
高效学习,我的最佳实践
最近奥运会,中国还是依然 NB,尤其前两天的男子百米半决赛、决赛,彻底被苏神点燃了。
说是亚洲奇迹,一点也不为过。
看比赛,有好的,也有气人的,比如裁判,裁判适当照顾东道主也能忍了,但是有时候太过分了,直接选择性眼瞎。 说到选择性眼瞎,我想的一个事情。
说到选择性眼瞎,我想的一个事情。
咱们干程序员的,经常需要应用、研究一些开源组件。研究开源组件,就少不了去看资料、看源代码。在看代码、学习的过程中,咱们可不能像那些眼瞎的裁判,咱们需要高效的学习:看清全局、主要脉络、关键细节。
这篇文章就和大家说说我自己高效学习的方法。
对我而言,做好这件事的关键就在于问自己七个问题。
问题1. 组件解决了什么问题
问这个问题的目的是明确组件的问题域,任何组件的出现都是为了解决某类问题的。
我们在职业生涯里,遇到的技术问题其实是有限的。面对这些有限的问题,我们熟悉的组件越多,解决问题的思路和办法就越多。当你对某种技术问题,有着比别人更多的思路和办法,那自然而然,你的技术话语权就会越大。
以我曾经深入研究过的 druid(阿里的开源数据库连接池)组件为例:
druid 要解决的问题本质其实是如何降低应用和中间件交互所消耗的时间成本。
知道了 druid 要解决的问题,我们就等于知道了它的核心主题。druid 的主要技术思路,全部都是围绕着这个核心主题来实现的。
比如,druid 本身的 LRU 策略、对一些关键对象的缓存、竞争资源的高效率利用……都是围绕着这个核心问题来设计和落地的。
同时,我们明确了 druid 要解决的问题后,如果我们对现在 jedis 这套东西不满意,是不是就可以利用 druid 的技术思路,重新设计和实现一套新组件,去替代 jedis,以便降低和 redis 交互的时间成本呢?
问题2. 组件有什么优点
确认了组件需要解决的问题,只是第一步。一套开源组件,往往项目都比较庞大。所以,就得想个办法分而克之,分出各个具体的知识点去学习。
而这些知识点,往往和官方文档宣传的组件优点可以对上。
比如,druid 的官方文档是这么说的: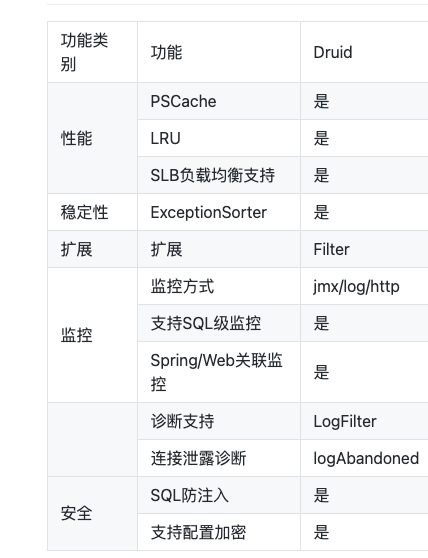 从上面这幅图,就可以看出来,druid 有如下几个特点:
从上面这幅图,就可以看出来,druid 有如下几个特点:
能被监控 容易扩展 性能优秀 稳定性好 安全 运行期问题容易排查
这些就是我们要去学习的各个知识点。
问题3. 组件的主干和分支都是哪些
知道了组件的优点,就等同于知道了需要学习的知识点。可是,知识点如果多而杂,就需要确认好哪些学哪些不学?哪些先学哪些后学?
那么,组件的主干和分支就需要分解出来,以便定出学习计划。而划分出主干和分支,就需要综合我们前面说的组件要解决的问题。
通过前面的学习,我们知道 druid 解决的是降低中间件的时间成本,也知道了它的特点:
能被监控 容易扩展 性能优秀 稳定性好 安全 运行期问题容易排查
此时,我们的学习计划就是:先学习 druid 是如何实现高性能的;高性能后,如果我们研究 druid 是为了后续在工作中应用,那么,能被监控这个特点就是下一个要学习的知识点。
所以,这一问,是为了拟定学习计划而问。
问题4. 组件的这些优点是如何实现的
在上个问题之后,我们就可以分步骤的进行学习了。学的怎么样,就需要通过这个问题,来考察自己是否真的学懂了这些知识点。
回到 druid 上,让人满意的答案就是,我们能用自己的话去总结出每个知识点的技术实现。比如:
“问:druid 的监控是如何实现的?
”
答:druid 通过自己实现 JDBC API 自身提供的 PooledConnection、Connection、Statement、ResultSet接口,获得了可以在这些接口的关键方法中植入统计的能力。统计的数据会定期采样后存储在某些命名叫做 xxxStat 的对象里,供后面展示使用。
“问:druid 是如何实现扩展的?
”
答:能扩展的实现方式是第三方实现 druid 提供的一个 Filter 接口后,再被配置到 druid 的配置文件里。这样就会在 DruidDataSource 初始化的时候,去读取并初始化这些实现了 Filter 接口的实例。初始化后的 Filter 会在后面 druid 从创建数据库连接到执行 SQL 语句再到释放连接这一系列步骤后,被不断的链式执行。
就这样,分知识点回答出让自己满意的答案,就等同于考核了自己对每个知识点学习的质量,如果回答不满意,就再去查漏补缺即可。
问题5. 组件的系统设计思路是什么
我们学习了各个零散的知识点之后并不够,因为学习一套开源组件,原理是基础,系统设计则是骨架。
明白了技术点,只是对当编码高手有用,但是当你自己设计组件的时候,你的底气在哪里呢?答案就在这些你看过的开源组件的系统设计思路上。
所以,把知识点融合起来形成一个整体,再去推断出系统的设计思路,对我们成为一名优秀的架构师,是有非常大的帮助的。
比如,通过各个知识点的深入学习,融会贯通后,我认为 druid 的设计思路如下: 如果以后遇到为公司底层构造一套池化中间件对象的需求时,这种设计思路自然就成了我设计的重要模板之一。
如果以后遇到为公司底层构造一套池化中间件对象的需求时,这种设计思路自然就成了我设计的重要模板之一。
问题6. 组件的缺点是什么
为什么会问组件的缺点?因为在我如此了解了一套组件之后,却还是免不了误用和踩坑,这其中最严重的就是,生产环境在组件出现问题之后,我们却没有紧急预案。
这种现象的原因就是没有去深入思考过一套技术的利弊。问组件的缺点,就会迫使我们去深入思考利弊,从而在以后不管是应用组件,又或者是去根据学习到的知识自己实践,都能成竹在胸,从容以对。
回到 druid 身上,当我们去读它源码的时候,思考一下:
durid 的这些实现真的就是完美的吗?
那肯定不是, 比如:
druid 的采样功能很多时候我们并不需要,但是由于 druid 的实现是写死在实现的关键代码里的,所以无法自由的对其进行插拔。这时候,就要注意,采样可能造成的内存占用问题。
druid 是对 JDBC API 做了层层封装的,在这些封装中 druid 又添加了很多自己的实现。但是,这些实现很难避免bug,然而由于有这些封装,就会导致 Bug 很难查,又或者很难自己改。这时候,就需要在测试环境,把 druid 的日志级别调成 DEBUG 级别,然后仔细观察日志,看看是否有什么不可知的风险。
所以,这一问,是为了深度思考,让我们在任何新技术的学习和实战时,都能成为最稳定的那个仔。
不管以后我们模仿还是应用 druid,就能提前预测到风险,从而重点监控,提前准备预案。
问题7. 和同类别的组件之间有什么区别
当学习完了组件,知道了组件的优缺点,理解了组件的运行原理,明白了组件的设计思路之后,一切就完整了吗?
对不起,还不够。
因为我们还缺乏一种东西,就是学习的拓展,即学习的广度。
学习组件,我们除了知道它要解决的问题域外,还需要知道它在同类组件中的地位。
为什么?因为以后我们去任何一个稍微成规模的公司后,需要面临一个问题,内部的竞争。
比如,我们写了一套消息治理中间件。如果想提升自己的技术话语权,就需要在全公司,和同类产品竞争。竞争胜出了,自己的职业生涯就有了巨大发展的可能。
回到 druid 上,在SpringBoot2.0时代,druid 出现了巨大的竞争对手——HiKariCP。
而 HiKariCP 之所以能胜出,是因为它排除了 druid 使用的公平锁,使得性能提升了大约 70%。
通过 druid 和 HiKariCP 的比较和学习,我们就能更加深入的理解高并发,能更有效率的去压榨出系统的性能。
通过 druid 和 HiKariCP 作者之间的互相较量,我们还能明白如何去更好的对比竞品,去展现最为关键的数据指标,一举赢得胜利。
以上列举的七个问题,是我为了解决高效高质研究开源组件,得到的最佳实践。
总结一下:
先通过问组件解决了什么问题,去确定自己的学习目的和思考边界。 再问组件有什么优点,以及主干和分支是哪些,去拟定出学习计划。 再后,通过问组件的优点是如何实现的,去考察自己的学习质量。 然后,通过问组件的系统设计思路是什么,让自己讲学到的各种独立的知识融汇贯通,打造成体系。 最后,通过问组件的缺点是什么以及和竞品的区别去迫使自己在学习之外,再行深度思考和广度思考,对学习进行查漏补缺以及进一步提升学习质量,打造出更为突出的知识体系。
IT这行业是需要不断学习的,而高效高质量学习,是让我们的职业生涯走的更稳更顺的关键所在。
希望这篇文章对大家有帮助,看完如果觉得有收获,请帮忙转发、随手点个在看,你的支持对我很重要。
你好,我是四猿外。
一家上市公司的技术总监,管理的技术团队一百余人。
我从一名非计算机专业的毕业生,转行到程序员,一路打拼,一路成长。
我会通过公众号,
把自己的成长故事写成文章,
把枯燥的技术文章写成故事。
我建了一个读者交流群,里面大部分是程序员,一起聊技术、工作、八卦。欢迎加我微信,拉你入群。
推荐阅读