
SQL数据库性能胯了,换 SSD硬盘就能解决问题?
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

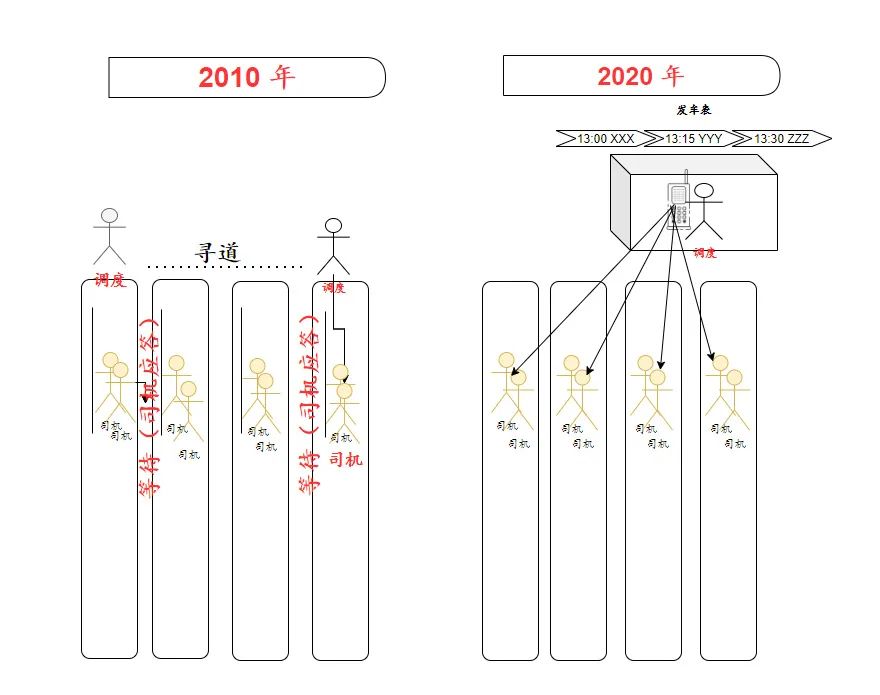
2010年,上海张江,传奇广场。
这里汇集了各路公交车,是张江男女必争之地。打工人最怕的是什么,不是996,不是007,最怕挤公交。
背着5斤重的Dell, 顶着烈日,狂风,暴雨,满怀希望冲向车站,换来的却是,屡次被无情抛弃,这种感觉,谁经历,谁泪目。
BMW, Bus + Metro + Walk 这种通勤方式,贯穿着张江男女的 30岁!
“让一让,排好队!” 车站调度员每次总要对落下的我们补上一句。语气略有生硬,但嗓门绝对让每个幻想插队的人,都听得到!
这个车站不大,总共有 4 个车道,停歇了 7-8路车。618,636,张江1路,张南专线,张江环路,孙桥1路,等等
调度员拿着硬板本,按时走过 4个车道,招呼该发车的司机出发,并叮嘱下一班次车准备。每次看到有调度员过来,一些略显颓废的男女,立刻就来了精神。因为占座,在这里也是门学问。
有时,该发车的车道上,没有找到司机,调度员还会大骂一声,气哄哄跑去下一车道招呼其他司机。
现今,基本上已经看不到调度员的身影了,即使看到,也是他偶尔出来抽根烟。随手还带着对讲机。
没错,现在的调度口令,不需要口口相传,对讲机一开,司机就跳上车了。调度员手里的硬板本,也换成了电子公告牌,就像华泰证券交易所的红绿看板一样,哪个车道,下一班发什么车,走马灯似的亮着。
扯远了,拉回来,你们没有走错片场,我不是在写小说!
上面这个转变,看似是电子信息化转型,实际上也胜似机械硬盘过度到SSD(固态硬盘)。
 (摘自网络)
(摘自网络)
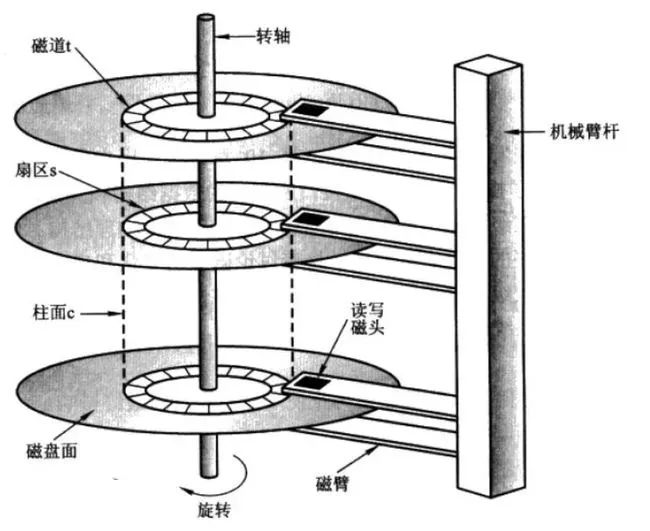
这是机械硬盘的构造图。
磁盘从里到外,分出很多磁道。磁道上挨个排满了扇区,每个扇区的存储空间固定。
磁头围绕着磁道转一圈,该磁道上所有的扇区数据就会被读到内存里。这样的读叫做顺序读(顺序IO)
如果一个磁道把同一张表的数据都存储起来,这样的顺序读,效率是最高的,只需一圈,读到所有的数据。
但事情并不那么简单。首先,数据的写入,是无序的。比如一张表有100万条数据,这100万条数据,并不是连续地写入,而是每天写一点或者每过一段时间写一点。写入的同时,还会有表B,表C的数据,挨着表A的某些数据,一起写入到相邻的扇区中
那么,同一个磁道上,就会出现既有表A的数据,还有表B,表C的数据。这样磁道上的数据,就会有了断层。表A的数据自然也就不会连续存在一个磁道上
有可能磁道1存上那么2万条,磁道2存上那么10万条,磁道3存上那么5万条,零零散散分布在几十条不同的磁道上
所以,与理论上完美的顺序读,不一样的是,实际中,大部分表的数据是随机读(随机IO)
完全读取表A 100万的数据,可能需要在几十条不同磁道间来回切换。而读取时,把其他表数据读取出来,貌似做的都是无用功。
因此,传统的优化,有一个方法就是磁盘碎片整理,目的就是提高顺序读的机会。当然,建立索引也是提高顺序读的好方法。但OLTP系统中,充满了随机写,索引也必须进行碎片整理。
以上是传统磁盘的工作方式,也列举了对数据库操作的影响。那么SSD的出现,又对数据库的优化产生了哪些影响呢?
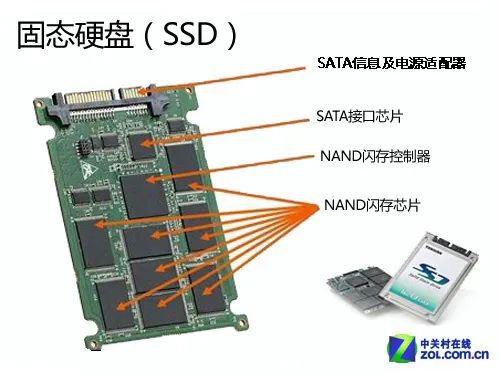
同样,先要讲下 SSD 的结构,正是由于这个结构才对数据库产生了深远的影响,而且这个影响不仅仅有正面的,还有负面的。
SSD不再是简单的一个存储介质,而是一整套微小的系统。包含了内置的芯片,缓存还有存储介质。
 (摘自网络)
(摘自网络)
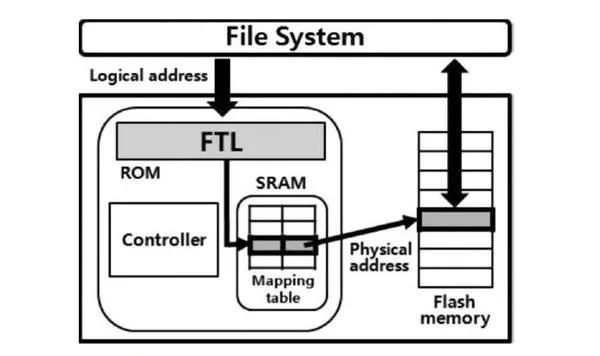
当操作系统发送读写命令时,SSD就像是另外一台计算机,判断内存是否有缓存,根据FTL提供的映射表,从介质上读取/写入数据。
这些组件里最有意思的是 FTL(Flash Translation Layer), 即闪存译层。它的主要功能是提供一份映射表,从闪存(Flash Memory)的物理地址映射到逻辑地址(Logical Block Address)
那么为什么SSD的FTL这个组件能力那么强,它对比传统的磁盘到底快在哪里?
再来回忆下,传统的磁盘,一次随机读,耗时较长的两个步骤,一是寻道;二是等待
寻道,即寻找到特定数据的磁道;
等待,在磁头定位到磁道后,等待磁盘将扇区旋转移动到磁头下,这个延迟时间称之为等待时间。
正是由于这两个限定因素,导致机械磁盘的效率,顶配了也就那么高了。
那么SSD的电气化闪存,为什么就会比机械磁盘高那么多呢?
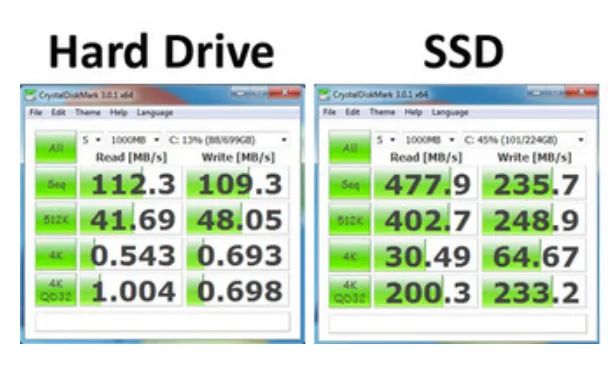
这个原理,开头的小故事,已经说得很明白了。
调度员一个个车道走过来,这是寻道,万一哪个道,到点了,但还没有车辆就绪,就得跨道,找下一个可以发车的道;走到当时可以发车的车道,呼叫可以发车的司机,叮嘱司机可以发车了,这是旋转磁盘时的必要等待。
这一来一回,中间出点叉子,都会无数的等待时间。所以经常晚点,当时那叫一个痛苦。
感谢电子化时代的到来。现在的发车远比那时简单高效。
每个司机都配备对讲机,时间一到,调度根据排班(FTL)呼叫司机发车,省掉了寻道和等待时间(都靠人工)。调度员借用电子信息手段,瞬间就能传达发车指令。
但是,SSD就全是优点吗,绝对不是。它有个巨大的缺陷,就是写入放大。
这个缺陷和数据库的预读能力,其实有些类似。数据库的读取,一次读取并不是一条一条的读数据,而是一页乃至一个数据区的读。明明只要一条数据,对不起,存储引擎会读取上百条数据给你
所以有时看到数据库内存使用量极大,总想着给它加点内存,其实完全没必要。它就是一贪嘴的小鬼,给多少就吃多少,不会嫌多。
SSD 也有类似的机理,不过不是在读取上,而是在写入中。读取可以完全做到一个页一个页的读,但写入就有分歧了。
当一块新的SSD硬盘拿过来,开始写入数据时,很快。见缝插针,哪儿凉快就哪儿呆着。不用思考。但是一旦SSD写完了,需要改写数据时,麻烦就来了。
它的改写原理是读取一个数据块的数据,而不是一页数据。这一个块上的数据,可能包含了几十页的数据,而且这些数据都不需要修改。等到这些数据读到内存后,就选择需要修改的数据,逐条修改,然后写回闪存。
写回闪存时,最大的延迟在于,需要把原先的那些读取的数据页都擦除,然后再写入。
这种情况,称之为“写入放大”
所以你家的SSD是不是等过了一段时间,发现明显的速度慢了?就是这个理,在等待垃圾块(脏块)的回收。
像这种情况,存在于早期的SSD中,那时,SSD确实不适合用来做日志盘,只能用来做无伤大雅的快盘。后来优化了FTL算法,比如进行了碎片整理,垃圾回收,并且容量也日渐扩大,慢慢SSD的应用场景也就多起来了
在OLAP领域,也就是数据分析,数据仓库和报表系统中,SSD的应用相当广泛。这类应用写入次数较少,但是读取的吞吐量极大。
有人说,SSD 的写入放大缺陷,不适合用来存储 redo log,其实也不是那么全面。有些 redo log不大,而 SSD 现在的容量极大,一次性写完 SSD 而引起性能抖动的概率并不大。而且有了FTL的优化,SSD完全有能力在日志写满前,就开始做垃圾回收和碎片整理。
日志文件的访问(主要是写入),通常可以看做是在环形跑道上跑马拉松。一圈跑下来,运动员丢弃的水瓶,补给堆满了跑道。为了可以让运动员顺利跑第二圈,第三圈,必须把这些水瓶等杂物清理干净,越早处理,对运动员就越有利,无感知最好
SSD也一样,在装有 redo log 的SSD写满之前,就对SSD做闪存块的整理,把空间都让出来,才能让数据写入更快
那么 SSD 是不是就一定比传统的存储系统优越呢,其实也不一定。
比如组RAID 磁盘阵列,拥有的读写能力就不比 SSD 差。
通过表分区,将数据打散,放在不同的硬盘上,这样读取数据,就能有效利用并行。
拿 SQL Server 来举例:
c 盘:操作系统 D 盘:SQL Server 数据文件 E 盘:日志文件 F 盘:SQL Server 数据文件 G 盘:tempdb 文件
其中,D和F盘做了 RAID 10, 当100G的数据表做了分区,将其中的时间戳,按照奇偶年,分别存储在 D/F盘的数据文件中。
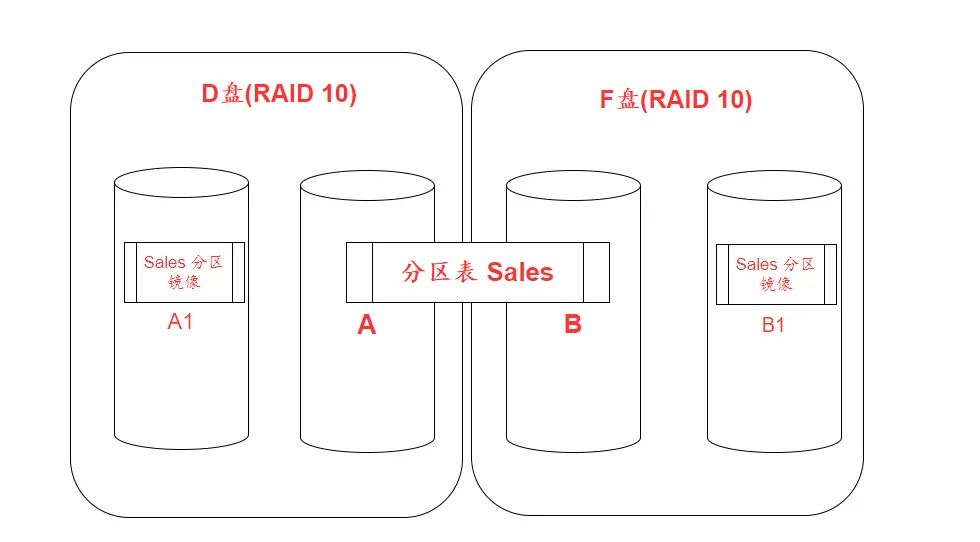
这样,当需要查询连续两年的数据,就可以充分发挥D/F盘并行查询的效率
只要成本可控,随着数据盘的增多,分区可以打得更散,并行的速度就越快。这对于 SSD 来说,成本上是不过关的
用SSD替换机械硬盘,现阶段有好处,但瓶颈也不少。更多应用,还是要在实际中做出一种平衡。
往期精彩: