
广告行业中那些趣事系列5:BERT实战多标签标注模型(附github源码)

摘要:之前广告行业中那些趣事系列2:BERT实战NLP文本分类任务(附github源码),我们通过BERT构建了二分类器。这里根据实际项目需要使用BERT构建多标签标注模型,可通过一个模型识别多类标签,极大提升建模效率。实际项目中会根据业务需要同时使用二分类器和多标签标注模型完成文本识别任务。
通过本篇学习,小伙伴们可以使用BERT模型来解决多标签标注任务。对数据挖掘、数据分析和自然语言处理感兴趣的小伙伴可以多多关注。
目录
01 多标签标注任务背景介绍
02 多标签标注任务VS二分类任务
03 BERT构建多标签标注模型实战
01 多标签标注任务背景介绍
之前讲过BERT构建二分类器的项目实战,我们需要识别用户的搜索是否对传奇游戏感兴趣。实际项目中我们的兴趣类目体系非常复杂,并且有严格的层级结构。假如我们现在有个类目体系如下:
游戏
传奇游戏
消除游戏
魔幻游戏
汽车
明星
理财
通常情况下用户的搜索不仅仅对一个标签有兴趣,可能同时对多个标签感兴趣,或者都没有兴趣,仅仅是无效的搜索。这种情况下如果仅仅使用二分类器工作量异常繁多。如果我们有上百甚至上千个标签,我们是不是就需要上百甚至上千个二分类器?这显然不合理。
有些小伙伴说,那我们可以使用多分类器。对,使用多分类器可以很好的缓解这个问题。但是多分类器下一条数据只会划分到一类,各类之间是互斥的,还是无法解决用户的一条搜索可能对应多个标签的情况。我们需要的是多标签标注模型。
小结下,在复杂的兴趣类目体系中,用户的搜索可能同时对应多个兴趣标签,所以我们需要构建多标签标注模型。
02 多标签标注任务VS多分类任务
这里通过一张图来很好的说明多分类任务和多标签标注任务的区别和联系。注意二分类任务仅仅是多分类任务的一个特例。
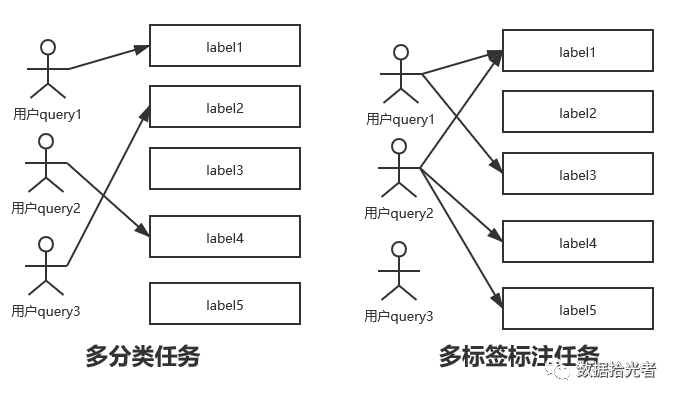
图1 多分类任务和多标签标注任务
多分类任务的特点是一条用户query只能属于一个标签。二分类是多分类任务的特例,如果我们现在用来识别用户query是不是属于传奇标签,这就是一个最简单的二分类任务。属于和不属于可以分别代表label1和label2。
多标签标注模型的特点则是一条用户query可能同时属于多个标签,也可能一个都不属于。举个例子来说“成龙大哥代言的一刀传奇好玩么”,可能既属于上面兴趣类目体系中的传奇游戏标签,还属于明星标签。
最通俗的理解二分类器、多分类器和多标签标注任务的方法可能是咱们小时候经常考试的试题了。二分类器可以对应咱们做的判断对错题,多分类器则对应单项选择题(候选项多于两个),而多标签标注模型则对应多项选择题,只是这里稍有区别是多标签标注模型可以都不选。小伙伴可以通过这个例子明白其中的区别和联系。
使用多标签标注模型的好处在于我们可以构建一个模型识别多个标签,不仅可以充分的利用数据源,而且可以提升建模效率。缺点在于多标签标注模型的各项评价指标可能不如二分类器那么好。这个其实非常好理解,让你去做判断对错题和多项选择题,一般人都是判断题做的更好点吧。
实际项目中一般是同时使用二分类器和多标签标注模型。对于原始的用户query可能通过一个三俗二分类器进行过滤。将数据中的三俗数据过滤之后能很好的提升标注数据质量。三俗数据对于兴趣建模本身没有什么意义。如果不进行过滤,会降低标注数据的效率。举例来说,现在需要标注10W的用户query数据。通常情况下10W数据里会掺杂20%以上的三俗数据。通过三俗二分类器我们可以提前将这2W多的数据过滤,然后只需要提交剩下的8W数据给标注团队,提升了20%以上的标注效率。
经过三俗分类器之后会构建一个基于一级类目的多标签标注模型,将用户query数据分类到各个一级类目中,最后就是根据不同的业务需求来进行文本识别了。这里一个小诀窍是对于一些多标签标注模型中某些效果不理想的标签,可以通过二分类器来重点识别,这样既可以享受到多标签标注模型的高效,还能享受到二分类器的高准确率。具体项目使用策略如下图所示:

图2 多标签标注模型和二分类器结合使用
03 BERT构建多标签标注模型实战
通过BERT模型构建多标签标注模型。下面是项目github链接:
https://github.com/wilsonlsm006/NLP_BERT_multi_label。也欢迎小伙伴们多多fork,多多关注我。
项目目录结构如下:

和二分类模型类似,多标签标注项目主要分成四个部分:
1. bert预训练模型
广告系列的第二篇已经讲过BERT是预训练+fine-tuning的二阶段模型。这里简单的提一句,预训练过程就相当于我们使用大量的文本训练语料,使得BERT模型学会很多语言学知识。而这部分就是学习语言学知识得到的相关参数。
之前二分类器的模型使用的是基于google的TensorFlow框架的keras_bert完成的二分类器。后面因为实际项目中慢慢往pytorch框架迁移,所以这个多标签标注模型是基于pytorch框架的fast_ai开发完成的。fast_ai类似keras_bert,采用非常简单的代码结构即可将BERT模型用于我们的NLP任务中。
Pytorch将BERT模型进行改造,各个版本的路径及下载地址如下:
bert-base-uncased https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz bert-large-uncased
https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased.tar.gz
bert-base-cased
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased.tar.gz
bert-base-multilingual
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual.tar.gz
bert-base-chinese
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz
因为实际项目中我们主要识别中文,所以选择最后一个“bert-base-chinese”作为我们的BERT预训练模型。下载完成解压之后会得到bert_config.json和pytorch_model.bin两个文件,然后加上之前的词表vocab.txt一起复制到我们的bert_model目录下。该过程即可完成。
2. 训练数据集
之前说过二分类器模型的数据输入格式是ocr,label样式的。ocr是用户query,也是我们需要识别的目标。Label则代表这句query是不是对某个标签感兴趣,取值为0或者1,1代表感兴趣,0代表没有兴趣。
多标签标注任务中,数据输入格式分成两部分,第一部分也是ocr,是我们需要识别的用户query。第二部分由多个字段组成,需要识别几个标签,就有几个字段。举例来说,我们现在需要识别用户的query是不是属于五个标签。那么现在我们训练集的格式就是ocr,lable1,label2,label3,label4,label5。实际数据举例如下:
“成龙大哥代言的一刀传奇好玩么?”,1,0,0,1,1。这条数据代表用户这条query同时属于标签1、标签4和标签5。
训练数据集分成训练集和测试集。模型训练中我们会用训练集去完成模型训练。然后用这个训练好的模型去测试集上检查模型的识别能力。这里训练集和测试集是完全互斥的,所以通过查看测试集的效果能一定程度上反映这个模型上线之后的识别能力。因为线上的数据和测试集的数据分布可能不同,所以测试集的效果可能和线上效果存在差异。
3. 模型代码及脚本
之前二分类器项目中只有代码。很多小伙伴私信反应说在训练、验证和测试过程中可能还要修改相关参数,比较麻烦。这里在多标签模型中通过shell脚本调用python代码能很好的解决这个问题。只要数据输入格式和上面讲的相同。针对不同的任务只需要修改shell脚本即可完成模型。
模型代码主要分成三部分:
multi_label_train.py:模型训练代码。
这里通过具体使用模型训练任务的脚本来详细说明模型训练代码的输入和输出。对应train_multi_tag.sh脚本:
输入:模型训练需要使用BERT预训练模型和训练集,所以需要配置的参数有训练数据的路径TRAIN_DATA和BERT预训练任务的路径BERT_MODEL_NAME
输出:模型训练完成之后会得到一个xxxx.pth文件,所以需要配置的参数有MODEL_SAVE_PATH。因为在模型训练阶段,可能多进行多次训练,所以需要存储不同的模型,这个通过配置LAB_FLAG来识别实验。
具体模型训练只需要在服务器下直接通过sh train_multi_tag.sh开始训练任务。
multi_label_validate.py:模型验证代码。
模型验证部分主要是为了验证模型的各项效果指标,我们主要使用准确率、精度、召回率、f1得分等来评估模型。
输入:模型验证需要上一个训练过程得到的模型和测试集。对应脚本中需要配置的参数有TEST_DATA和MODEL_LOAD_PATH
输出:模型输出为测试集上的预测数据以及模型的各项指标数据,对应脚本中的TEST_PREDICT_DATA和MODEL_EVALUATE_DATA。
multi_label_predict.py:模型预测代码。
当整个模型开发完成之后,会使用训练集和测试集同时作为新的训练集去训练模型,得到一个最终的模型。这个模型也是要拿到线上去跑的。
输入:这里需要最终得到的模型和线上需要真正预测的数据,对应脚本中的TEST_DATA和MODEL_LOAD_PATH。
输出:预测输出的部分就是线上真正预测的结果数据,对应脚本中TEST_PREDICT_DATA参数。
4. 训练完成得到的模型
这一部分就是上面训练过程的结果。我们需要使用这个训练好的模型去部署上线进行线上数据的预测。这里和之前二分类器有所不同,二分类器得到的是一个XX.hdf5文件,而多标签标注模型得到的是一个XX.pth文件。其他和之前讲过的二分类器类似,这里不再赘述。
总结下,我们通过项目实战完成一个多标签标注模型,从模型训练到模型验证,再到最后上线预测流程。模型通用性较强,我们只需要更改脚本代码即可迅速完成线上任务。
总结和预告
本篇从实际项目出发完成了一个多标签标注模型。实际文本分类任务中,我们会根据具体业务需要同时使用多标签标注模型和二分类器。由于NLP任务和传统的机器学习任务有所不同,我们不需要做过多的特征工程,但是对于文本语料的预处理非常重要。除此之外,样本的选择也很有技巧性。这里需要不断积累经验,才能根据实际的业务需要调整模型。
喜欢本类型文章的小伙伴可以关注我的微信公众号:数据拾光者。有任何干货我会首先发布在微信公众号,还会同步在知乎、头条、简书、csdn等平台。也欢迎小伙伴多交流。如果有问题,可以在微信公众号随时Q我哈。