前言
框架

数据应用

用户主动行为数据记录了用户在美团平台上不同的环节的各种行为,这些行为一方面用于候选集触发算法(在下一部分介绍)中的离线计算(主要是浏览、下单),另外一方面,这些行为代表的意图的强弱不同,因此在训练重排序模型时可以针对不同的行为设定不同的回归目标值,以更细地刻画用户的行为强弱程度。此外,用户对deal的这些行为还可以作为重排序模型的交叉特征,用于模型的离线训练和在线预测。
负反馈数据反映了当前的结果可能在某些方面不能满足用户的需求,因此在后续的候选集触发过程中需要考虑对特定的因素进行过滤或者降权,降低负面因素再次出现的几率,提高用户体验;同时在重排序的模型训练中,负反馈数据可以作为不可多得的负例参与模型训练,这些负例要比那些展示后未点击、未下单的样本显著的多。
用户画像是刻画用户属性的基础数据,其中有些是直接获取的原始数据,有些是经过挖掘的二次加工数据,这些属性一方面可以用于候选集触发过程中对deal进行加权或降权,另外一方面可以作为重排序模型中的用户维度特征。
通过对UGC数据的挖掘可以提取出一些关键词,然后使用这些关键词给deal打标签,用于deal的个性化展示。
策略触发
1. 协同过滤
清除作弊、刷单、代购等噪声数据。这些数据的存在会严重影响算法的效果,因此要在第一步的数据清洗中就将这些数据剔除。
合理选取训练数据。选取的训练数据的时间窗口不宜过长,当然也不能过短。具体的窗口期数值需要经过多次的实验来确定。同时可以考虑引入时间衰减,因为近期的用户行为更能反映用户接下来的行为动作。
user-based与item-based相结合。


2. location-based

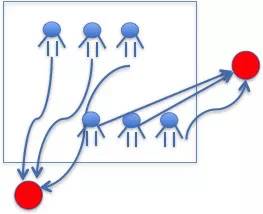
3. query-based
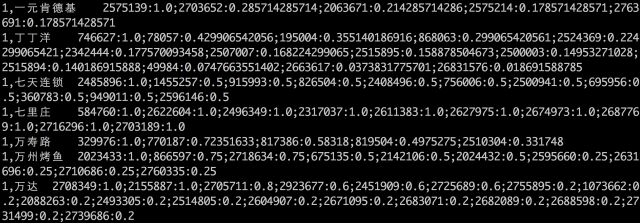
当用户再次请求时,根据用户对不同query的权重及query下不同deal的权重进行加权,取出权重最大的TopN进行推荐。
4. graph-based
候选集重排序
1. 模型
