
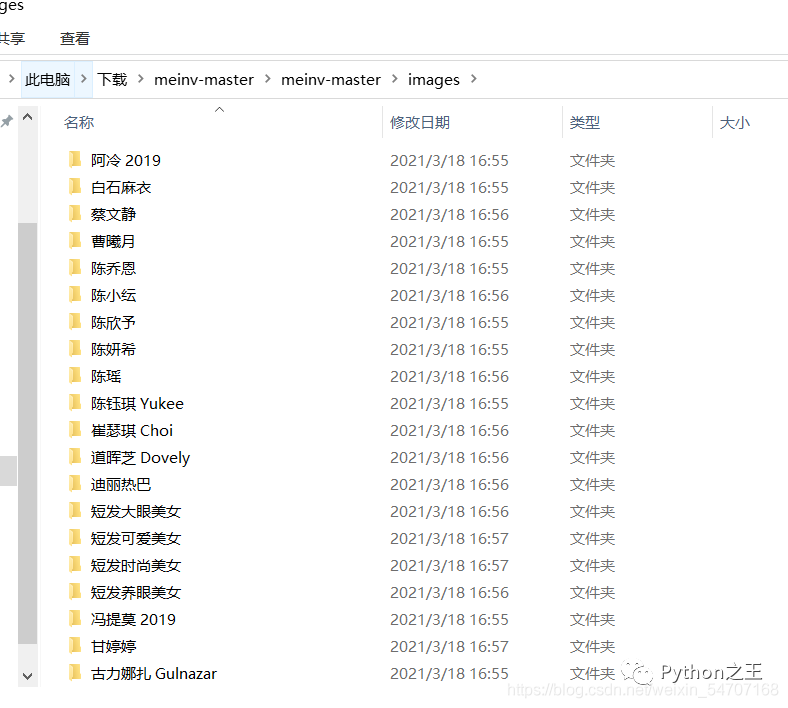
Scrapy爬取整个美女网爬下来,要多少有多少
都2021年了还没爬过大家喜欢的美女图片,上先爬取的成果。


简介
基于Scrapy框架的 美女网爬取
爬虫入口地址:http://www.meinv.hk/?cat=2
如果你的爬虫运行正常却没有数据,可能的原因是访问该网站需要梯子。
这里主要学习两个 技术点、自定义图片管道和自定义csv数据管道
实现流程
创建项目太简单了,不说了。
打开网站
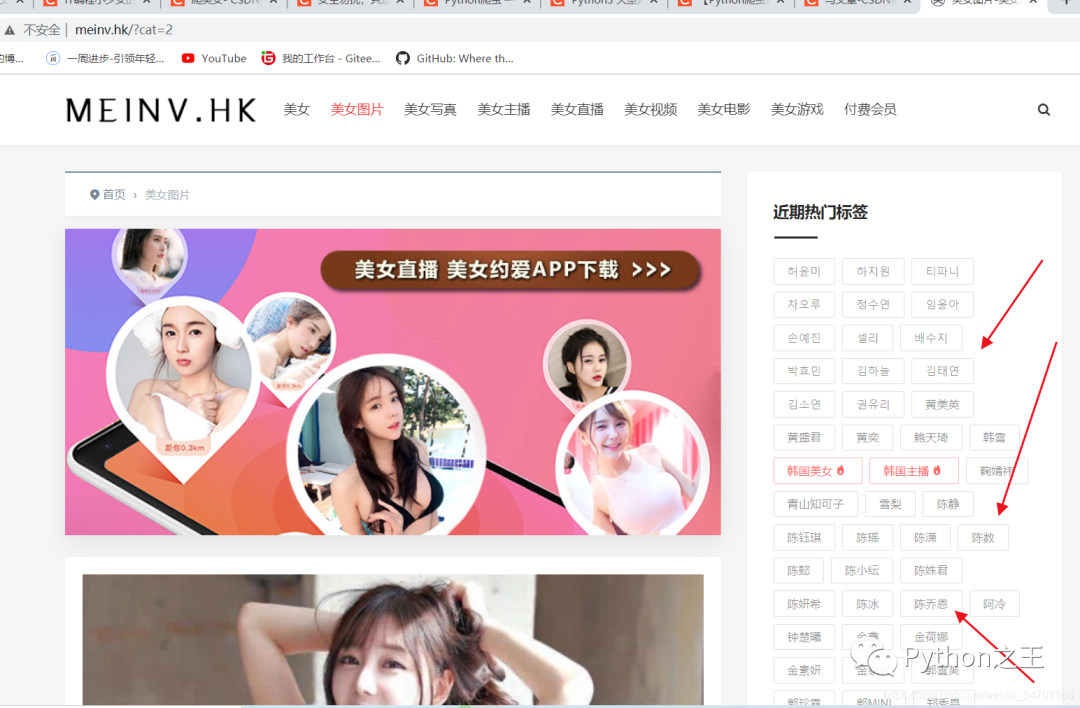 在点击过程中,得到具体的爬取思路,先爬取热门推荐的标签,然后在得到每一个美女的具体的图片的网址。
在点击过程中,得到具体的爬取思路,先爬取热门推荐的标签,然后在得到每一个美女的具体的图片的网址。
那么就使用下rules。
rules内规定了对响应中url的爬取规则,爬取得到的url会被再次进行请求,并根据callback函数和follow属性的设置进行解析或跟进。
这里强调两点:
一是会对所有返回的response进行url提取,包括首次url请求得来的response; 二是rules列表中规定的所有Rule都会被执行。
进入到pipeline.py里面,引入 from scrapy.pipelines.images import ImagesPipeline, 并且继承 ImagesPipeline
自定义pipeline可以基于scrapy自带的ImagesPipeline的基础上完成。可以重写ImagesPipeline中的三个法:get_media_requests(),file_path(),item_completed()
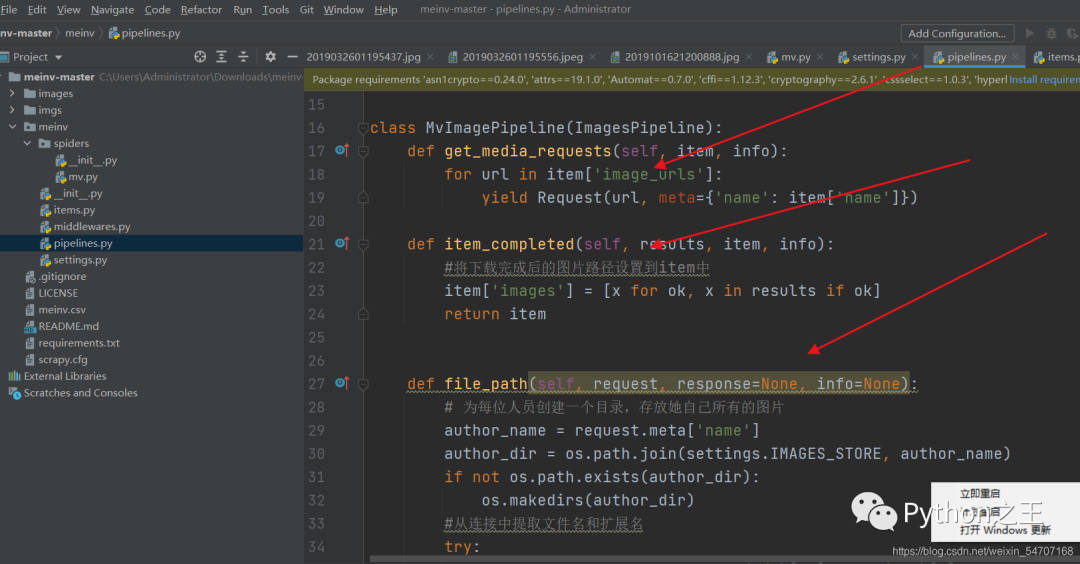
具体代码
因为使用的是自定义管道(图片和CSV),因此不需要编写「item.py」
mv.py
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class MvSpider(CrawlSpider):
name = 'mv'
allowed_domains = ['www.meinv.hk']
start_urls = ['http://www.meinv.hk/?cat=2']
# 增加提取 a 标签的href连接的规则
# 将提取到的href连接,生成新的Request 请求, 同时指定新的请求后解析函数
rules = (
# allow 默认使用正则的表达式,查找所有a标签的href
# follow 为True时,表示在提取规则连接下载完成后,是否再次提取规则中连接
Rule(LinkExtractor(allow=r'p=\d+'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
info = response.xpath('//div[@class="wshop wshop-layzeload"]/text()').extract_first()
try:
item['hometown'] = info.split("/")[2].strip().split()[1]
item['birthday'] = info.split("/")[1].strip().split()[1]
except:
item['birthday'] = "未知"
item['hometown'] = "未知"
item['name'] = response.xpath('//h1[@class="title"]/text()').extract_first()
images = response.xpath('//div[@class="post-content"]//img/@src')
try:
item['image_urls'] = images.extract()
except:
item['image_urls'] = ''
item['images'] = ''
item['detail_url'] = response.url
yield item
middlewares.py
import random
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class RandomUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent_list):
super().__init__()
self.user_agent_list = user_agent_list
@classmethod
def from_crawler(cls, crawler):
return cls(user_agent_list=crawler.settings.get('USER_AGENT_LIST'))
def process_request(self, request, spider):
user_agent = random.choice(self.user_agent_list)
if user_agent:
request.headers['User-Agent'] = user_agent
return None
pipelines.py
import csv
import os
from hashlib import sha1
from scrapy import Request
from scrapy.pipelines.images import ImagesPipeline
from meinv import settings
class MvImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for url in item['image_urls']:
yield Request(url, meta={'name': item['name']})
def item_completed(self, results, item, info):
#将下载完成后的图片路径设置到item中
item['images'] = [x for ok, x in results if ok]
return item
def file_path(self, request, response=None, info=None):
# 为每位人员创建一个目录,存放她自己所有的图片
author_name = request.meta['name']
author_dir = os.path.join(settings.IMAGES_STORE, author_name)
if not os.path.exists(author_dir):
os.makedirs(author_dir)
#从连接中提取文件名和扩展名
try:
filename = request.url.split("/")[-1].split(".")[0]
except:
filename = sha1(request.url.encode(encoding='utf-8')).hexdigest()
try:
ext_name = request.url.split(".")[-1]
except:
ext_name = 'jpg'
# 返回的相对路径
return '%s/%s.%s' % (author_name, filename, ext_name)
class MeinvPipeline(object):
def __init__(self):
self.csv_filename = 'meinv.csv'
self.existed_header = False
def process_item(self, item, spider):
# item dict对象,是spider.detail_parse() yield{}输出模块
with open(self.csv_filename, 'a', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=(
'name', 'hometown', 'birthday', 'detail_url'))
if not self.existed_header:
# 如果文件不存在,则表示第一次写入
writer.writeheader()
self.existed_header = True
image_urls = ''
for image_url in item['image_urls']:
image_urls += image_url + ','
image_urls.strip("\"").strip("\'")
data = {
'name': item['name'].strip(),
'hometown': item['hometown'],
'birthday': item['birthday'].replace('年', '-').replace('月', '-').replace('日', ''),
'detail_url': item['detail_url'],
}
writer.writerow(data)
f.close()
return item
Setting.py
import os
BOT_NAME = 'meinv'
SPIDER_MODULES = ['meinv.spiders']
NEWSPIDER_MODULE = 'meinv.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DOWNLOADER_MIDDLEWARES = {
'meinv.middlewares.RandomUserAgentMiddleware': 543,
}
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# ImagePipeline 存放图片使用的目录位置
IMAGES_STORE = os.path.join(BASE_DIR, 'images')
ITEM_PIPELINES = {
'meinv.pipelines.MeinvPipeline': 300,
'meinv.pipelines.MvImagePipeline':100
}
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'
]
1.文件目录

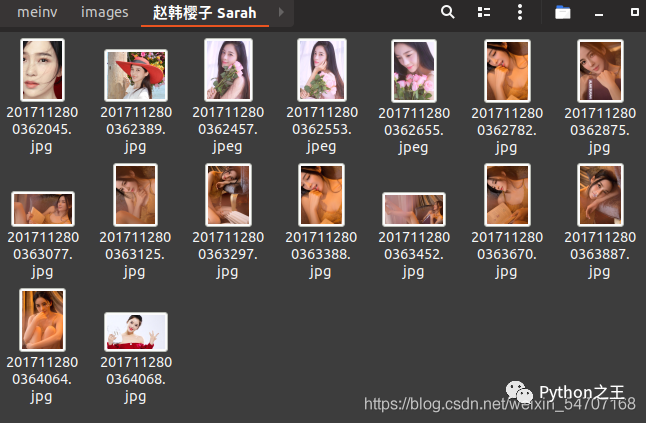
2.某人图片
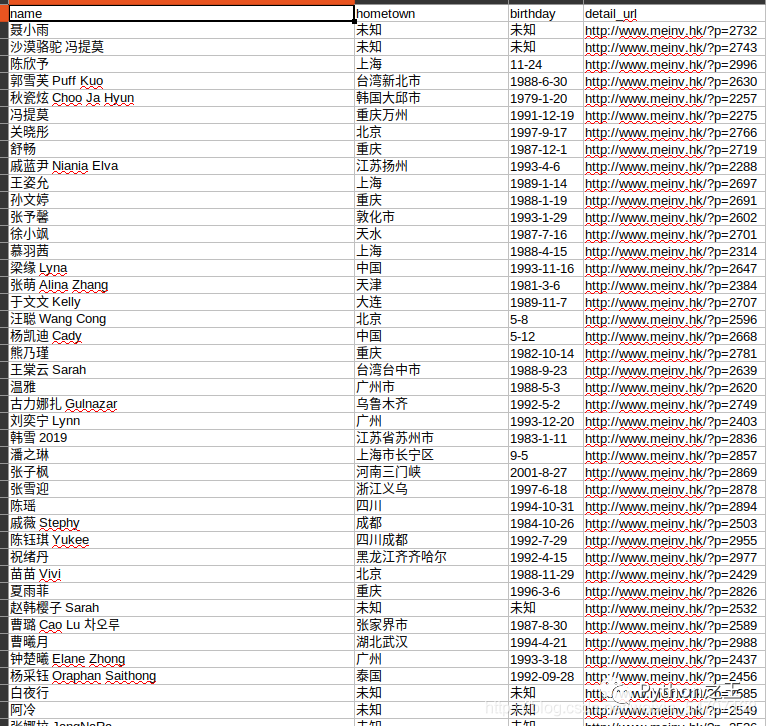
3.csv文件内容
最后上几个美图



评论