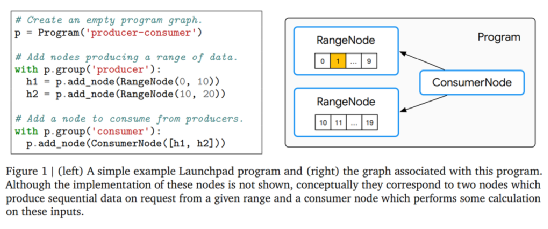
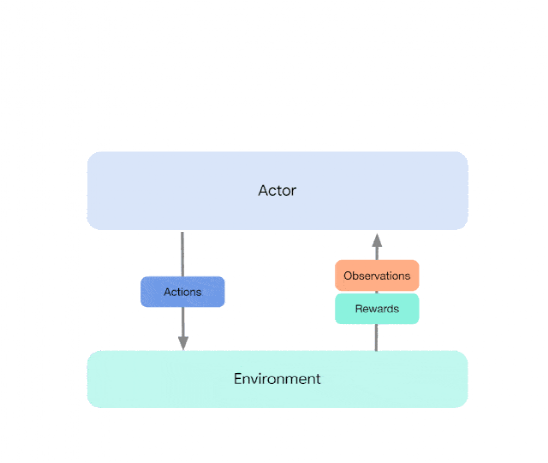
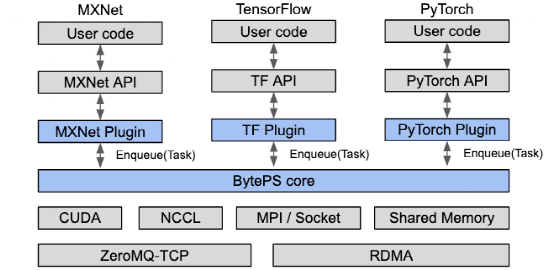
一万亿模型要来了?谷歌大脑和DeepMind联手发布分布式训练框架Launchpad新智元关注共 2344字,需浏览 5分钟 ·2021-06-28 13:09 新智元报道 来源:reddit编辑:LRS【新智元导读】AI模型进入大数据时代,单机早已不能满足训练模型的要求,最近Google Brain和DeepMind联手发布了一个可以分布式训练模型的框架Launchpad,堪称AI界的MapReduce。正如吴恩达所言,当代机器学习算法的成功很大程度上是由于模型和数据集大小的增加,在大规模数据下进行分布式训练也逐渐变得普遍,而如何在大规模数据、大模型的情况下进行计算,还是一个挑战。分布式学习过程也会使实现过程复杂化,这对于许多不熟悉分布式系统机制的机器学习从业者来说是个问题,尤其是那些具有复杂通信拓扑结构的机器学习从业者。在arxiv上一篇新论文中,来自 DeepMind 和 Google Brain 的研究团队用 Launchpad 解决了这个问题,Launchpad 是一种编程模型,它简化了定义和启动分布式计算实例的过程。论文的第一作者是来自DeepMind的华人Yang Fan,毕业于香港中文大学。Launchpad 将分布式系统的拓扑描述为一个图形数据结构,这样图中的每个节点都代表一个服务,即研究人员正在运行的基本计算单元。将句柄构造为节点的引用,将客户端表示为尚未构造的服务。图的边表示两个服务之间的通信,并在构建时将与一个节点相关联的句柄给予另一个节点时创建。通过这种方式,Launchpad 可以通过传递节点句柄来定义跨服务通信。Launchpad 的计算构建块由不同的服务类型表示,每种服务类型由特定于该类型的节点和句柄类表示。论文中提出的 Launchpad 的生命周期可以分为三个阶段: 设置、启动和执行。设置阶段构造程序数据结构; 在启动阶段,处理这个数据结构以分配资源、地址等,并启动指定服务; 然后执行阶段运行服务,例如为服务通信创建客户端。Launchpad 是用流行的编程语言 Python 实现的,它简化了定义程序和节点数据结构以及为单个平台启动的过程。Launchpad 框架还可以很容易地用任何其他宿主语言实现,包括 c/c + + 等低级编程语言。Launchpad 编程模型非常丰富,足以容纳各种各样的分布式系统,包括参数服务器、 MapReduce和 Evolution Strategies。研究人员用简洁的代码详细描述了如何将 Launchpad 应用到这些常见的分布式系统范例中,并说明了该框架在简化本研究领域常用机器学习算法和组件的设计过程方面的能力。总的来说,Launchpad 是一个实用的、用户友好的、表达性强的框架,用于机器学习研究人员和实践者详细说明分布式系统,作者表示,这个框架能够处理日益复杂的机器学习模型。其他框架2020年,DeepMind 发布过一个强化学习优化框架Acme,可以让AI驱动的智能体在不同的执行规模上运行,从而简化强化学习算法的开发过程。强化学习可以让智能体与环境互动,生成他们自己的训练数据,这在电子游戏、机器人技术、自动驾驶机器人出租车等领域取得了突破。随着所使用的训练数据量的增加,这促使设计了一个系统,使智能体与环境实例相互作用,迅速积累经验。DeepMind 断言,将算法的单进程原型扩展到分布式系统通常需要重新实现相关的智能体,这就是 Acme 框架的用武之地。DeepMind研究员写道,「Acme 是一个用于构建可读、高效、面向研究的 RL 算法的框架。Acme 的核心是设计用于简单描述 RL 智能体,这些智能体可以在不同规模的执行中运行,包括分布式智能体。」Determined AI也是一个深度学习神器。Determined使深度学习工程师可以集中精力大规模构建和训练模型,而无需担心DevOps,或者为常见任务(如容错或实验跟踪)编写代码。更快的分布式训练,智能的超参优化,实验跟踪和可视化。Determined主要运用了Horovod,以Horovod为起点,研究人员运用了多年的专业知识和经验,使得整个训练过程比库存配置要快得多。Horovod 是一套面向TensorFlow 的分布式训练框架,由Uber 构建并开源,目前已经运行于Uber 的Michelangelo 机器学习即服务平台上。Horovod 能够简化并加速分布式深度学习项目的启动与运行。当数据较多或者模型较大时,为提高机器学习模型训练效率,一般采用多 GPU 的分布式训练。TensorFlow 集群存在诸多缺点,如概念太多、学习曲线陡峭、修改的代码量大、性能损失较大等,而 Horovod 则让深度学习变得更加美好,随着规模增大,Horovod 性能基本是线性增加的,损失远小于 TensorFlow。2019年,字节跳动AI lab开源了一款高性能分布式框架BytePS,在性能上颠覆了过去几年allreduce流派一直占据上风的局面,超出目前其他所有分布式训练框架一倍以上的性能,且同时能够支持Tensorflow、PyTorch、MXNet等开源库。BytePS 提供了 TensorFlow、PyTorch、 MXNet 以及Keras的插件,用户只要在代码中引用BytePS的插件,就可以获得高性能的分布式训练。BytePS的核心逻辑,则实现在BytePS core里。具体的通信细节,完全由BytePS完成,用户完全不需要操心。-往期精彩- 浏览 43点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 ParlAIAI 对话模型研究和训练框架ParlAI(发音为“par-lay”)是 Facebook 开源的,用于在 Python 中实现的ParlAIAI 对话模型研究和训练框架ParlAI(发音为“par-lay”)是Facebook开源的,用于在Python中实现的对话AI研究框架。其目标是为研究人员提供:一个用于训练和测试对话模型的统一框架一次对多个数据集进行多任务训练Primus分布式训练调度框架Primus是一个用于机器学习应用程序的通用分布式训练调度框架,管理机器学习框架(如Tensorflow、Pytorch)的训练生命周期和数据分布,帮助训练框架获得更好的分布式能力。功能多训练框架支持谷歌大模型团队并入DeepMind!誓要赶上ChatGPT进度肉眼品世界0GNN框架之大规模分布式训练!Datawhale0分布式训练框架Horovod初步学习GiantPandaCV0BytePS高性能分布式深度学习训练框架BytePS 是字节跳动开源的高性能分布式深度学习训练框架,官方宣称 BytePS 在性能上颠覆了过BytePS高性能分布式深度学习训练框架BytePS是字节跳动开源的高性能分布式深度学习训练框架,官方宣称BytePS在性能上颠覆了过去几年allreduce流派一直占据上风的局面,超出目前其他所有分布式训练框架一倍以上的性能,且同时能够支谷歌AI发布稀疏模型高效设计指南!机器学习算法工程师0230亿美元,谷歌史上最大收购要来了!拿下网络安全黑马创企,能否给谷歌云业务注入新活力?7月15日消息,昨日据《华尔街日报》报道,谷歌母公司Alphabet将以近230亿美元的价格收购网络安全初创公司Wiz,双方正在进行深入谈判,如果谈判成功,这将成为谷歌有史以来规模最大的收购,超过了其在2012年以125亿美元收购摩托罗拉移动(Mot点赞 评论 收藏 分享 手机扫一扫分享分享 举报








 下载APP
下载APP