
我拿乐谱训了个语言模型!

新智元报道
新智元报道
来源:夕小瑶的卖萌屋
作者:花椒
【新智元导读】都说学习音乐可以让大脑更加聪明。难道语言模型也一样?从音乐中获得了“灵感”,变“聪明”了? 请带着脑洞继续往下读。
最近在刷EMNLP论文的时候发现一篇非常有趣的论文《Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models》,来自斯坦福大学NLP组。
论文有趣的发现是让语言模型先在乐谱上进行训练,再在自然语言上训练可以有效的提升语言模型的性能。在看了一大堆BERT-based的模型后,看到这篇文章时便觉得眼前一亮。
论文题目:
Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.554.pdf
Github:https://github.com/toizzy/tilt-transfer
本文的主要假设是对于有结构性的语言,比如乐谱和代码,他们的潜在结构能被神经网络所编码,且有助于自然语言的学习。
在此假设上,本文主要研究问题是:
当存在两种语言L1和L2时, 语言模型可以在多大程度上学习并迁移L1中的潜在结构到L2中,以帮助L2的学习?
文中对于语言的定义是比较宽泛的,包括我们日常用的自然语言,音乐,代码等。因为每一种语言有着不同的潜在结构,为探究不同L1对L2的影响,本文主要围绕3个方面对L1发问:
当L1是non-linguistic语言时(比如music, Java code),语言模型是否可以学习其潜在结构,并迁移到自然语言中? 是否是L1中的递归结构对语言模型的学习和迁移有帮助? 当L1是与L2不同的自然语言时,语言模型是否可以学习并迁移其中的句法结构?
为了回答这3个问题,作者提出了一种叫做TILT (Test for Inductive Bias via Language Model Transfer)的测试方法。
核心思想是,先用L1语言预训练一个LSTM语言模型,然后固定其参数,直接在L2语言上测试其困惑度。
通过改变L1固定L2,来对比不同潜在结构对于自然语言学习的影响。结合文中的流程图更好理解(如下):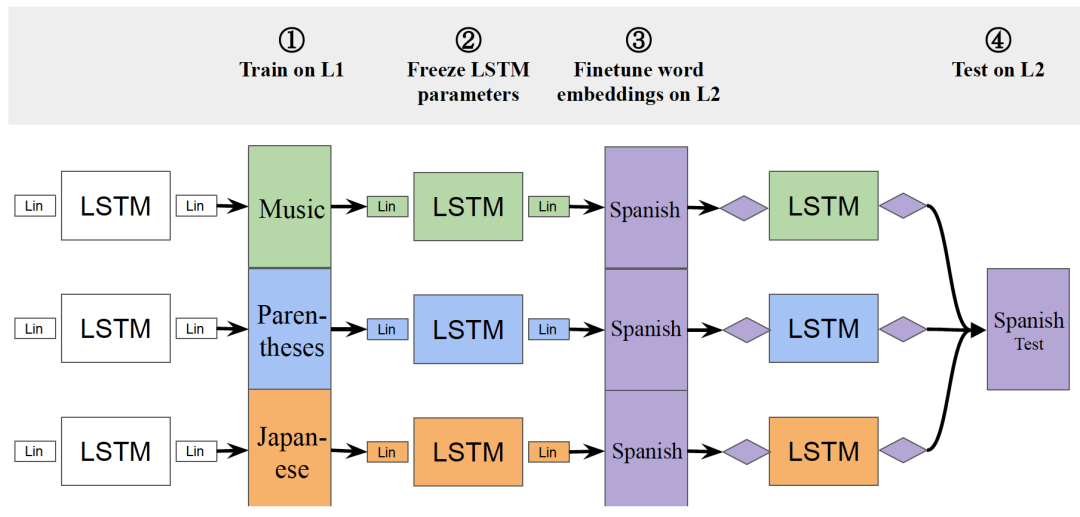
看图说话:
Q1: 怎么用语言模型训练Music数据呢?
A1: 关键是将乐谱转换为线性序列。文中使用了MAESTRO数据集,包含了172个小时的经典的钢琴演奏曲。
该数据集采用MIDI格式的音乐数据,每个MIDI文件,对应一个序列的音符的标注信息。
因此一首曲子就可转换一个线性的序列,这样子乐谱就可以愉快的和LSTM玩耍了~ 比如对于下面的mid文件[1]:(哈哈,点不了哦~)
会被标注为音符"3/4 c4 d8 f g16 a g f#", 然后传递给模型。

Q2: 为什么②中LSTM的参数是固定的呢?
A2: 这是为了保留使用不同L1训练时所捕捉的潜在结构呀~固定LSTM的参数可以防止L2的自身结构信息被编码。
因为最终是在同一个L2上进行测试的,所以可以公平比较使用不同L1进行预训练对L2测试结果的影响啦。
文中一个核心的观点是将不同L1中的潜在结构当成inductive bias, 并探究其是否可以被语言模型捕捉并迁移到L2上。
Q3: 乐谱的词表和西班牙语的词表都不一样,我要怎么在西语上测试呢?
A3: 这还不简单,在测试前,使用西语语料对embedding层进行fine-tune就可以了嘛(上图③的功能)。
乐谱到底有没有用呢?
有没有用,还得看怎么对比了~哈哈~先看看文中使用了4组不同的L1语言的例子:
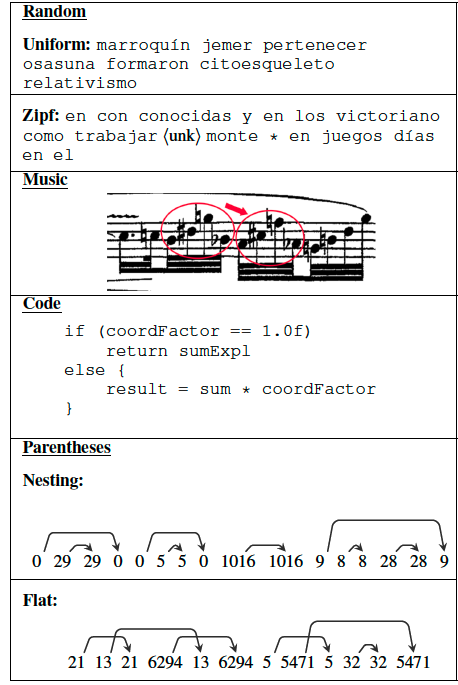
那他们各自的实验结果如何呢?
首先来个直观的对比(横轴是不同的L1语言预训练,纵轴是在L2上测试的结果)。
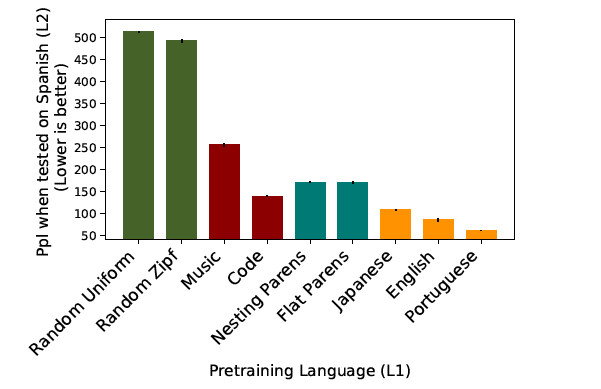
music所在一列就是使用乐谱训练的结果啦。与左边的baseline相比,提升十分显著,困惑度几乎降低了一半。
最左边两个草绿色的baseline,是在西语上随机采样的词汇语料(没有任何结构信
息)预训练得到的结果。但是music的效果并不如Jave code以及别的自然语言(橙
色)。
为了探究到底是music和Java code中的什么潜在结构提升了L2的性能呢?作者猜测会不会是其中的层级递归结构呢?
但是在music和code上又不好直接验证。于是有了第三组实验来探究层级递归结构
对L2的影响。
作者伪造了两个括号数据(配对的整数数据),一个具有层级递归结构(Nesting
parents),一个没有递归结构但是有配对的标记对的信息(Flat Parens)。
可以看到他们俩给L2带来的性能提升几乎持平。那这是不是说明层级递归对L2没有
多大用呢?
是的,至少这篇文中的实验室设置下是的。但是作者说这也说明标记对的匹配预训
练LSTM语言模型是有帮助的,他们甚至表现比用music的还好,你说神奇不神奇。
第四组实验使用不同的自然语言数据进行预训练,可以看到他们的性能其实还是远远高于non-linguistic data的。
同时也可以看到,日语、英语、葡萄牙语对于西语的帮助差别也是比较大的, 那这
又是为什么呢?
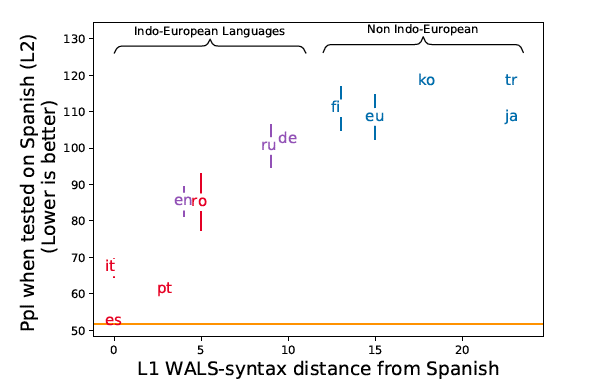
作者认为是句法结构类型的差异性所导致的。因此为了探究不同自然语言L1对L2的
影响,作者使用句法特征,将每种语言转化为句法特征向量,从而计算各个语言之
间的WALS-syntax distance,即下图中的横轴。
然后对比用不同语言预训练后在西语上测试得到的ppl,下图纵轴。图中可以明显看
到句法距离越相小的语言之间的句法结构迁移的效果更好。
最后,还有个好奇的点。虽然文中的实验结果证明代码或者乐谱中的潜在对于LSTM语言模型的预训练是有帮助的,但是他们的帮助还是没有在自然语言(英语,意大利语)带来的收益大,那么如果我们用sequencial的pre-training 或者组合在每个L1上训练的语言模型会给L2带来更大的提升吗??
总结
论文读完啦,咱们回答下开头的问题:
Non-linguistic数据中的潜在结构对于L2的学习有帮助嘛?有帮助,但没有不同自然语言L1带来的收益大。不过虽然music的帮助是所有实验中的L1中最小的,不过本文对于不同模态语言的潜在结构的迁移的探索是个不错的方向。 递归结构对于L2学习影响大嘛?不大,但是标记之间的配对结构对L2影响比较大。 当L1是自然语言时,语言模型可以编码并迁移其中的句法结构嘛?可以,而且其与L2的句法距离越接近,句法结构的迁移性越好。
这是一篇故事讲得很好且文笔十分好的文章,感兴趣的小伙伴可以去读一读原文,感受一下作者清晰而自洽的论述过程,一步步发问,一步步深入,是一个非常享受的过程~

