
ECCV 2022 | 通往数据高效的Transformer目标检测器
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

论文链接:
代码链接:
Detection Transformer 于 2020 年 ECCV 被提出,作为一种新兴的目标检测方法,Detection Transformers 以其简洁而优雅的框架取得了越来越多的关注。关于 Detection Transformer 的细节和后续的发展历程,本文并不作展开介绍,感兴趣的小伙伴可以参考以下文章:
https://zhuanlan.zhihu.com/p/366938351

研究动机


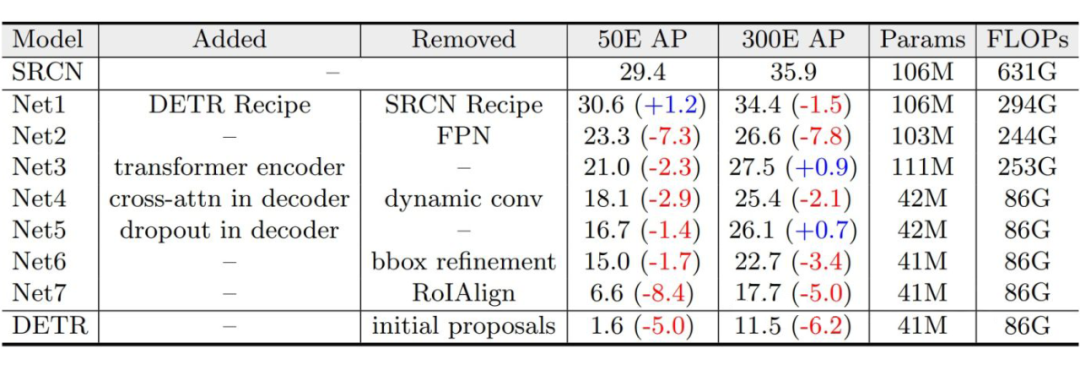
消融探究

我们的方法
3.1 模型增强

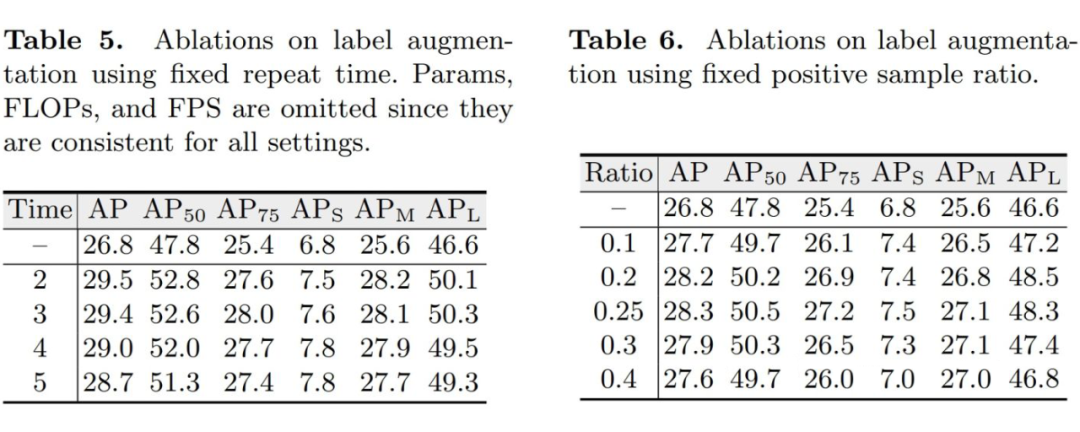
3.2 标签增强
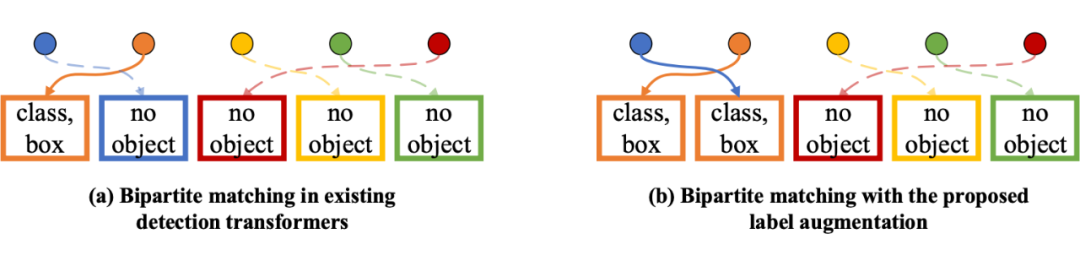
▲ 图3:(a) 现有Detection Transformer的标签分配方式;(b) 使用标签增强后的标签分配。圆圈和矩形框分别表示模型的预测和图片上的物体标注。通过复制橙色方框表示的物体标注,蓝色圆圈表示的模型预测也在标签分配中匹配到了正样本,因此得到了更丰富的监督信号。

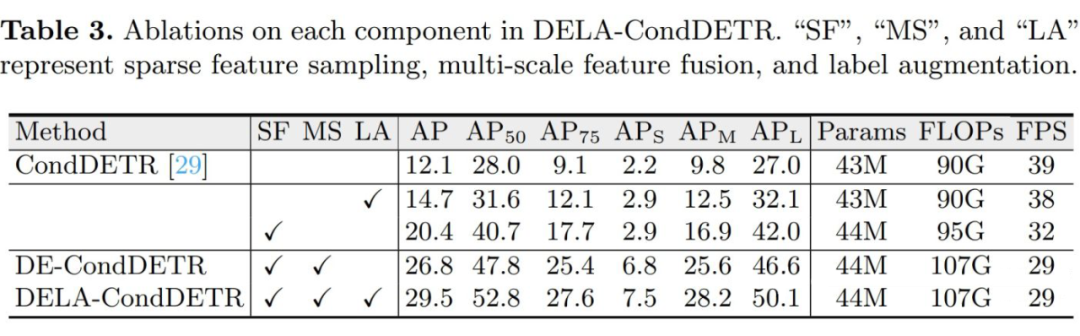
实验

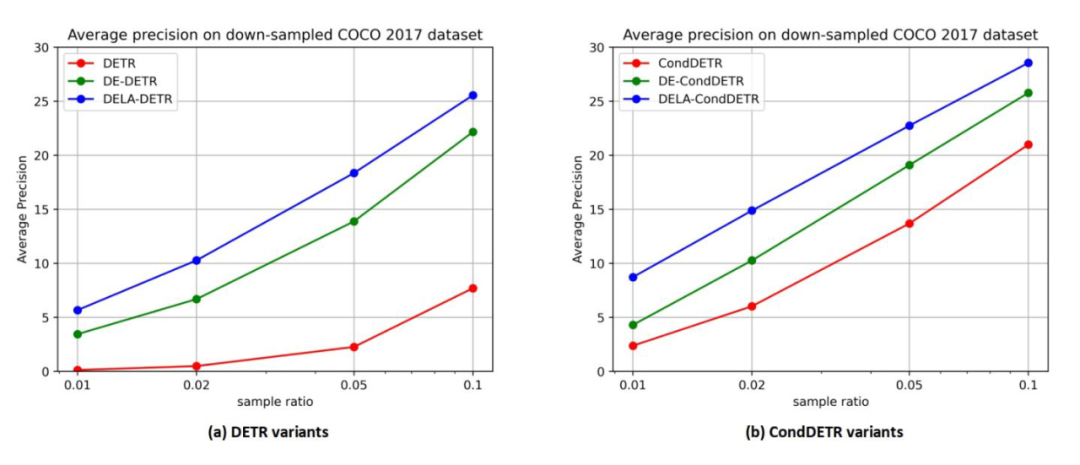
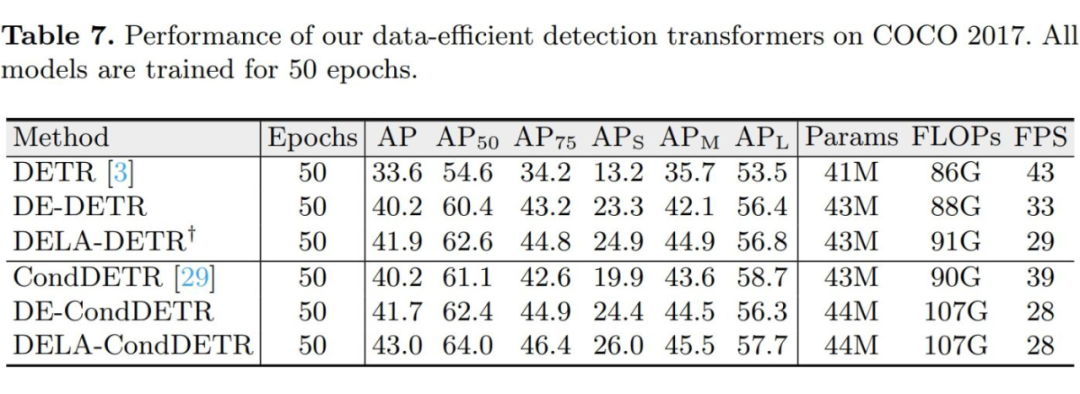
▲ 在训练数据充足的COCO 2017上的性能比较,所有模型都训练50个周期

▲ 图5:不同模型在Cityscapes数据集上的收敛曲线,横轴表示训练周期数,纵轴表示mAP

总结

参考文献
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论