
聊一聊“超大模型”
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


文 | 金雪锋
源 | 知乎
最近经常被问,你看“万亿的模型都出来了,你们训练的千亿模型是不是落伍了?”我想说:“虽然都叫超大模型,但是类型是不一样的,虽说每一类模型训出来都不容易,不过澄清一下概念还是必要的”。
大概盘算了一下,一年多来,业界发布了非常多的大模型,从去年OpenAI GPT-3 1750亿参数开始,到年初华为盘古大模型 1000亿,鹏程盘古-α 2000亿参数,Google switch transformer 1.6万亿;及近期的智源悟道2.0 1.75万亿参数 MoE,快手1.9万亿参数推荐精排模型,阿里达摩院M6 1万亿参数等;很多小伙伴看的是眼花缭乱,那究竟这些模型有没有差异?如果有差异,差异在哪里?
首先我想说这些模型都是基于Transformer结构,但是在模型扩展上有非常大的不同。
从计算角度看,我们可以把这些大模分成3类
稠密Transformer: OpenAI GPT-3,华为盘古/鹏程盘古α(MindSpore支撑);模型规模的扩展是全结构的扩容; 稀疏MoE结构Transformer: Google Switch Transformer,智源悟道2.0,阿里M6。一般来说是选择一个基础的稠密模型,通过MoE稀疏结构扩展FFN部分,以此来达成模型的扩容; 高维稀疏特征推荐模型: 快手推荐精排,我理解主要是推荐的高维稀疏特征Embedding需要超大参数;
推荐类模型是一个比较独立的计算特征网络,这个我们最后分析。其中相似性非常大的是稠密Transformer和稀疏MoE结构Transformer,下面我们以Google Switch Transformer来对比两者的差异。
下面两张图是Google Switch Transformer论文中和T5的对比,Switch Transformer是基于T5,通过MoE稀疏结构扩展。我们用Switch-Base作为这次分析对比基准。
Switch-Base是基于T5-Base的MoE稀疏扩展,模型参数规模比T5-Base大33倍,从计算角度看,内存开销是T5的33倍,算力开销和T5-Base一致。同时,我们拿Switch-Base和T5-Large做一个对比。Switch-Base参数规模是T5-Large的10倍,也就是说内存开销是T5的10倍,算力开销是T5-Large的29%;
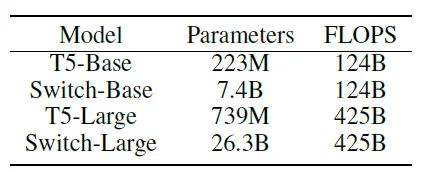
从下面这个表格的下游任务对比来看,在同样的算力开销下,Switch-Base的效果比T5-Base整体上要好,这个优势是通过33倍的内存开销换取的;但是同时,Switch-Base在参数量比T5-Large大了10倍的情况下,效果比T5-Large要差一些。
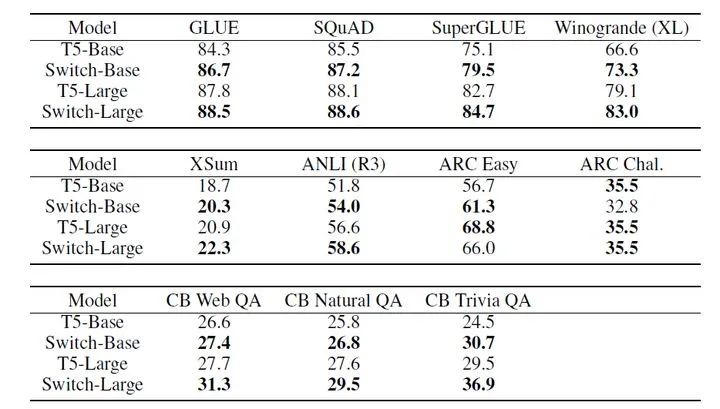
所以我们不能单纯从参数规模来衡量一个网络的效果,需要通过参数量和计算量来综合对比,需要我们探索一种新的指标,综合考虑内存和算力开销来评估一个模型。
另外,从Switch Transformer 1.6万亿模型来看,其计算量只有稠密T5 130亿参数的10%,参数量是其100倍;如果从每个参数消耗的算力来计算,1.6万亿稀疏模型只是稠密的千分之一,即1.6万亿参数的Switch Transformer的计算量相当于10亿参数的稠密的Transformer。
那么从训练角度来看,MoE大模型的计算量较少,重点是做好模型参数的切分,从switch transformer的实践看,主要使用数据并行+MoE并行的组合;而稠密的Transformer计算和通信量非常大,所以盘古-α需要在2K张卡上进行训练,同时也需要复杂的pipeline并行/算子级模型并行/数据并行等并行切分策略来确保2k集群的算力能被充分利用,个人认为训练挑战更大。
从推理的角度看,MoE的模型参数量非常大,我觉得可能需要通过蒸馏/量化等手段进行压缩才更适合使用,挑战很大,也是MoE模型推广面临的障碍。

快手的1.9万亿参数网络,是一种高维稀疏推荐网络,拿Google Wide&Deep来对比更为恰当。快手推荐网络的优化,应该是在后面的DNN层用了Transformer结构,而模型头部的Embedding部分还是保持和传统深度学习推荐网络类似(没有找到相关论文,不对请指正)。这类型网络,为了表达高维稀疏特征,会有一个超级大的Embedding,参数主要是集中在头部的特征Embedding部分。这种类型网络的训练方式和前面讲的完全不同,核心技术是Embedding的模型并行,以及CPU/NPU的协同计算和存储。华为诺亚实验室在今年SIGIR 2021上发表的“ScaleFreeCTR: MixCache-based Distributed Training System for CTR Models with Huge Embedding Table”是目前一种最好的训练方案之一,也将会在MindSpore上开源。这里就不再展开分析。
除了Transformer这种算法结构外,还是有CNN类的超大模型,也可以分成两类,这两类模型也是稠密的,参数量和计算量是成正比。
超大分类层:超大规模人脸识别、图像分类网络,其典型特征是CNN特征抽取之后的FC分类层超级大。例如千万ID的人脸识别,FC层的参数规模就达到了50亿。 超大Activation:遥感和超高分辨率图像处理,这类网络参数量不大,和传统CNN的参数量类似,在百M级别。但是这种模型的输入数据以及计算过程中的Activation非常大。以遥感为例,平均输入样本的分辨率就有[30000, 30000, 4],一个样本就有3.6GB,大的图像有10GB以上,中间层Activation也是GB级别的大小。
所以,总的来说在NLP、多模态、推荐、图像处理领域都有大模型,目前业界比较火热讨论的主要是基于Transformer+MoE结构的NLP及多模态大模型,我们期望通过这篇文章,让小伙伴能了解这些模型在计算上的差异。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!