
当可解释人工智能遇上知识图谱

来源:知乎—机器学习小谈 地址:https://zhuanlan.zhihu.com/p/386458680 本文约6100字,建议阅读10分钟 可解释人工智能遇上知识图谱。
背景意义
相比普通的传统知识表示,知识图谱具有专家知识、质量精良等优点。 当然知识图谱也可以从不同的数据源中统一结构,具有数据类型多样性的优点。通过节点和关系把所有不同种类的信息(Heterogeneous Information)连接在一起得到一个关系网络,为真实世界的各个场景直观建模。 随着近几年知识图谱技术的进步一个重要变化就是越来越多的研究与落地工作从通用知识图谱转向了领域或行业知识图谱,转向了企业知识图谱。对比通用知识图谱,随着人工智能在细分以及新兴领域上的应用,专业型知识图谱越来越受到重视。 相比于其他结构知识库,知识图谱的构建以及使用都更加接近人类的认知学习行为,因此对于人类阅读会更加友好
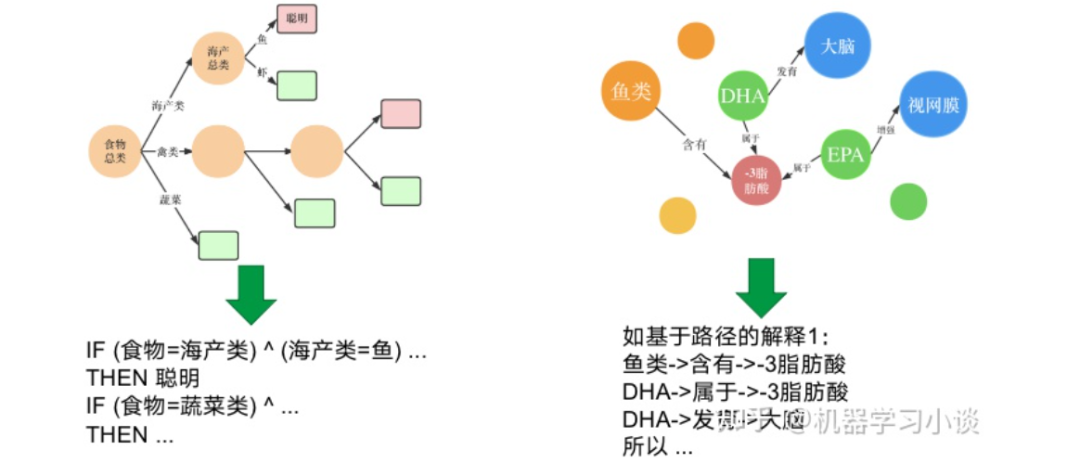
基于路径的方法
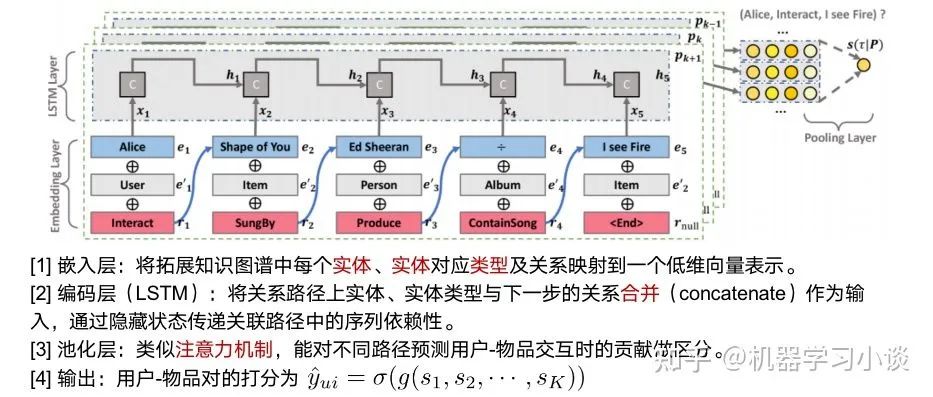
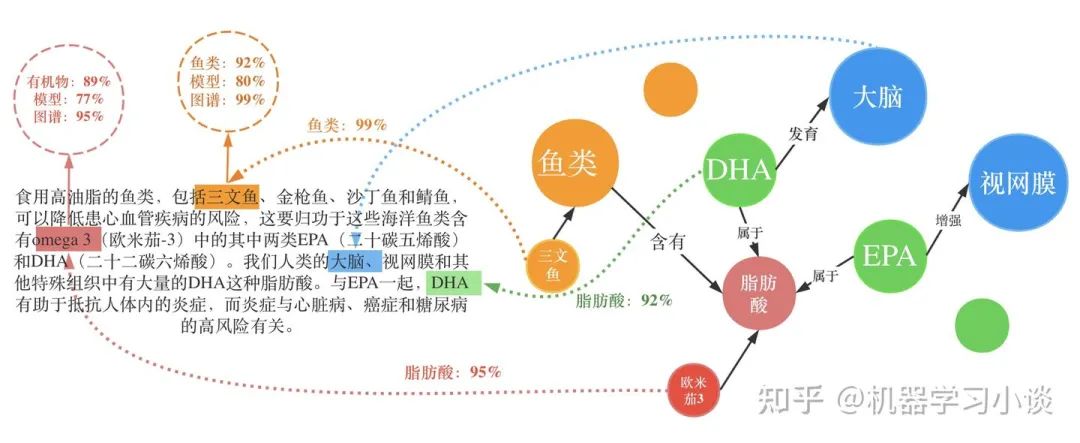
这条路径得出的一个解释是,“有很多观看该电影的用户,都喜欢The Incredible Journey;而这部电影刚好也是由你喜欢的电影Fantasia的导演Jams Algar指导的;不妨你可以试试。”当然这个解释可以用生成模型生成。
我们甚至还能从其他的高分路径得到这个用户感兴趣的导演James等。
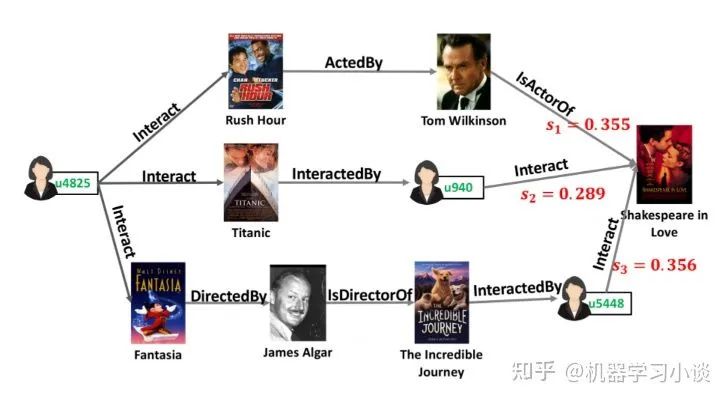
答复:这个问题问的很细节。我也曾经好奇过,但是我发现,作者挑选路径仅仅基于路径的长度来筛选,譬如筛选路径长度少于6跳的。但是我同时也会疑问,解释一定就跟长度有关吗?难道长路径的解释就一定比短路径要差?我发现很多读者也提出不同的想法,例如用随机游走之类的算法,收敛的时候对路径的概率进行排序,最后选择topk之类,这些也我们可以深挖的方向。
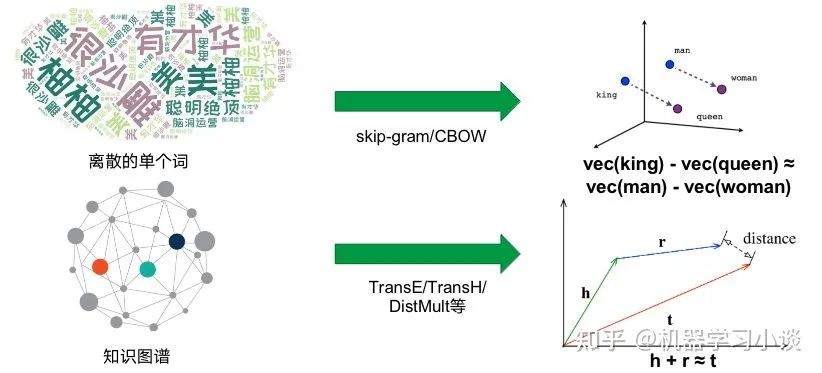
基于嵌入的方法
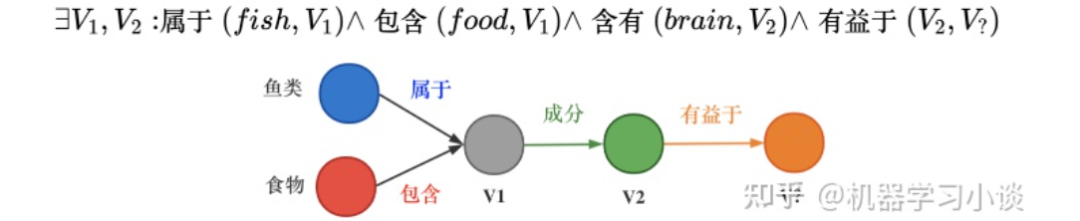
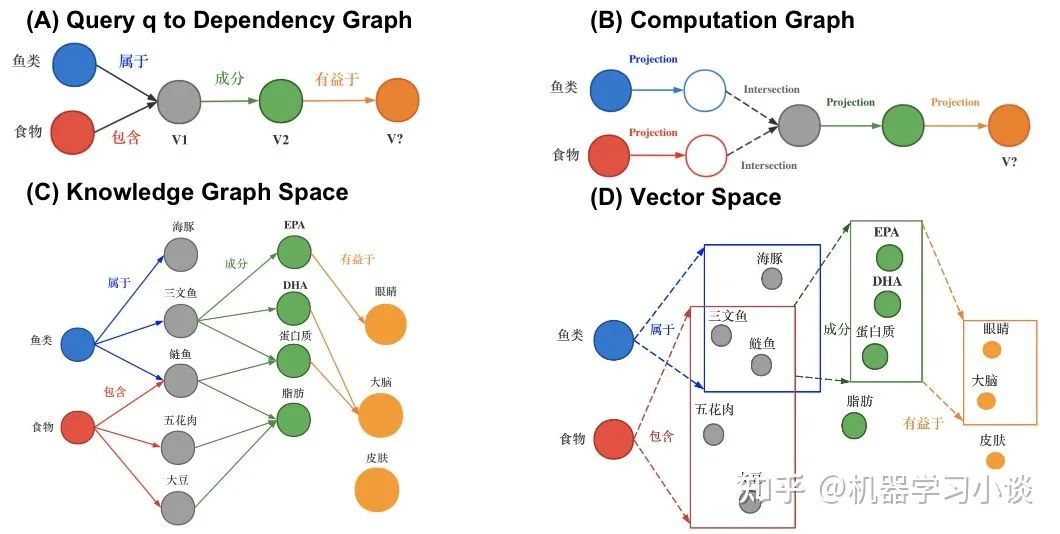
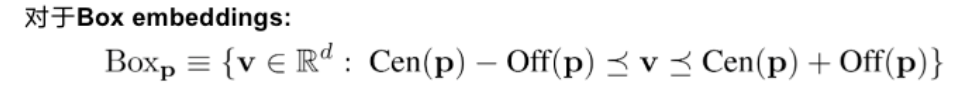



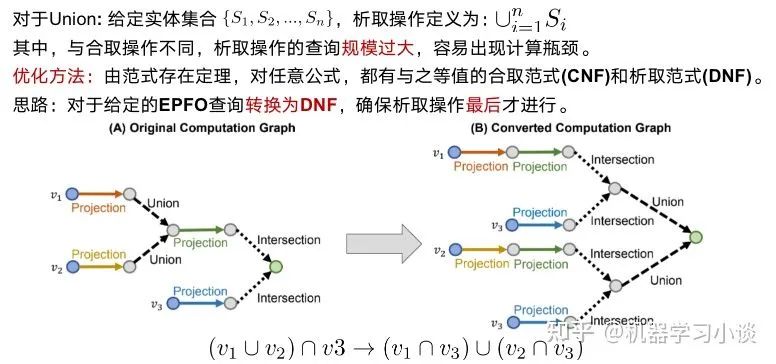
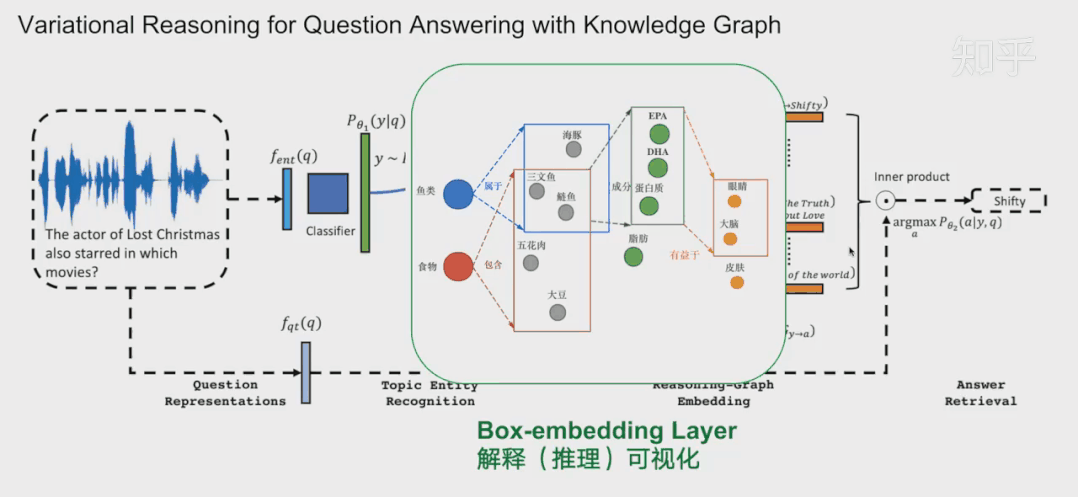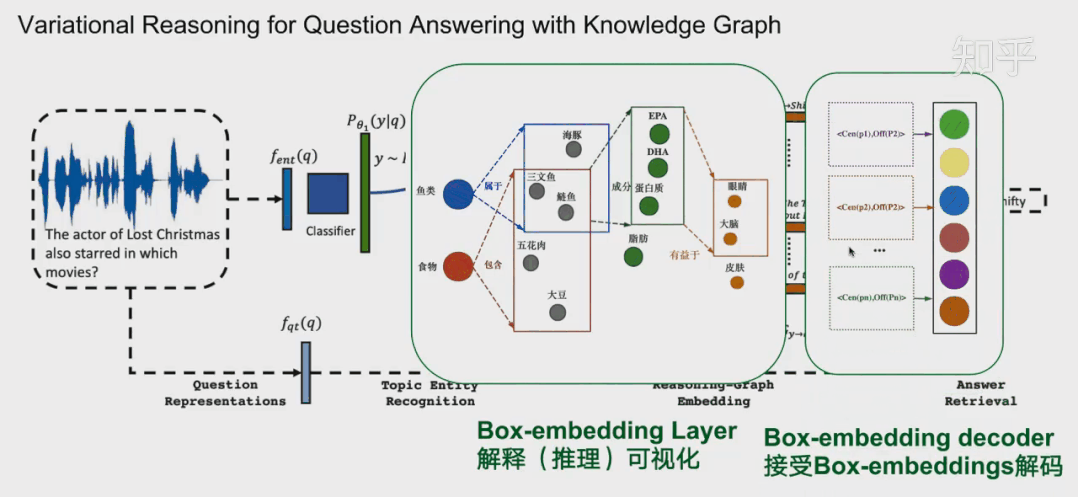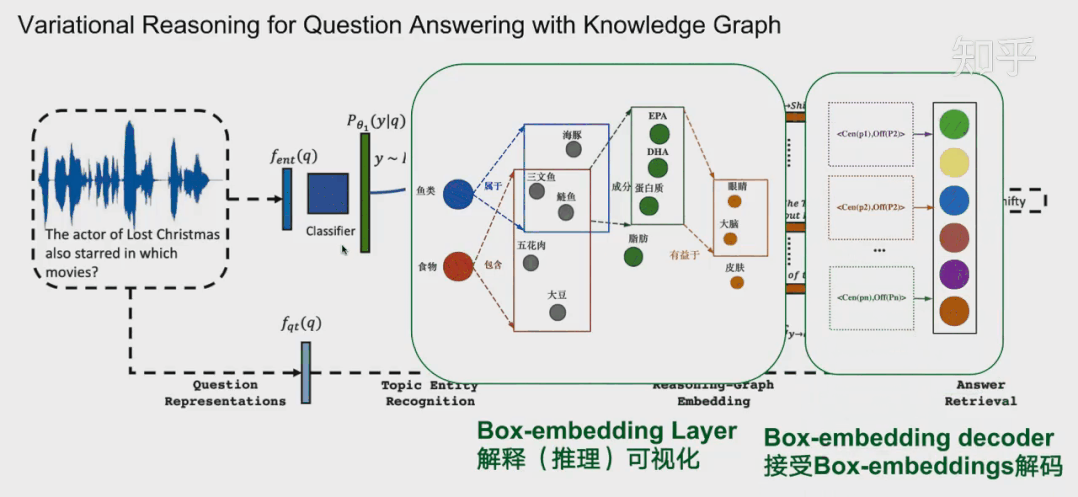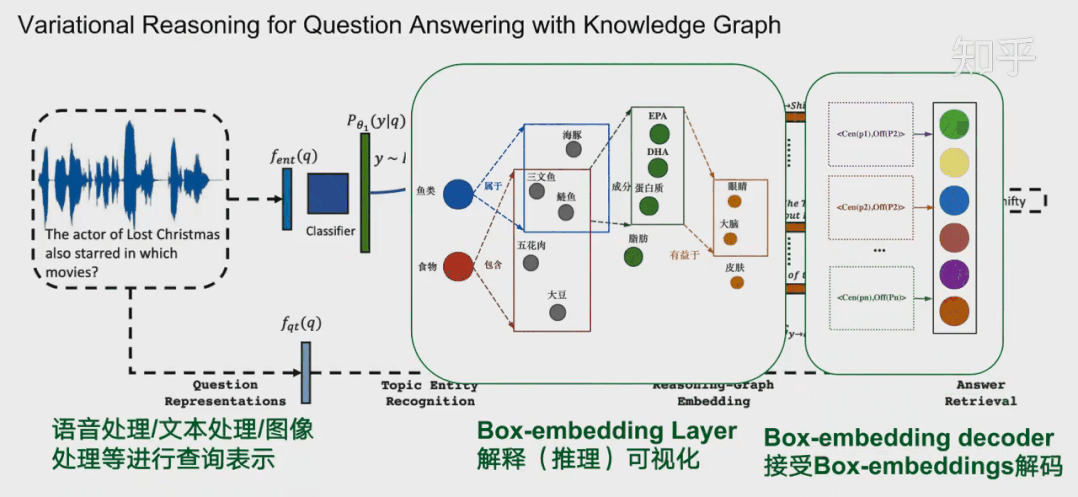
总结和展望

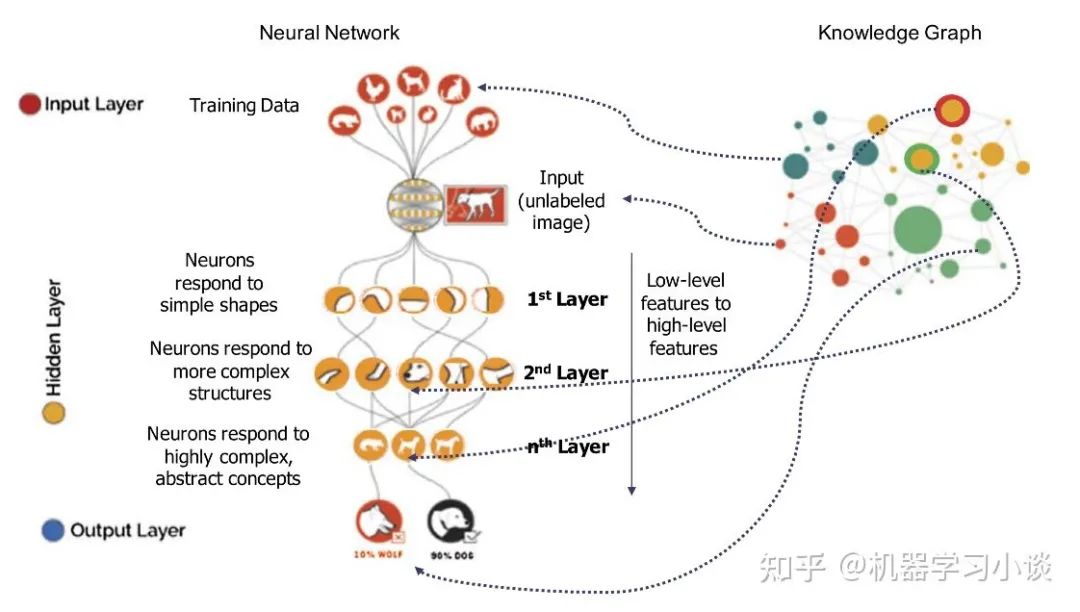
答复:当然是有其他类型的。例如,混合型的,如涟漪神经网络RippleNet,这种网络是既有基于路径的也有基于嵌入的。有例如,比较火的是图神经网络,譬如自然语言处理里面就有与图神经网络相结合搞可解释性的。大概原理首先将文本进行图表示(例如语法解释树也是一种图结构,这种解释可以用一些语法相关的图谱去完成)
编辑:黄继彦
校对:林亦霖
评论