
译文 | 通俗易懂的机器学习(1)
翻译:Ahong
原文:https://valyrics.vas3k.com/blog/machine_learning/
来源:转自dataxon公众号
机器学习好比高中时代的性——人人都在谈论,但除了老师们知根知底外,只有很少的人能说清楚怎么回事。如果阅读网上关于机器学习的文章,你很可能会遇到两种情况:充斥各种定理的厚重学术三部曲(我搞定半个定理都够呛),或是关于人工智能、数据科学魔法以及未来工作的天花乱坠的故事。

我决定写一篇酝酿已久的文章,对那些想了解机器学习的人做一个简单的介绍。不涉及高级原理,只用简单的语言来谈现实世界的问题和实际的解决方案。不管你是一名程序员还是管理者,都能看懂。
那我们开始吧!
为什么我们想要机器去学习?
现在出场的是Billy,Billy想买辆车,他想算出每月要存多少钱才付得起。浏览了网上的几十个广告之后,他了解到新车价格在2万美元左右,用过1年的二手车价格是1.9万美元,2年车就是1.8万美元,依此类推。
作为聪明的分析师,Billy发现一种规律:车的价格取决于车龄,每增加1年价格下降1000美元,但不会低于10000美元。
用机器学习的术语来说,Billy发明了“回归”(regression)——基于已知的历史数据预测了一个数值(价格)。当人们试图估算eBay上一部二手iPhone的合理价格或是计算一场烧烤聚会需要准备多少肋排时,他们一直在用类似Billy的方法——每人200g? 500?
是的,如果能有一个简单的公式来解决世界上所有的问题就好了——尤其是对于烧烤派对来说——不幸的是,这是不可能的。
让我们回到买车的情形,现在的问题是,除了车龄外,它们还有不同的生产日期、数十种配件、技术条件、季节性需求波动……天知道还有哪些隐藏因素……普通人Billy没法在计算价格的时候把这些数据都考虑进去,换我也同样搞不定。
人们又懒又笨——我们需要机器人来帮他们做数学。因此,这里我们采用计算机的方法——给机器提供一些数据,让它找出所有和价格有关的潜在规律。
终~于~见效啦。最令人兴奋的是,相比于真人在头脑中仔细分析所有的依赖因素,机器处理起来要好得多。
就这样,机器学习诞生了。
机器学习的3个组成部分
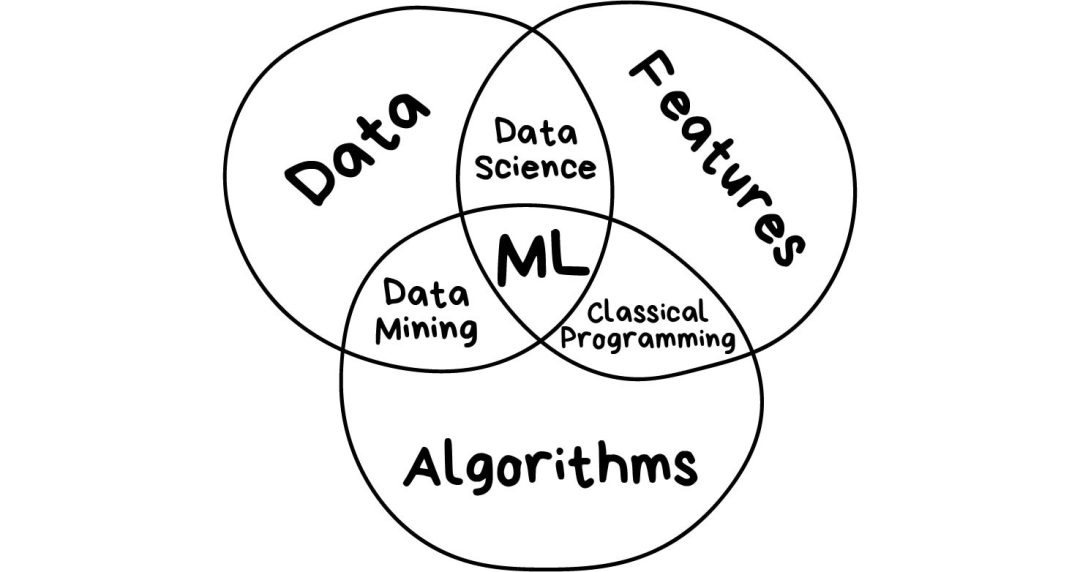
抛开所有和人工智能(AI)有关的扯淡成分,机器学习唯一的目标是基于输入的数据来预测结果,就这样。所有的机器学习任务都可以用这种方式来表示,否则从一开始它就不是个机器学习问题。
样本越是多样化,越容易找到相关联的模式以及预测出结果。因此,我们需要3个部分来训练机器:
数据
想检测垃圾邮件?获取垃圾信息的样本。想预测股票?找到历史价格信息。想找出用户偏好?分析他们在Facebook上的活动记录(不,Mark,停止收集数据~已经够了)。数据越多样化,结果越好。对于拼命运转的机器而言,至少也得几十万行数据才够吧。
获取数据有两种主要途径——手动或者自动。手动采集的数据混杂的错误少,但要耗费更多的时间——通常花费也更多。自动化的方法相对便宜,你可以搜集一切能找到的数据(但愿数据质量够好)。
一些像Google这样聪明的家伙利用自己的用户来为他们免费标注数据,还记得ReCaptcha(人机验证)强制你去“选择所有的路标”么?他们就是这样获取数据的,还是免费劳动!干得漂亮。如果我是他们,我会更频繁地展示这些验证图片,不过,等等……
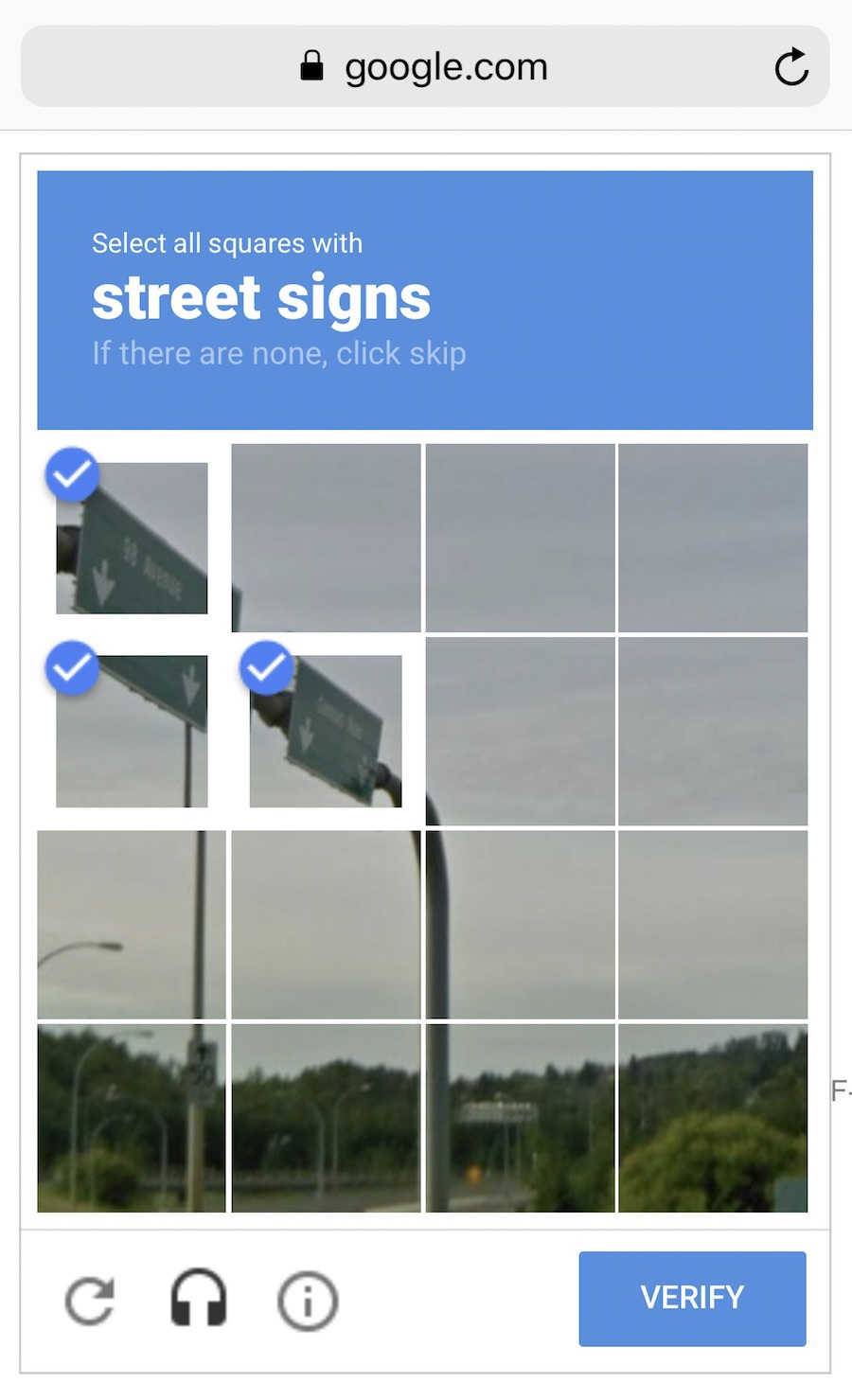
好的数据集真的很难获取,它们是如此重要,以至于有的公司甚至可能开放自己的算法,但很少公布数据集。
特征
也可以称为“参数”或者“变量”,比如汽车行驶公里数、用户性别、股票价格、文档中的词频等。换句话说,这些都是机器需要考虑的因素。
如果数据是以表格的形式存储,特征就对应着列名,这种情形比较简单。但如果是100GB的猫的图片呢?我们不能把每个像素都当做特征。这就是为什么选择适当的特征通常比机器学习的其他步骤花更多时间的原因,特征选择也是误差的主要来源。人性中的主观倾向,会让人去选择自己喜欢或者感觉“更重要”的特征——这是需要避免的。
算法
最显而易见的部分。任何问题都可以用不同的方式解决。你选择的方法会影响到最终模型的准确性、性能以及大小。需要注意一点:如果数据质量差,即使采用最好的算法也无济于事。这被称为“垃圾进,垃圾出”(garbae in - garbage out,GIGO)。所以,在把大量心思花到正确率之前,应该获取更多的数据。
学习 V.S. 智能
我曾经在一些流行媒体网站上看到一篇题为“神经网络是否会取代机器学习?”的文章。这些媒体人总是莫名其妙地把线性回归这样的技术夸大为“人工智能”,就差称之为“天网”了。下图展示了几个容易混淆的概念之间的关系。
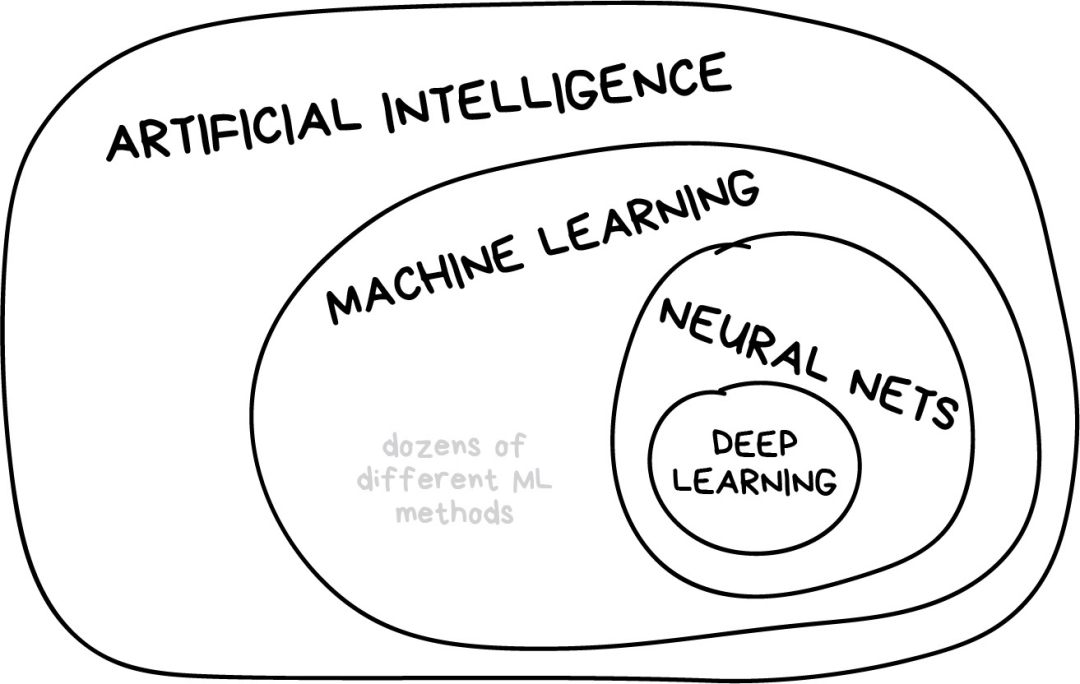
“人工智能”是整个学科的名称,类似于“生物学”或“化学”。 “机器学习”是“人工智能”的重要组成部分,但不是唯一的部分。 “神经网络”是机器学习的一种分支方法,这种方法很受欢迎,不过机器学习大家庭下还有其他分支。 “深度学习”是关于构建、训练和使用神经网络的一种现代方法。本质上来讲,它是一种新的架构。在当前实践中,没人会将深度学习和“普通网络”区分开来,使用它们时需要调用的库也相同。为了不让自己看起来像个傻瓜,你最好直接说具体网络类型,避免使用流行语。
一般原则是在同一水平上比较事物。这就是为什么“神经网络将取代机器学习”听起来就像“车轮将取代汽车”。亲爱的媒体们,这会折损一大截你们的声誉哦。
| 机器能 | 机器不能 |
|---|---|
| 预测 | 创造新事物 |
| 记忆 | 快速变聪明 |
| 复制 | 超出任务范围 |
| 选择最优项 | 消灭全人类 |
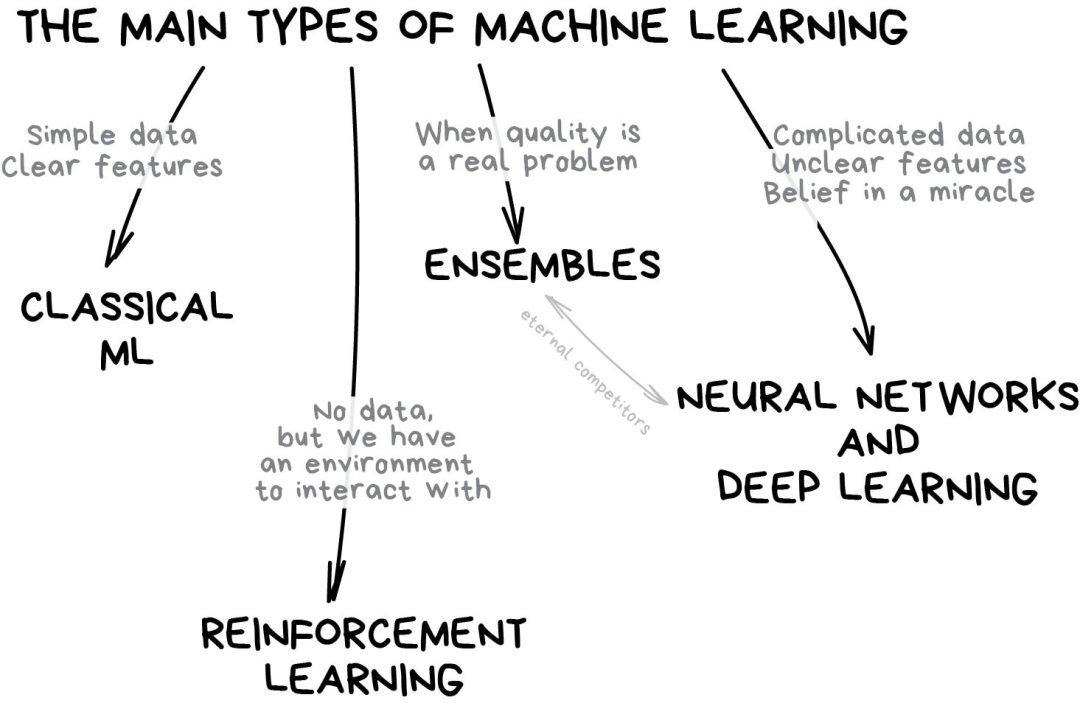
机器学习世界的版图
如果你懒得阅读大段文字,下面这张图有助于获得一些认识。

在机器学习的世界里,解决问题的方法从来不是唯一的——记住这点很重要——因为你总会发现好几个算法都可以用来解决某个问题,你需要从中选择最适合的那个。当然,所有的问题都可以用“神经网络”来处理,但是背后承载算力的硬件成本谁来负担呢?
我们先从一些基础的概述开始。目前机器学习主要有4个方向。
未完待续……