这对于二维图像是非常重要的。4)相对位置编码迫使浅层的layer更加关注局部的patch。 参考文献[1]. Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. ACL, 2018. [2]. Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell,Quoc Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. In ACL,2019. [3]. Zhiheng Huang, Davis Liang, Peng Xu, and Bing Xiang. Improve transformer models with better relative position embeddings. In EMNLP, 2020 [4]. Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jonathon Shlens. Standalone self-attention in vision models. arXiv preprint arXiv:1906.05909, 2019.