决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost总结

一. 决策树
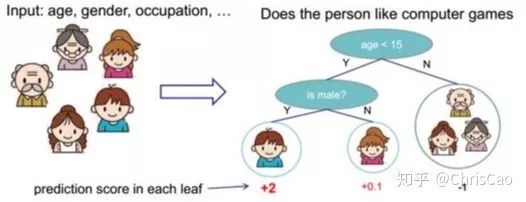
1.ID3算法:以信息增益为准则来选择最优划分属性
 信息熵越小,数据集
信息熵越小,数据集  的纯度越大
的纯度越大 上建立决策树,数据有
上建立决策树,数据有  个类别:
个类别:
 表示第K类样本的总数占数据集D样本总数的比例。
表示第K类样本的总数占数据集D样本总数的比例。 ,
, 
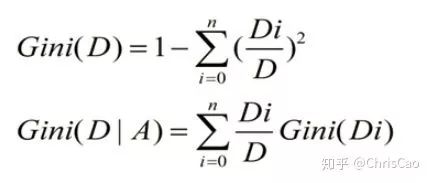
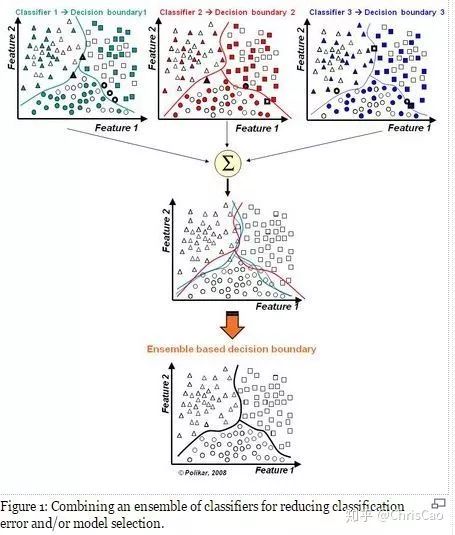
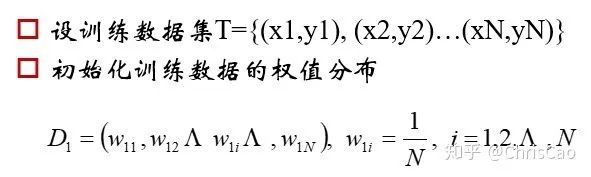

 计算的是当前数据下,模型的分类误差率,模型的系数值是基于分类误差率的
计算的是当前数据下,模型的分类误差率,模型的系数值是基于分类误差率的

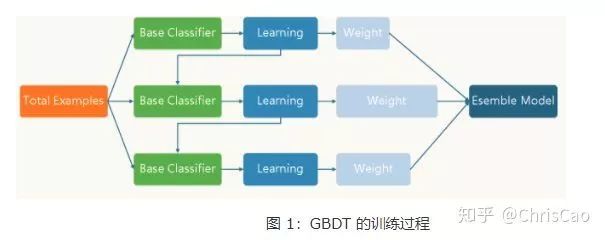



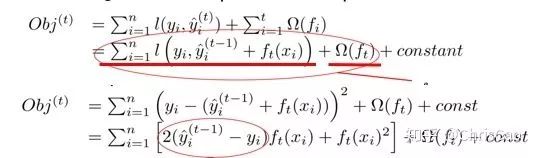
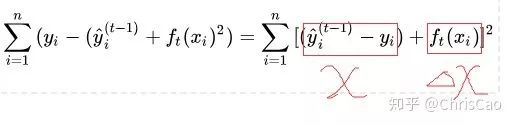

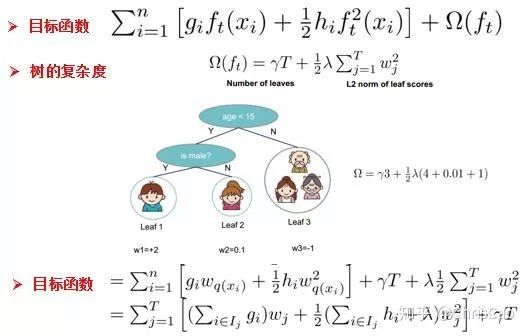
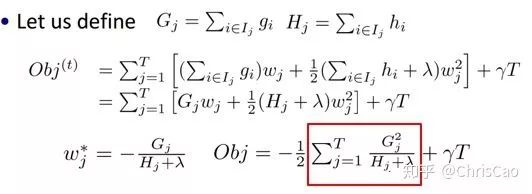

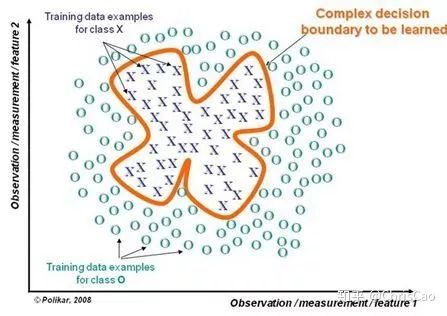
point的候选,遍历所有的候选分裂点来找到最佳分裂点。
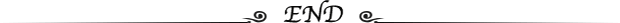
相关阅读:
评论
 下载APP
下载APP一. 决策树
1.ID3算法:以信息增益为准则来选择最优划分属性
信息熵越小,数据集 的纯度越大 上建立决策树,数据有 个类别: 表示第K类样本的总数占数据集D样本总数的比例。 , 计算的是当前数据下,模型的分类误差率,模型的系数值是基于分类误差率的
相关阅读: