
图论的各种基本算法
日期:2020年09月16日
正文共:14424字37图
预计阅读时间:9分钟
来源: Mr.Riddler's Puzzle
伪代码: IS-BIPARTITE(g,colors) let queue be new Queue colors[0] = 1 queue.push(0) while queue.empty() == false let v = queue.top() queue.pop() for i equal to every vertex in g if colors[i] == 0 colors[i] = 3 - colors[v] queue.push(i) else if colors[i] == colors[v] return false end end return true
伪代码: DFS-IMPROVE(v,visited,stack) visited[v] = true for i equal to every vertex adjacent to v if visited[i] == false DFS-IMPROVE(i,visited,stack) end stack.push(v)
伪代码: EULERIAN-PATH-AND-CIRCUIT(g) if isConnected(g) == false return 0 let odd = 0 for v equal to every vertex in g if v has not even edge odd = odd + 1 end if odd > 2 returon 0 if odd == 1 return 1 if odd == 0 return 2
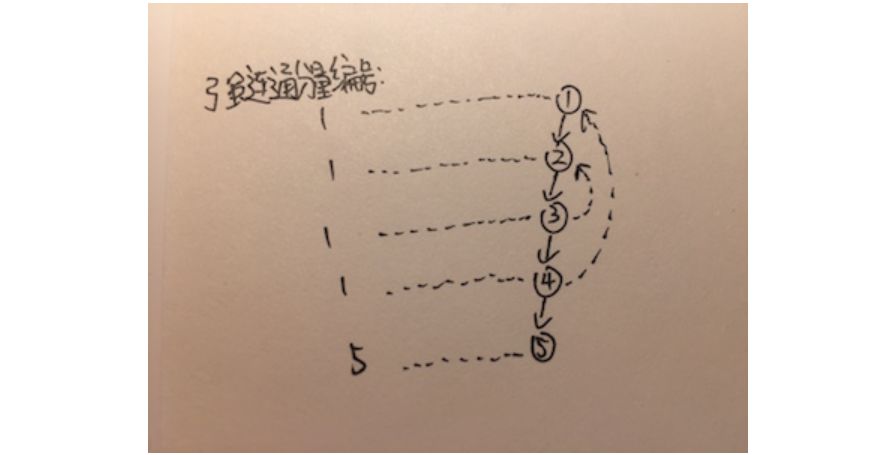
伪代码: TOPOLOGICAL-SORTING-DFS(g) let visited be new Array let result be new Array let stack be new Stack for v equal to every vertex in g if visited[v] == false DFS-IMPROVE(v,visited,stack) end while stack.empty() == false result.append(stack.top()) stack.pop() end return result
伪代码: TOPOLOGICAL-SORTING-GREEDY(g) let inDegree be every verties inDegree Array let stack be new Stack let result be new Array for v equal to every vertex in g if inDegree[v] == 0 stack.push(v) end while stack.empty() == false vertex v = stack.top() stack.pop() result.append(v) for i equal to every vertex adjacent to v inDegree[i] = inDegree[i] - 1 if inDegree[i] == 0 stack.push(i) end end return result.reverse()
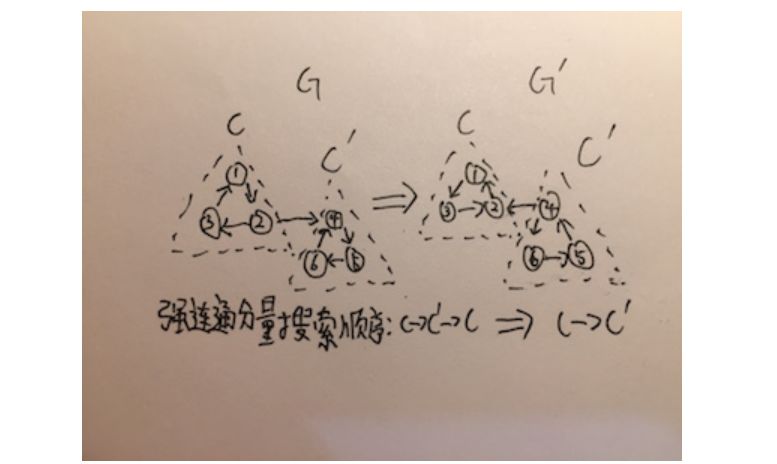
伪代码: KOSARAJU-STRONGLY-CONNECTED-COMPONENTS(g) let visited be new Array let stack be new Stack for v equal to every vertex in g if visited[v] == false DFS-IMPROVE(v,visited,stack) end let gt = transpose of g for v equal to every vertex in g visited[v] = false end while stack.empty() == false vertex v = stack.top() stack.pop() if visited[v] == false DFS(v,visited) print ' Found a Strongly Connected Components ' end DFS(v,visited) visited[v] = true print v for i equal to every vertex adjacent to v if visited[i] == false DFS(i,visited,stack) end
伪代码: TARJAN-STRONGLY-CONNECTED-COMPONENTS(g) let disc be new Array let low be new Array let stack be new Stack let isInStack be new Array for i from 1 to the number of vertex in g disc [i] = -1 low [i] = -1 end for u from 1 to the number of vertex in g if disc[i] != -1 TARJAN-STRONGLY-CONNECTED-COMPONENTS-UTIL(u,disc,low,stack,isInStack) end TARJAN-STRONGLY-CONNECTED-COMPONENTS-UTIL(u,disc,low,stack,isInStack) let time be static time = time + 1 disc[u] = low[u] = time stack.push(u) isInStack[u] = true for v equal to every vertex adjacent to u if disc[v] == -1 TARJAN-STRONGLY-CONNECTED-COMPONENTS-UTIL(v,disc,low,stack,isInStack) low[u] = min(low[u],low[v]) else if isInStack[v] == true low[u] = min(low[u],disc[v]) end let w = 0 if low[u] == disc[u] while stack.top() != u w = stack.top() isInStack[w] = false stack.pop() print w end w = stack.top() isInStack[w] = false stack.pop() print w print ' Found a Strongly Connected Components '
伪代码: ARTICULATION-POINTS(g) let disc be new Array let low be new Array let result be new Array let parent be new Array let visited be new Array for i from 1 to the number of vertex in g result [i] = false visited [i] = false parent [i] = -1 end for u from 1 to the number of vertex in g if visited[i] == false ARTICULATION-POINTS-UTIL(u,disc,low,result,parent,visited) end for i from 1 to the number if vertex in g if result[i] == true print ' Found a Articulation Points i ' end ARTICULATION-POINTS-UTIL(u,disc,low,result,parent,visited) let time be static time = time + 1 let children = 0 disc[u] = low[u] = time visited[u] = true for v equal to every vertex adjacent to u if visited[v] == false children = children + 1 parent[v] = u ARTICULATION-POINTS-UTIL(u,disc,low,result,parent,visited) low[u] = min(low[u],low[v]) if parnet[u] == -1 and children > 1 result[u] = true if parent[u] != -1 and low[v] >= disc[u] result[u] = true else if v != parent[u] low[u] = min(low[u],disc[v]) end
伪代码: BRIDGE(g) let disc be new Array let low be new Array let parent be new Array let visited be new Array for i from 1 to the number of vertex in g visited [i] = false parent [i] = -1 end for u from 1 to the number of vertex in g if visited[i] == false BRIDGE-UTIL(u,disc,low,parent,visited) end BRIDGE-UTIL(u,disc,low,parent,visited) let time be static time = time + 1 disc[u] = low[u] = time for v equal to every vertex adjacent to u if visited[v] == false parent[v] = u BRIDGE-UTIL(u,disc,low,parent,visited) low[u] = min(low[u],low[v]) if low[v] > disc[u] print ' Found a Bridge u->v ' else if v != parent[u] low[u] = min(low[u],disc[v]) end
伪代码: BICONNECTED-COMPONENTS(g) let disc be new Array let low be new Array let stack be new Stack let parent be new Array for i from 1 to the number of vertex in g disc [i] = -1 low [i] = -1 parent [i] = -1 end for u from 1 to the number of vertex in g if disc[i] == -1 BICONNECTED-COMPONENTS-UTIL(u,disc,low,stack,parent) let flag = flase while stack.empty() == false flag = true print stack.top().src -> stack.top().des stack.pop() end if flag == true print ' Found a Bioconnected-Components ' end BICONNECTED-COMPONENTS-UTIL(u,disc,low,stack,parent) let time be static time = time + 1 let children = 0 disc[u] = low[u] = time for v equal to every vertex adjacent to u if disc[v] == -1 children = children + 1 parent[v] = u stack.push(u->v) BICONNECTED-COMPONENTS-UTIL(u,disc,low,stack,parent) low[u] = min(low[u],low[v]) if (parnet[u] == -1 and children > 1) or (parent[u] != -1 and low[v] >= disc[u]) while stack.top().src != u or stack.top().des != v print stack.top().src -> stack.top().des stack.pop() end print stack.top().src -> stack.top().des stack.pop() print ' Found a Bioconnected-Components ' else if v != parent[u] and disc[v] < low[u] low[u] = min(low[u],disc[v]) stack.push(u->v) end
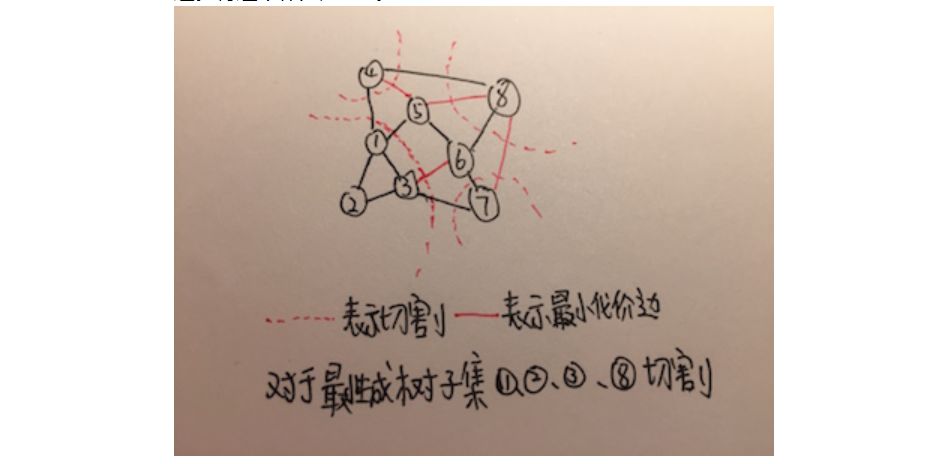
KRUSKAL(g) let edges be all the edges of g sort(edges) let uf be new UnionFind let e = 0 let i = 0 let result be new Array while e < edges.length() let edge = edges[i] i = i + 1 if uf.find(edge.src) != uf.find(edge.des) result.append(edge) e = e + 1 uf.union(edge.src,edge.des) end return result
伪代码: PRIM(g,s) let heap be new MinHeap let result be new Array for i from 1 to the number of vertex in g let vertex be new Vertex(i) vertex.weight = INT_MAX heap.insert(vertex) end heap.decrease(s,0) while heap.empty() == false vertex v = heap.top() for u equal to every vertex adjacent to v if heap.isNotInHeap(u) and v->u < heap.getWeightOfNode(u) result[u] = v heap.decrease(u,v->u) end end return result
伪代码: Boruvka(g) let uf be new UnionFind let cheapest be new Array let edges be all the edge of g let numTree = the number of vertex in g let result be new Array for i from 1 to number of vertex in g cheapest[i] = -1 end while numTree > 0 for i from 1 to the number of edge in g let set1 = uf.find(edges[i].src) let set2 = uf.find(edges[i].des) if set1 == set2 continue if cheapest[se1] == -1 or edges[cheapest[set1]].weight > edges[i].weight cheapest[set1] = i if cheapest[set2] == -1 or edges[cheapest[set2]].weight > edges[i].weight cheapest[set2] = i end for i from 1 to the number of vertex in g if cheapest[i] != -1 let set1 = uf.find(edges[cheapest[i]].src) let set2 = uf.find(edges[cheapest[i]].des) if set1 == set2 continue result[edges[cheapest[i]].src] = edges[cheapest[i]].des uf.union(set1,set2) numTree = numTree - 1 end end return result
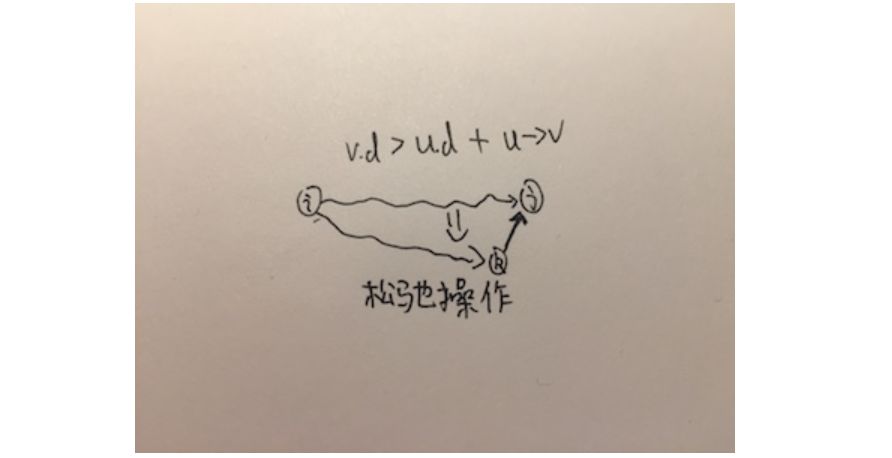
RELAX(u,v,result) if v.d > u.d + u->v v.d = u.d + u->v result[v] = u
伪代码: DAG-SHORTEST-PATHS(g) let sorted = TOPOLOGICAL-SORTING-GREEDY(g) let result be new Array for u equal to every vertex in sorted for v equal to every vertex adjacent to u if v.d > u.d + u->v RELAX(u,v,result) end end return result
伪代码: BELLMAN-FORD(g,s) let edges be all the edge of g let result be new Array for i from 1 to the number of vertex of g result[i] = INT_MAX end result[s] = 0 for i from 1 to the number of vertex of g minus 1 let flag = false for j from 1 to the numnber of edge of g let edge = edges[j] if result[edge.src] != INT_MAX and edge.src > edge.des + edge.weight RELAX(u,v,result) flag = true end if flag == false break end return result
伪代码: DIJKSTRA(g,s) let heap be new MinHeap let result be new Array for i from 1 to the number of vertex in g let vertex be new Vertex(i) vertex.d = INT_MAX heap.insert(vertex) end heap.decrease(s,0) while heap.empty() == false vertex u = heap.top() for v equal to every vertex adjacent to u if heap.isNotInHeap(v) and u.d v.d > u.d + u->v RELAX(u,v,result) heap.decrease(v,v.d) end end return result

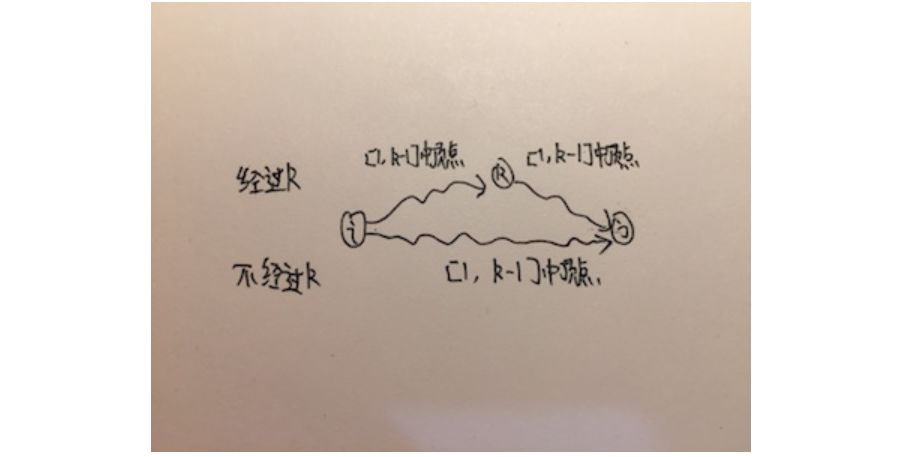
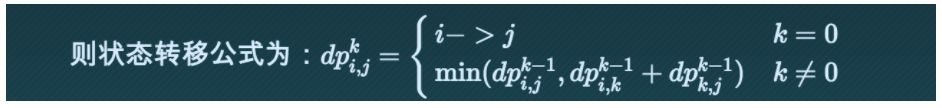
伪代码: FLYOD-WARSHALL(g) let dp be new Table for i from 1 to the number of vertex in g for j from 1 to the number of vertex in g dp[i][j] = g[i][j] end end for k from 1 to the number of vertex in g for i from 1 to the number of vertex in g for j from 1 to the number of vertex in g if dp[i][k] + dp[k][j] < dp[i][j] dp[i][j] = dp[i][k] + dp[k][j] end end end return dp

伪代码: JOHNSON(g) let s be new Vertex g.insert(s) if BELLMAN-FORD(g,s) == flase there is a negative cycle in graph else for v equal to every vertex in g h(v) = min(v~>s) end for (u,v) equal to every edge in graph w’(u,v) = w(u,v) + h(u) - h(v) end let result be new Table for u equal to every vertex in g DIJSKTRA(g,u) for v equal to every vertex in g result[u][v] = min(u~>v) + h(v) - h(u) end end return result
— THE END —

评论