
Scrapy爬取网易严选制作可视化大屏!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包

需求分析


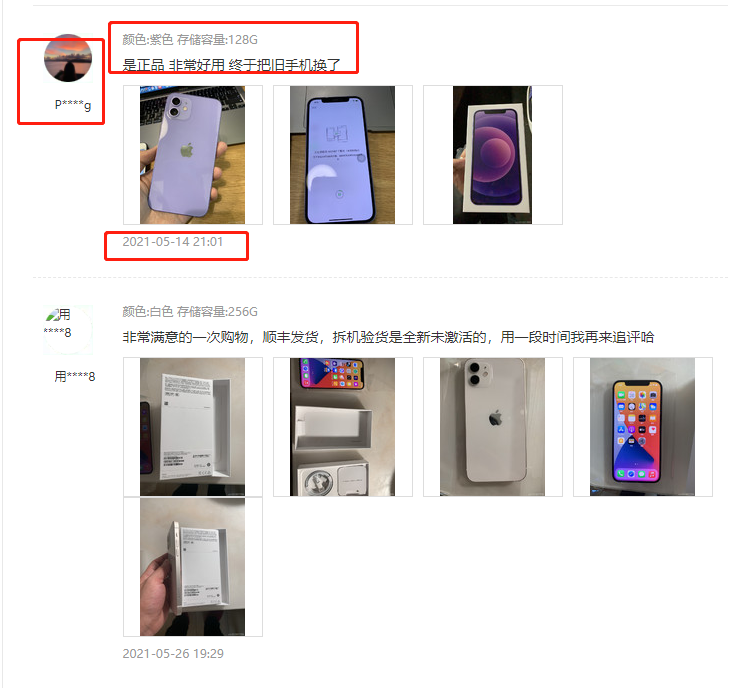
网页分析
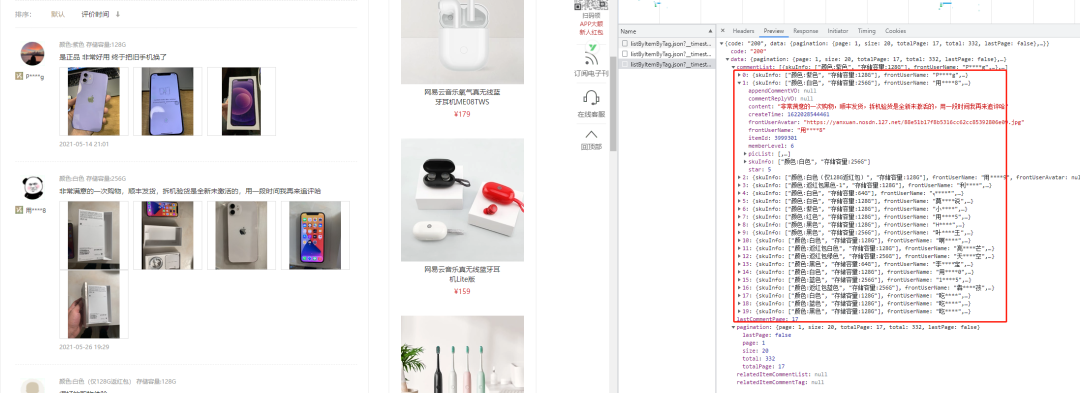
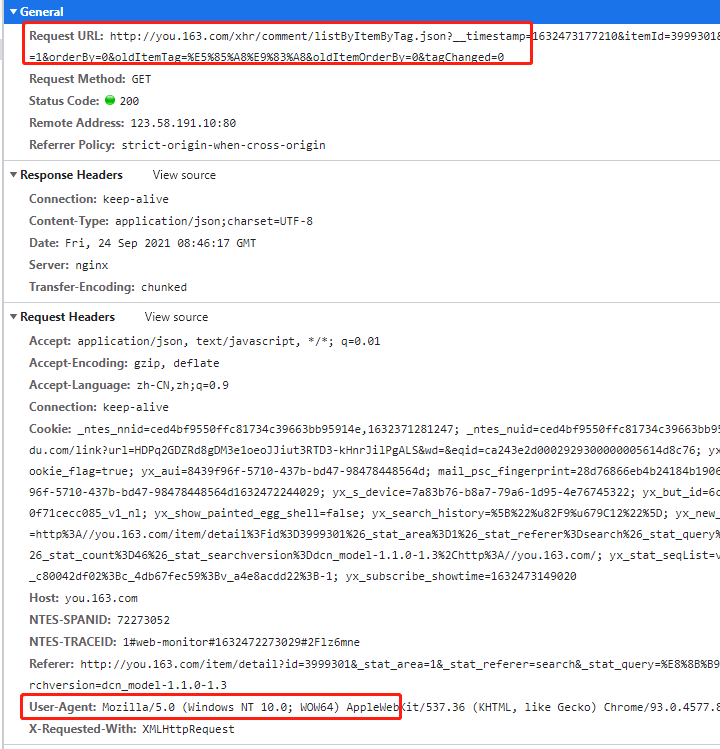

发送请求
# 名称
name = scrapy.Field()
# 等级
level = scrapy.Field()
# 评分
star = scrapy.Field()
# 时间
rls_time = scrapy.Field()
# 颜色
color = scrapy.Field()
# 内存
storage = scrapy.Field()
# 评论
content = scrapy.Field()ic(response.json())浏览器成功响应给我们信息,这样看起来结构一目了然。
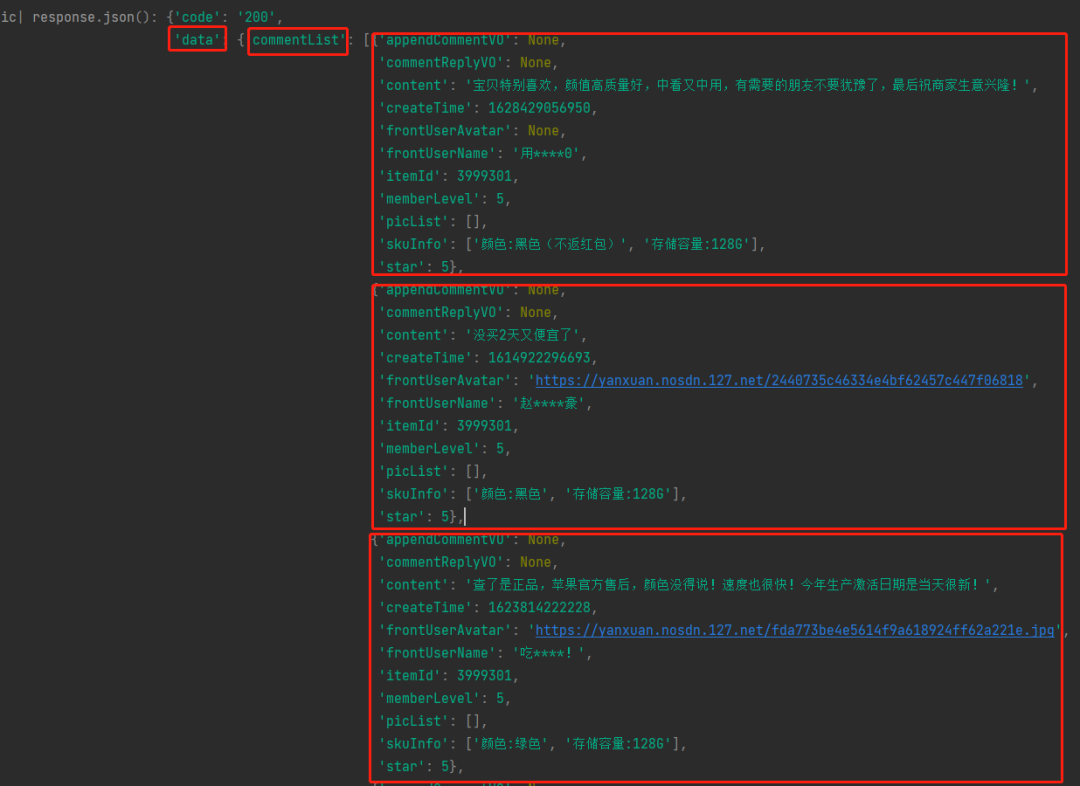
phone_list = phone_info['data']['commentList']
# 打印所需信息
for phone in phone_list:
# 名称
item['name'] = phone['frontUserName']
# 等级
item['level'] = phone['memberLevel']
# 评分
item['star'] = phone['star']
# 时间
rls_time = phone['createTime']
item['rls_time'] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(rls_time/1000)).split(' ')[0]
# 颜色
item['color'] = phone['skuInfo'][0].split(':')[1]
# 内存
item['storage'] = phone['skuInfo'][1].split(':')[1]
# 评论
item['content'] = phone['content']
yield item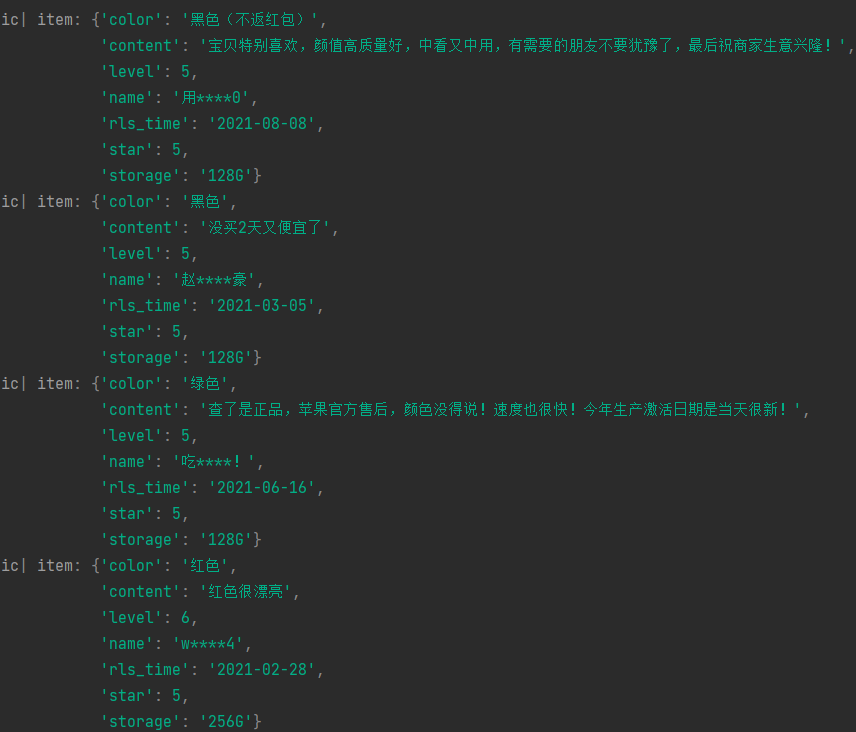
数据保存
class ExcelPipeline:
op.Workbook()
self.wb.active
ws.append(['用户名称', '会员等级', '手机评分', '评论时间', '手机颜色', '手机内存', '评论'])
self.wb.save('../网易.xlsx')
print('网易数据成功保存!')
数据清洗
我们在此使用pandas对数据进行读取然后去重复和去除空值处理。
随机抽取五条数据展示如下:
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.max_rows', None) # 显示完整的行
pd.set_option('display.expand_frame_repr', False) # 设置不折叠数据
# 读取数据
rcv_data = pd.read_excel('../网易.xlsx')
# 删除重复记录和缺失值
rcv_data = rcv_data.drop_duplicates()
rcv_data = rcv_data.dropna()
# 抽样展示
print(rcv_data.sample(5))
'''
用户名称 会员等级 手机评分 评论时间 手机颜色 手机内存 评论
7 赵****豪 5 5 2021-03-05 黑色 128G 没买2天又便宜了
42 用****4 5 5 2021-06-23 返红包黑色 128G 手机非常好用,老婆很喜欢
268 独****息 6 5 2021-06-04 返红包绿色 256G 发货很快,第二天就到了
144 1****5 5 5 2021-02-27 黑色 128G 没啥可说的 好
97 用****4 5 5 2021-06-05 返红包白色 128G 发货快,物流也给力,包装保护的好,正品没问题
'''词云可视化
词云图展示如下:看来Iphone12依旧还是很香的,虽然13出来了
但是依旧值得入手!



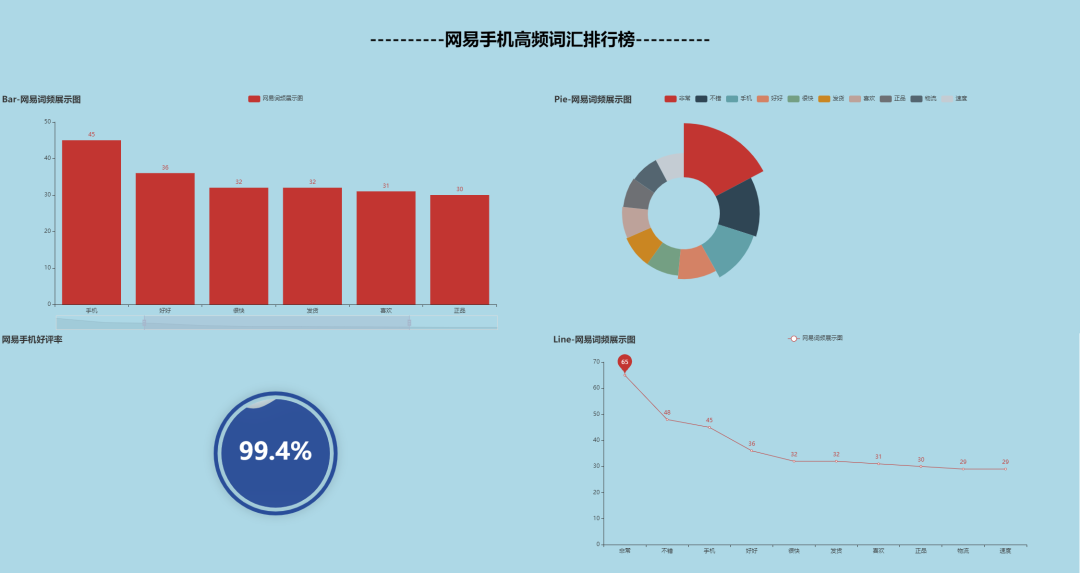
词频可视化
# 词频设置
all_words = [word for word in result.split(' ') if len(word) > 1 and word not in stop_words]
wordcount = Counter(all_words).most_common(10)
'''
('非常', '不错', '手机', '好好', '很快', '发货', '喜欢', '正品', '物流', '速度')
(65, 48, 45, 36, 32, 32, 31, 30, 29, 29)
'''
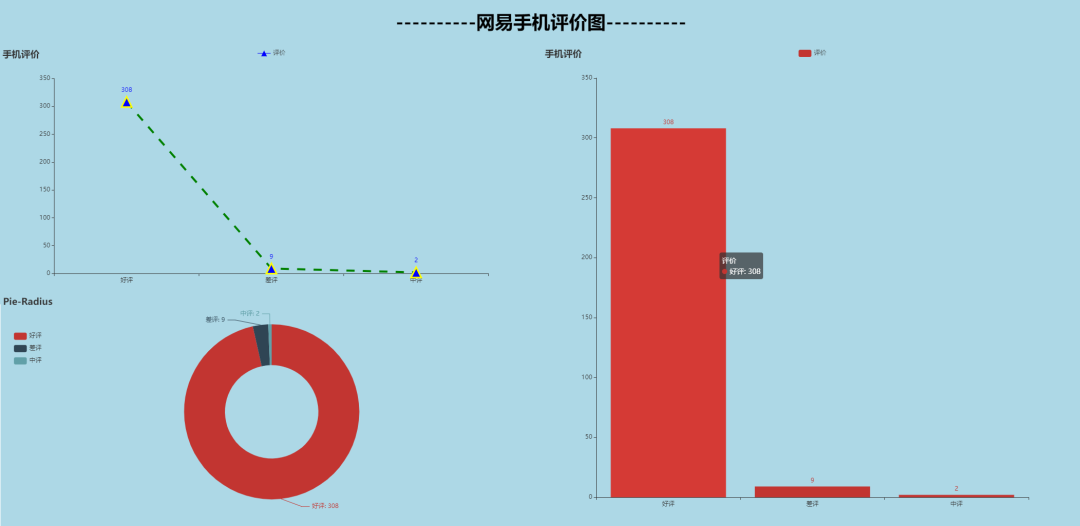
评分可视化
我们使用pandas提取手机评分数据以及频率,数据可视化展示如下:
从图中可以非常直观的看出苹果12的受欢迎程度。
# 划分价格区间
rcv_data['手机评分'] = pd.cut(rcv_data['手机评分'], [0, 1, 2, 5], labels=['差评', '中评', '好评'])
# 统计数量
stars = rcv_data['手机评分'].value_counts()
stars1 = stars.index.tolist() # 人气值分类
stars2 = stars.tolist() # 人气值分类对应数量
'''
['好评', '差评', '中评']
[308, 9, 2]
'''
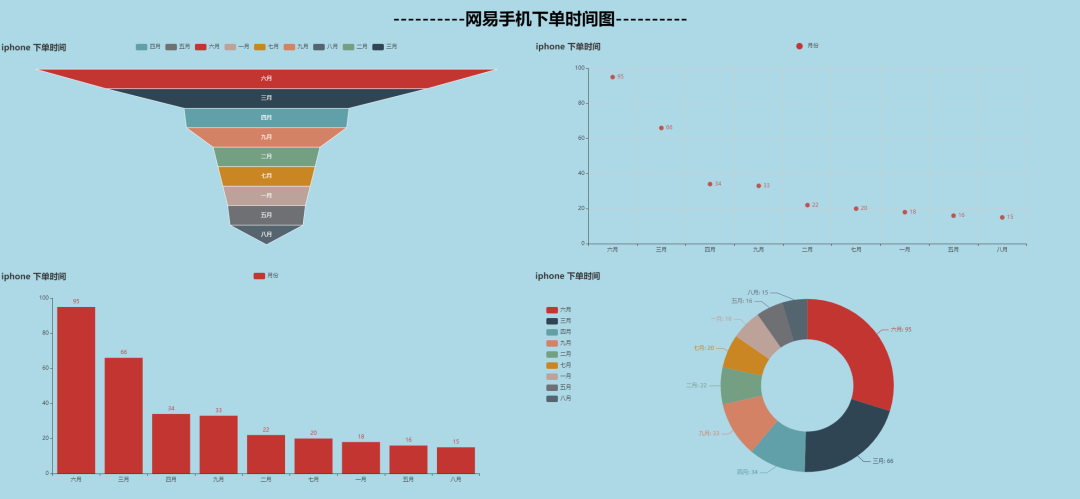
购机时间可视化
# 提取时间月份
rcv_data['评论时间'] = rcv_data['评论时间'].map(lambda x: x.split('-')[1])
rcv_data['评论时间'] = pd.cut(rcv_data['评论时间'], ['00', '01', '02', '03', '04', '05', '06', '07', '08', '09'], labels=['一月', '二月', '三月', '四月', '五月', '六月', '七月', '八月', '九月'])
# 统计数量
dates = rcv_data['评论时间'].value_counts()
dates1 = dates.index.tolist() # 月份分类
dates2 = dates.tolist() # 月份分类对应数量
'''
['六月', '三月', '四月', '九月', '二月', '七月', '一月', '五月', '八月']
[95, 66, 34, 33, 22, 20, 18, 16, 15]
'''从图中可以很直观的看到大家的下单日期大多集中在六月份
年终奖6月发吗
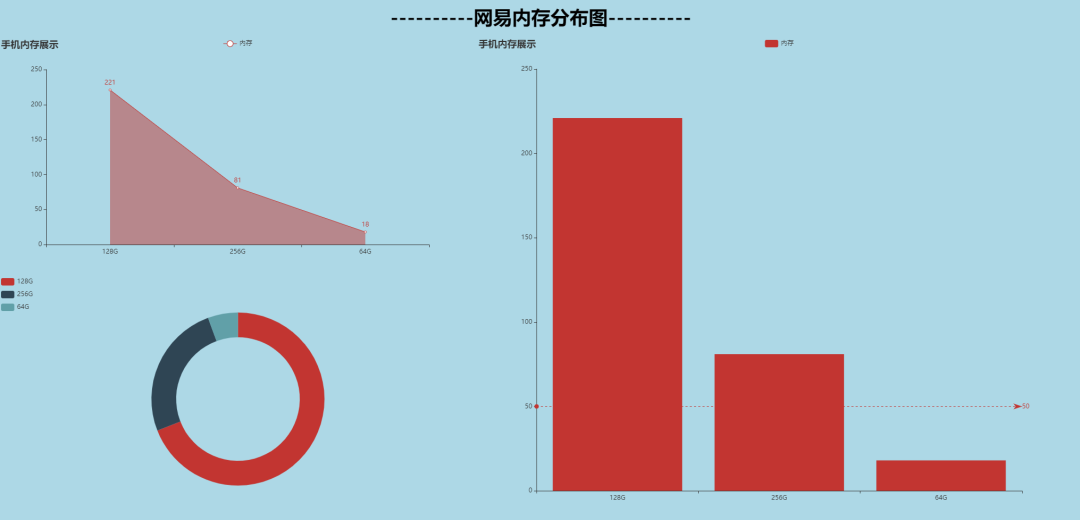
内存大小可视化
接下来我们对手机内存进行可视化分析,看看大家喜欢的内存是多大?
storage = rcv_data['手机内存'].value_counts()
storage1 = storage.index.tolist() # 内存种类
storage2 = storage.tolist() # 内存种类对应数量
'''
['128G', '256G', '64G']
[221, 81, 18]
'''64太小,256浪费
128G才是真爱啊!
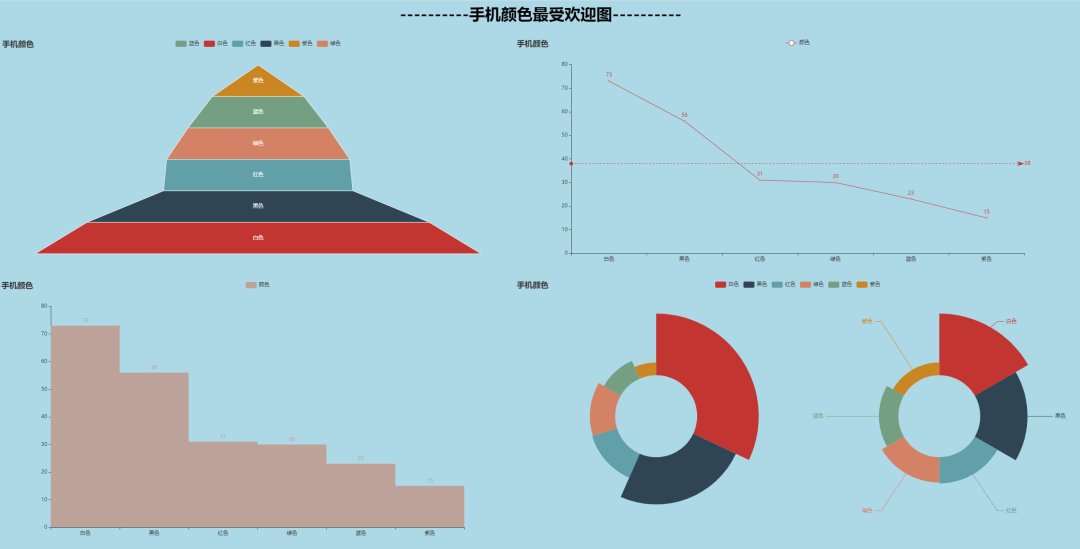
手机颜色可视化
# 颜色分布
rcv_datas = rcv_data[rcv_data['手机颜色'].str.len()==2]
colors = rcv_datas['手机颜色'].value_counts()
colors1 = colors.index.tolist() # 内存种类
colors2 = colors.tolist() # 内存种类对应数量
'''
['白色', '黑色', '红色', '绿色', '蓝色', '紫色']
[73, 56, 31, 30, 23, 15]
'''
推荐阅读
评论