
2020年,语义分割可以在哪些方向进行研究并取得突破?
编辑:深度学习与计算机视觉
语义分割(Semantic Segmentation)说到底还是为了让人工智体更好的去理解场景(Scene Understanding)。什么是理解场景?当我们在说让一个智体去理解场景的时候,我们究竟在讨论什么?这其中包含很多,场景中物体的语义,属性,场景与物体之间的相对关系,场景中人与物体的交互关系,等等。说实话很难用一句话来概括,很多研究工作往往也都是在有限的任务范围下给出了机器人理解其所视场景的定义。那么为什么语义分割对于场景理解来说这么重要?因为不管怎么说,场景理解中有些要素是绕不开的,例如目标物体的语义, 目标物体的坐标。当我们真正要应用场景理解的技术到实际生活中时,这两个点几乎是必需的。而语义分割恰好能够同时提供这两种重要的信息。
传统的2D图像语义分割技术经过众多研究人员几年时间不停的迭代,已经发展到了一个提升相当困难的时期。同时这也意味着这项技术已经渐渐的趋于成熟。但传统的2D分割还是有一定的局限性,比如我们很难从2D图像中直接获知物体的空间位置,以及其在整体空间中的布局。这很直观,因为2D图像捅破天也只有2D信息,想知道整体空间的位置信息还是需要更多的3D信息。事实上,这件事已经有相当一部分人在做了。为了让单纯的2D图像(RGB)具有深度信息从而转变成RGB-D,我们发展了深度估计(Depth Estimation);为了让RGB-D变成真正有用的3D信息,我们发展了三维重建(3D Reconstruction)技术;为了得到整个场景的三维点云,我们发展了SLAM;为了得到场景中点云的语义信息,我们又发展了基于点云的语义分割技术。这一整套流程下来,我们可以让机器人从单纯的2D图像出发,得到空间中物体三维的坐标,语义,和边界信息。这一连串的思路十分完备,也非常本质。然而3D数据往往又面临着极为昂贵的计算成本与数据采集和标注的成本,不像2D数据有一台手机就能采集,对于标注人员来说也不如2D图像的标注来的那么直观。
那么我们能不能依旧基于2D图像,让机器人对于整个空间中物体的坐标有更好的感知?
答案是肯定的。其实在相当一部分实际任务中,得到物体准确的3D坐标是一件精确过头的事,就好比能用16位浮点数解决的任务我偏偏要用32位,可以但不是必要。很多时候我们需要3D坐标只是因为这是一个清晰的,看得见摸得着的,具体的数值目标。但再好的数值目标,跟实际使用体验的关联性也不是百分百对应的。就好像损失函数低不一定代表最后的准确率就高,数值准确率高不一定代表实际的人眼效果就好。扯远了,话说回来,基于以上我所说的,我们在求解准确的3D信息所需要的代价与传统的2D分割的局限之间找到了一个平衡点,也就是利用俯视语义图(Top-down-view Semantic Map)来感知周围环境物体的方位与布局。
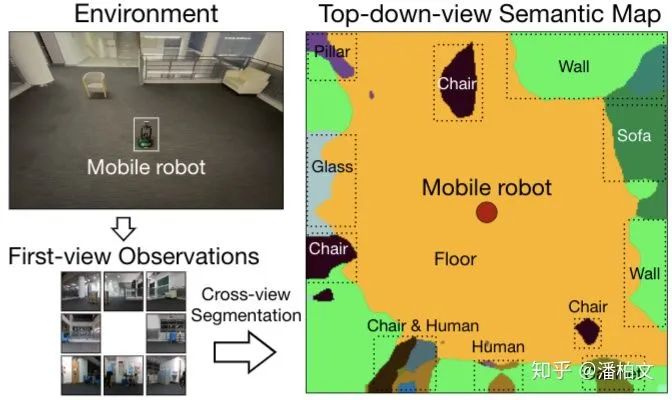
我们把从第一视角的2D图像(First-view Observation)得到俯视语义图(Top-down-view Semantic Map)的过程称作跨视角语义分割(Cross-view Semantic Segmentation)。跨视角语义分割与传统2D语义分割的区别在于我们得到的不再是一张与原图逐像素对应的语义图,而是一张俯视视角下看到的周围环境的语义图。另外对于模型的输入来说,跨视角语义分割的输入从2D语义分割的一张RGB图变成了多张第一视角的任意模态的图(RGB,Semantic Mask,Depth)。
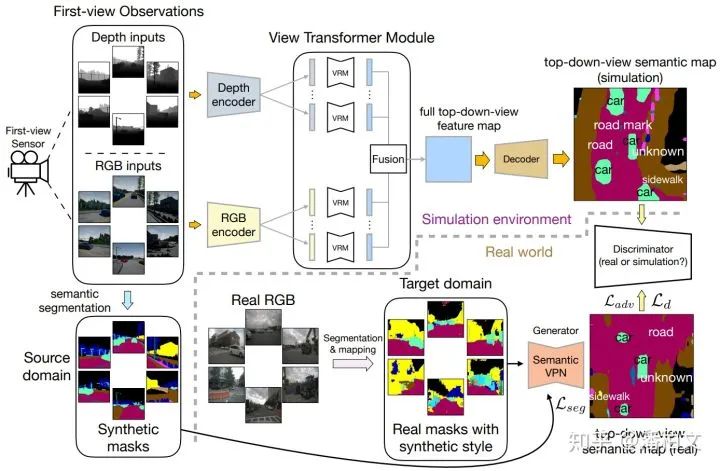
由于这是一个新问题,现有的语义分割数据集并不支持我们去训练这样一个跨视角语义分割的模型。我们于是将目光投向了一些模拟仿真环境(Simulated Environment),例如House3D,Gibson Environment,Matterport3D。我们从这些模拟仿真环境中提取第一视角的图像以及对应的俯视语义图,从而完成训练过程。然而仿真环境中提取的图像与真实世界的图像还是有着很大的差别,因此我们在部署我们的模型到真实世界的时候还做了一步半监督的域适应(Domain Adaptation)。我们利用这样一个仿真环境+半监督域适应的流程暂时缓解了没有真实数据的问题。但是在未来如果我们需要对这个方向进行长足的发展,真实世界的数据仍然是不可或缺的。
从模型结构的角度来看,我们的实验发现,由于不存在像素级的对应关系,传统2D语义分割的模型结构并不能直接套用在我们跨视角语义分割的任务上。然而为了能够继承这些极为优秀的,凝结了许多前人智慧的传统2D语义分割的模型结构,我们提出了一种视角转换模块(View Transformer Module)插入到编码器(Encoder)和解码器(Decoder)之间。这种视角转换模块保持了原来的模型结构,从而在跨视角语义分割任务上更好的发挥作用。
https://www.zhihu.com/question/376432270/answer/1301138347
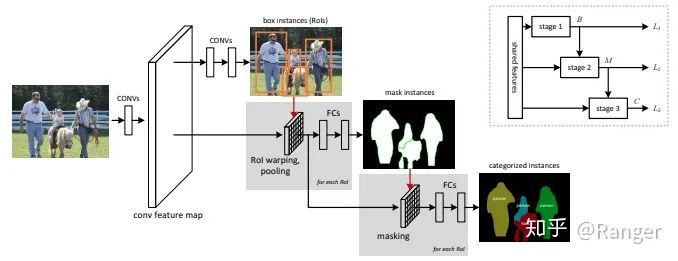
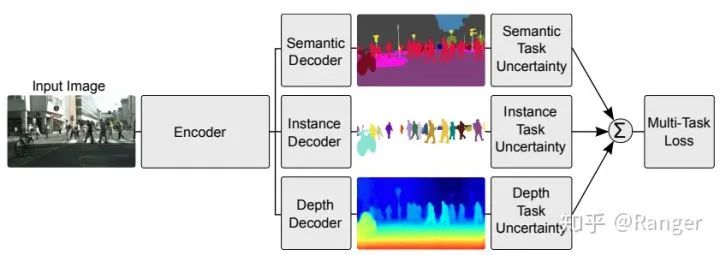
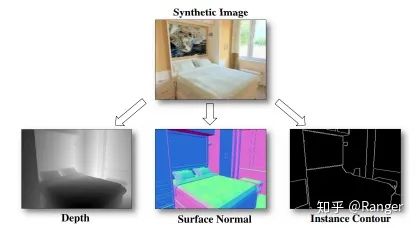
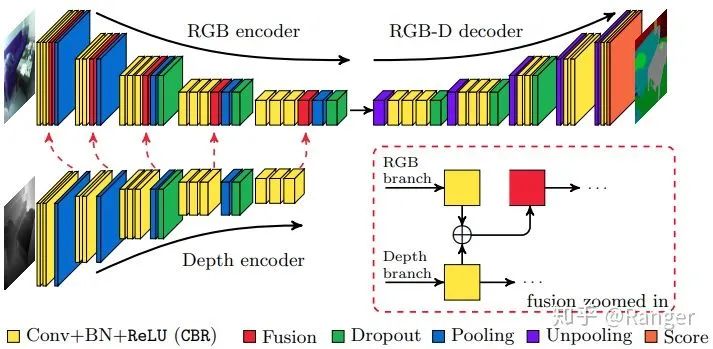
2.利用data-fusion来优化semantic segmentation,例如:
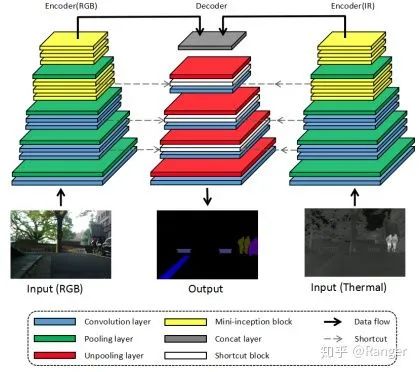


https://www.zhihu.com/question/376432270/answer/1301176481
其实是因为前面深度学习这一波走的太顺了,尤其CNN出来,然后gan没过多少年就出来了,其实你看看前面大概八十年的ai历史,大部分时候图像处理走的都很慢,那才是常态。
反正前路还是有点难的。
作者:Jowey https://www.zhihu.com/question/376432270/answer/1561921142
end
往期精彩: